







1.物理页面管理
从硬件的角度说,Linux内核只要能为硬件准备好PGD、PT、GDT、LDT以及相应寄存器,就完成了内存管理机制中地址映射准备工作。但是Linux 内核实际做的工作更复杂,其中几个主要的数据结构构成了Linux 内存管理的基本框架
页目录:pgd_t
中间目录:pmd pmd_t (64位运行环境 x86_64 CPU,X86_PAE)
页表:pte_t
1.1 页式映射结构
32bit运行环境下的数据结构:
typedefstruct{unsignedlong pte_low;}pte_t;typedefstruct{unsignedlong pmd;}pmd_t;typedefstruct{unsignedlong pgd;}pgd_t;
pte_t、pmd_t、pgd_t 实际上是 32bit unsigned long,之所以不直接定义成unsigned long 是为了让gcc进行更加严格的类型检查
(参见 include/asm-i386/page.h)
pte_t 高20位看做物理页面的页号,低12位为页面的状态信息和访问权限
低12位中有9位为状态位,如下列代码(参见 include/asm-i386/pgtable.h):
#define _PAGE_PRESENT 0x001 //查看页面是否在内存中#define _PAGE_RW 0x002#define _PAGE_USER 0x004#define _PAGE_PWT 0x008#define _PAGE_PCD 0x010#define _PAGE_ACCESSED 0x020#define _PAGE_DIRTY 0x040#define _PAGE_PSE 0x080 /* 4 MB (or 2MB) page, Pentium+, if present.. */#define _PAGE_GLOBAL 0x100 /* Global TLB entry PPro+ */- #define _PAGE_PROTNONE 0x080 /* If not present */
映射步骤:
if(_PAGE_PRESENT equal to 1)
映射的页面在内存,映射完成(pte_t的高20位为物理页面地址)
else
产生缺页异常
1.2 page(mem_map_t)结构:
typedef struct page { struct list_head list; struct address_space *mapping; unsigned long index; struct page *next_hash; atomic_t count; unsigned long flags; /* atomic flags, some possibly updated asynchronously */ struct list_head lru; unsigned long age; wait_queue_head_t wait; struct page **pprev_hash; struct buffer_head * buffers; void *virtual; /* non-NULL if kmapped */} mem_map_t;
Linux内核中有一个全局量mem_map(page | mem_map_t结构指针),指向一个page数据结构的数组,每个page数据结构代表一个物理页面,整个数组代表着系统中的全部物理页面。pet_t 表项的高20位,对于软件来说,这是一个物理页面序号,将这个序号用作下标就可以从mem_map找到这个物理页面的数据结构;对于硬件来说,补上12个0就是物理页面的起始地址。page结构和物理页面一一对应。
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT)) //内核态代码
(参见 include/asm-i386/page.h)
1.3 zone管理区:
在page结构的上层有一个zone_struct(管理区)结构,对page进行管理
系统默认分成3个区:
zone_dma:0-16M
zone_normal:16M-896M
zone_himem:>896M
一旦建立起管理区,每个物理页面(page)就永久属于某一个管理区(zone_struct),具体取决于页面的起始地址(offset)
每一个管理区都有一个数据结构,zone_struct
11 /*12 * Free memory management - zoned buddy allocator.13 */1415 #define MAX_ORDER 101617 typedef struct free_area_struct {18 struct list_head free_list;19 unsigned int *map;20 } free_area_t;2122 struct pglist_data;2324 typedef struct zone_struct {25 /*26 * Commonly accessed fields:27 */28 spinlock_t lock;29 unsigned long offset; //mem_map的下标,该zone的起始物理页面30 unsigned long free_pages;31 unsigned long inactive_clean_pages;32 unsigned long inactive_dirty_pages;33 unsigned long pages_min, pages_low, page s_high;3435 /*36 * free areas of different sizes37 */38 struct list_head inactive_clean_list;39 free_area_t free_area[MAX_ORDER]; //进行物理页面的分配4041 /*42 * rarely used fields:43 */44 char *name;45 unsigned long size;46 /*47 * Discontig memory support fields.48 */49 struct pglist_data *zone_pgdat;50 unsigned long zone_start_paddr;51 unsigned long zone_start_mapnr;52 struct page *zone_mem_map;53 } zone_t;5455 #define ZONE_DMA 056 #define ZONE_NORMAL 157 #define ZONE_HIGHMEM 258 #define MAX_NR_ZONES 3
(参见 include/linux/mmzone.h)
1.4 pglist_data 结构
传统的计算机结构中,整个物理空间均匀一致的,CPU访问任何内存地址的时间都是相同的,称之为UMA(uniform memory architecture 均质存储结构)。在UMA结构中,除主存(ram)之外的存储器都很小,所以将他们放在特殊地址上,在编程时特别注意即可。
UMA其实并不严格存在,现在的PC都包括主存(ram),显卡(sram),bios(ROM)等。这些存储器的访问时间是不同的,称之为NUMA:non-uniform memory architecture(非均质存储结构),在典型的NUMA结构中需要Linux内核中内存管理机制的支持。
由于NUMA,对物理页面机制进行了相应修正,zone(管理区)不再是最高层的物理页面管理结构,而是每个存储节点至少有两个管理区。而且前面的page结构数组(mem_map)也不再是全局的,而是从属于具体的存储节点。
从而,zone_struct之上又有一层存储结构struct pglist_data
