







本文版本选自spark 2.1.0
写这篇文章之前已阅读过官网api,算法本身自认为自己手动写,应该可以搞定(进一步优化不提);但是官网却看的我迷迷糊糊的,参数选择和结果获取,描述不够清晰,写这篇文字的目的就是为了理清所有官网没有解答的谜团;
算法本身比较简单,网上文章也很多,本人自身也提不出更高大上的解决方案,所以算法不再详解;重点就是解读官网的不足;
上代码:
val training = spark.read.format("libsvm")
.load(pathFile+"data/mllib/linearRegression.txt")
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0)
.setElasticNetParam(0)
解读:关于setElasticNetParam的源码描述有:
* This supports multiple types of regularization: * - none (a.k.a. ordinary least squares) * - L2 (ridge regression) * - L1 (Lasso) * - L2 + L1 (elastic net)
意思就是说:这支持多种类型的正则化操作。
具体方法描述为:
/** * Set the ElasticNet mixing parameter. * For alpha = 0, the penalty is an L2 penalty. * For alpha = 1, it is an L1 penalty. * For alpha in (0,1), the penalty is a combination of L1 and L2. * Default is 0.0 which is an L2 penalty. * * @group setParam */ @Since("1.4.0") def setElasticNetParam(value: Double): this.type = set(elasticNetParam, value) setDefault(elasticNetParam -> 0.0)可以发现这个参数设置是用来设置L1,、L2的。
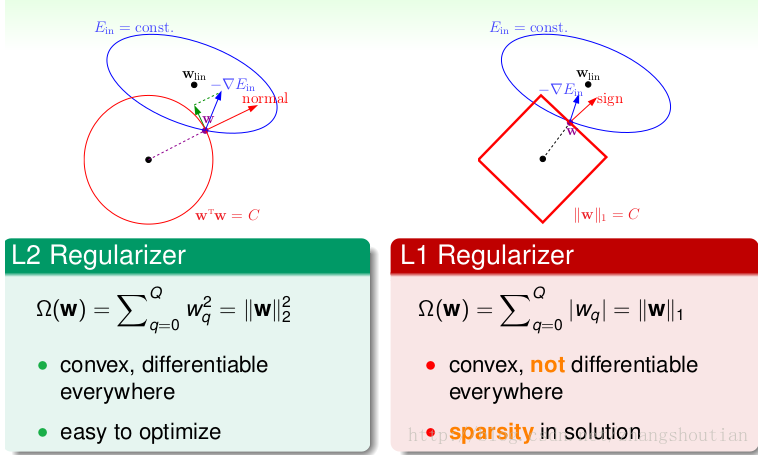
L1正则化和L2正则化可以看做是损失函数的惩罚项。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是
Python
中Lasso回归的损失函数,式中加号后面一项α||w||1
即为L1正则化项。
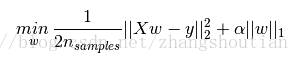
下图是Python中Ridge回归的损失函数,式中加号后面一项α||w||22即为L2正则化项。
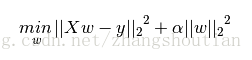
结合setRegParam(),该函数为设置正则化参数,结合以上描述
推测spark ml的线性规划完整函数为:min(1/2n||coefficients*x -y||^2^ +(elasticNetParam*L1-(1-elasticNetParam)*L2))
也就是说:正则化参数设置为0时,elasticNetParam的设置无意义。
下面继续代码验证,及其测试结果
val lrModel = lr.fit(training)
//Y=w*x+b 回归系数(w) and 截距(b)
println(s"Coefficients: ${lrModel.coefficients} Intercept: ${lrModel.intercept}")
//总结训练集上的模型并打印出一些指标
val trainingSummary = lrModel.summary
println(s"numIterations: ${trainingSummary.totalIterations}")
println(s"objectiveHistory: [${trainingSummary.objectiveHistory.mkString(",")}]")
trainingSummary.residuals.show()//残差
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}")//均方根误差
println(s"r2: ${trainingSummary.r2}")//判定系数,也称为拟合优度,越接近1越好
1 1:0
2 1:1
3 1:2
4 1:3
5 1:4Coefficients: [0.9999999999999993] Intercept: 1.000000000000001
numIterations: 1
objectiveHistory: [0.0] 1 1:0.2
2 1:1.1
3 1:2.1
4 1:2.9
5 1:4Coefficients: [1.0619069136918209] Intercept: 0.8124717577948491
numIterations: 1
objectiveHistory: [0.0]
结果为:
Coefficients: [0.9908261029681737] Intercept: 0.9588982278855623
numIterations: 3
objectiveHistory: [0.5,0.4037043811427782,0.040903518280319406]
结果为:
复杂的没有测试,欢迎批评指正
Coefficients: [0.9878122500298612] Intercept: 0.9651067649384861
numIterations: 3
objectiveHistory: [0.5,0.4116133463948107,0.06201518671563113]复杂的没有测试,欢迎批评指正















 4512
4512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









