







Decode:
- 在流水线中,指令解码(decode)阶段的任务是将指令中携带的信息提取出来,处理器使用这些信息控制后续的流水线来执行这条指令。
- 指令集的复杂程度直接决定了这部分任务的工作量;
- 对于CISC指令集,例如x86来说,指令的长度是不固定的,解码阶段首先需要分辨指令的边界,这样才能够找到有效的指令,而且x86指令的寻址方式也很复杂,这也增加了解码的难度。
- 而对于RISC指令集来说,指令的长度是固定的,例如MIPS指令和ARM指令的长度都是32位,这样很容易将指令分辨出来,
- 而且RISC处理器的寻址方式相对也是比较简单的,这些因素都导致RISC处理器的解码难度要远低于CISC处理器,因此RISC处理器在成本和功耗方面天生就比CISC处理器占据优势。
- 影响处理器解码复杂度的还有一个因素,那就是每周期可以解码的指令个数,由于每条指令都需要一个完整的解码电路,所以对于一个每周期可以解码n条指令的超标量处理器来说,就需要n个解码电路,这样当然也就增加了解码电路的复杂度
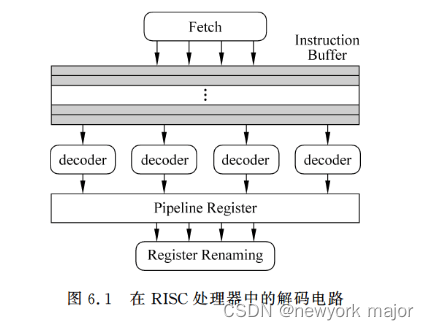
- instruction buffer;
⭕存在的原因:
1. 为了减少I-cache miss所带来的影响,可以看成一个储备粮仓;
2. 有些指令比较复杂或者特殊,没有办法在一个cycle内进行decode处理;(乘累加指令,会拆分成两条普通指令,这就可能超过处理器decode能力(4+1=5 > decode number))
⭕ 解决方式:每个cycle从I-cache中取出超过可以decode的指令条数;
⭕ 怎么存放:多余的指令放在这个IB里面,I-cache miss时,可以用这个里面存放的指令;
⭕ 存在形式: 本质上是一个FIFO,仍然保持着指令的PO顺序,这样在解码时,仍然可以按照程序指定的顺序进行解码;
2. decode 阶段需要处理的事情----3个what;
- What type,例如指令是算术指令,访问存储器的指令还是分支指令等;
- What operation,例如当指令是算术指令时进行何种算术运算,当指令是分支指令时它的条件是什么样的,当指令是访问存储器的指令时是 load 指令还是 store指令等;
- What resource,例如对于算术指令来说,源寄存器和目的寄存器是哪些,指令中是否有立即数等。
3. 指令的特殊处理;
有些指令,需要在解码阶段进行特殊的处理,例如,将复杂指令,转化成多条简单的指令;

Intel对于拆分指令的条数,超过4条uops的X86指令,则不再进行如表上的拆分,而是使用ucode-ROM来存储这些复杂的指令对应的uops;
下面介绍几种特殊指令在超标量中的处理:
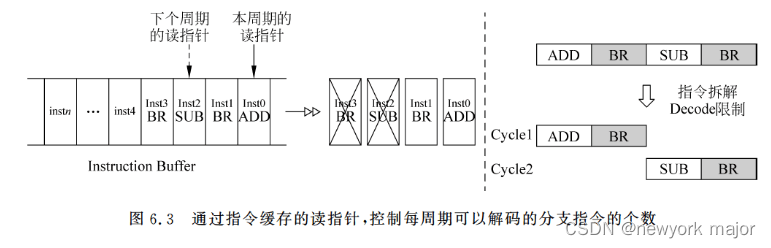
- 分支指令
为什么需要特殊处理?因为为了减少分支编号分配电路的复杂度,需要限制每周期进行解码的分支指令的个数;
解决方式:
1. 限制decode每个周期内,处理的分支指令的条数,例如,限制为1;
2. 不做限制,但是在decode阶段,本周期内,遇到分支指令后,就不对分支指令之后的指令进行解码,而是将其下放到下一个周期;
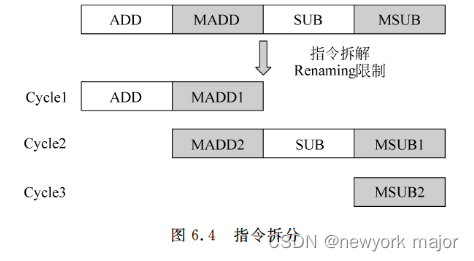
- 乘累加/乘法指令(MIPS指令为例子)
MIPS指令中,乘法/乘累加是一类特殊的指令,因为他们有两个目的寄存器(Hi/Lo),这两个寄存器并不属于通用寄存器;这样,在重命名的时候,就需要给两个目的寄存器重命名,这给rename 电路带来了麻烦;
而且,如果把这些指令直接放到ROB中,因为有两个目的寄存器,那么ROB的面积也会增加;
并且,rename是针对通用寄存器进行的,这种非通用的,也需要进行特殊处理;
因此,处理方式如下:
1. 将HI/LO分配为MIPS处理器的第33/34寄存器;
2. 将乘法/乘累加指令,拆分成2条指令;占用两个ROBen entry;
3. 对issue queue进行特殊处理,将乘法/乘累加指令,使用一个FU进行运算,这个FU是特殊的,他有4个源操作数,两个目的操作数;发射队列还需要将两条拆分的指令进行融合,变成一条完整的指令;
带来的问题:
因为指令进行了拆分,因此,会造成指令的实际个数,超过issue num的情况;
解决方式:
1. 方式一,decode之后,rename之前,增加一级缓存,拆分出来的指令和正常不拆分的指令,都放到这个buffer中进行暂存,不好之处就是,会带来额外的面积开销;
2. 方式二,同分支指令,限制每个cycle可以家吗的指令个数,一旦在decode阶段发现乘累加指令,则只有该指令拆分出来的第一条指令,及其之前的指令可以进行解码,拆分后的第二条指令,以及之后的指令放到下一个cycle处理;
- 前/后变址指令的处理
考虑这样一条指令:
![]()
上面的一条指令执行了两个操作,即:
1. 从存储器中将地址[R1+4]中的数据放到寄存器R2中,
2. 并且把用作地址的寄存器R1更新为R1+4 的值。
此时的目的寄存器不只是存放结果数据的寄存器R2,用来存放地址的寄存器R1也是目的寄存器,需要在load指令执行完的时候改变寄存器 R1的值,这样就相当于load指令有两个目的寄存器,而两个目的寄存器会给寄存器重命名以及后续的过程(例如唤醒)带来麻烦,因此在超标量处理器实现时,仍旧会在处理器内部将这个复杂的load指令拆成两条普通的指令。
解决方式:拆分;

这会导致拆分出来的指令个数,同样超过issue num条,解决方式同上;
- LDM/STM指令的处理
ARM中,STM指令可以将多个寄存器的内容保存在存储器中的一片连续空间内,LDM指令可以将存储器中一片连续地址空间上的数据加载到多个寄存器中。
这种指令处理方式更加麻烦,好在RISCV中不存在此种类型指令,此处略过;















 7674
7674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