typedef struct pglist_data { zone_t node_zones[MAX_NR_ZONES]; zonelist_t node_zonelists[NR_GFPINDEX]; struct page *node_mem_map; unsigned long *valid_addr_bitmap; struct bootmem_data *bdata; unsigned long node_start_paddr; unsigned long node_start_mapnr; unsigned long node_size; int node_id; struct pglist_data *node_next;} pg_data_t;
2.虚拟空间管理
2.1 vma结构
大概没有一个进程会直接使用3G的内存,此外进程使用的内存在多数情况下也是离散的。
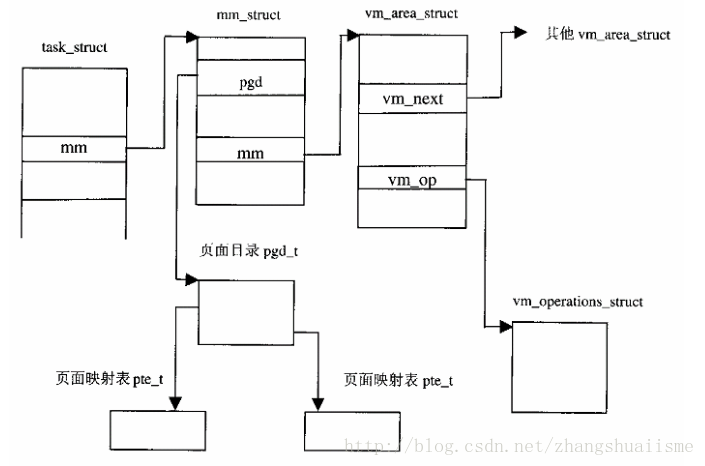
我们使用 vm_area_struct结构管理离散的进程虚拟内存。在内核中这个结构体常被写为vma,一个vma结构记录了一段连续的虚拟内存空间。虚拟内存空间的划分主要取决于地址的连续性和访问权限,同一区间的虚拟内存有相同的访问属性和其他属性(vm_flags,vm_page_prot的用途)。
同一进程的所有虚拟内存区间都要按地址从高到低的顺序连在一起(vma结构体穿成一个链表),当vma数量大于 AVL_MIN_MAP_COUNT时,为了提高访存效率,创建了AVL树(3.x内核已经变成了红黑树)。
mapping、vm_next_share、vm_pprev_share、vm_file记录了虚拟空间和磁盘之间的交互的联系。其中包括,页面的swap、mmap的文件映射。
41 struct vm_area_struct {42 struct mm_struct * vm_mm; /* VM area parameters */43 unsigned long vm_start; //虚拟空间起始位置44 unsigned long vm_end; //虚拟空间终止位置4546 /* vma 链表的相关变量 linked list of VM areas per task, sorted by address */47 struct vm_area_struct *vm_next;48 /* vma 访问权限相关变量 */49 pgprot_t vm_page_prot;50 unsigned long vm_flags;5152 /* vma AVL树的相关变量 AVL tree of VM areas per task, sorted by address */53 short vm_avl_height;54 struct vm_area_struct * vm_avl_left;55 struct vm_area_struct * vm_avl_right;5657 /* For areas with an address space and backing store,58 * one of the address_space->i_mmap{,shared} lists,59 * for shm areas, the list of attaches, otherwise unused.60 */61 struct vm_area_struct *vm_next_share;62 struct vm_area_struct **vm_pprev_share;6364 struct vm_operations_struct * vm_ops;65 unsigned long vm_pgoff; /* offset in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */66 struct file * vm_file;67 unsigned long vm_raend;68 void * vm_private_data; /* was vm_pte (shared mem) */69 };
vm_operations_struct 结构:
由于不同的虚拟空间可能会需要一些不同的附加操作。该结构给出了一些函数接口的定义(函数指针),包括open,close,nopage(3.x变成了fault)等对虚拟空间的操作。这个结构类似于Linux驱动的file_operations结构。
struct vm_operations_struct { void (*open)(struct vm_area_struct * area); void (*close)(struct vm_area_struct * area); struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int write_access);};
2.2 mm_struct 结构
mm_struct 结构是比vma更高层次的结构。
每个进程只有一个 mm_struct 结构,是整个进程的虚拟内存空间的抽象。
mm_struct可以对应多个进程,比如父子进程。
mmap:vma链表头
mmap_avl:vma的AVL树根
mmap_cache:指向最近一次用到的vma
mm_users,mm_count:记录mm_struct对应的进程情况(可能不止一个)
start_code, end_code, start_data, end_data:对应进程映像的代码段,数据段(与段式存储管理不同)
struct mm_struct { struct vm_area_struct * mmap; /* list of VMAs */ struct vm_area_struct * mmap_avl; /* tree of VMAs */ struct vm_area_struct * mmap_cache; /* last find_vma result */ pgd_t * pgd; atomic_t mm_users; /* How many users with user space? */ atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */ int map_count; /* number of VMAs */ struct semaphore mmap_sem; //vma访存的互斥信号量 spinlock_t page_table_lock; struct list_head mmlist; /* List of all active mm's */ unsigned long start_code, end_code, start_data, end_data; unsigned long start_brk, brk, start_stack; unsigned long arg_start, arg_end, env_start, env_end; unsigned long rss, total_vm, locked_vm; unsigned long def_flags; unsigned long cpu_vm_mask; unsigned long swap_cnt; /* number of pages to swap on next pass */ unsigned long swap_address; /* Architecture-specific MM context */ mm_context_t context;};
3.总结
物理空间管理是从“供”的角度进行管理的,用户空间则是从“需”的角度进行管理的。
虚拟空间的 vma 和 mm_struct 等结构描述了进程对内存的需求。
物理空间的 page 和zone_struct 等结构描述了页面的供应。
而pgd,pmd,pte表示了二者之间的桥梁














 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









