







背景
对用户每天的访问次数进行统计时,需要对用户访问页面相邻的时间间隔小于30分钟归并为一组(算是一次),这样可以统计出用户每天的访问次数(忽略隔天问题)。这个问题如果用python来处理可能比较方便,可以循环遍历每行,进行两两之间的比较。利用Hive来处理数据,劣势就是不能循环遍历不够灵活,但是也能处理,只是过程相对比较复杂
模拟数据与预想的效果

创建测试数据
--创建临时表
create table test.tmp_datashare
(user_id string comment '用户id',
url string comment '网页',
create_time string comment '访问时间')
comment '用户访问日志'
row format delimited fields terminated by '\t' lines terminated by '\n';
--加载数据
load data local inpath '/tmp/datashare.txt' overwrite into table test.tmp_datashare;
测试数据:
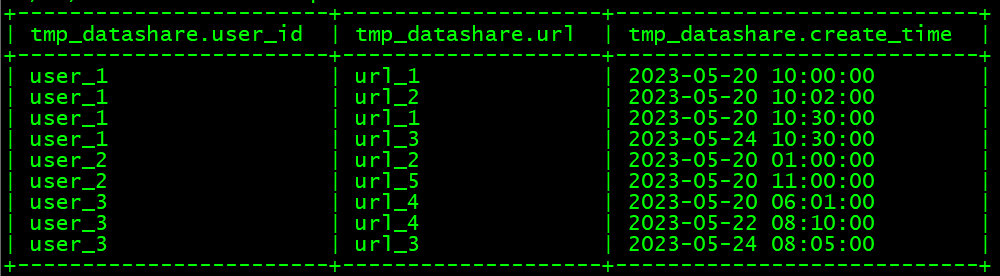
数据处理过程
-
数据处理的难点:
1、时间处理需要用到UNIX_TIMESTAMP转换为时间戳
2、运用窗口函数LAG提取前一行的访问时间
3、再次运用窗口函数SUM进行归并分组 -
具体代码如下:
with a as (select user_id,url,create_time,
lag(create_time,1) over(partition by user_id order by create_time) as last_1_time
from clwtest.tmp_datashare
),
b as (select user_id,url,create_time,
case
when last_1_time is null then 1
when (unix_timestamp(create_time,'yyyy-MM-dd HH:mm:ss')-
unix_timestamp(last_1_time,'yyyy-MM-dd HH:mm:ss'))/60<30 then 0
else 1
end as group_tmp
from a
),
c as (select user_id,url,create_time,
sum(group_tmp) over(partition by user_id order by create_time) as group_id
from b
)
select user_id,url,create_time,group_id
from c
order by user_id,create_time
- 结果数据:
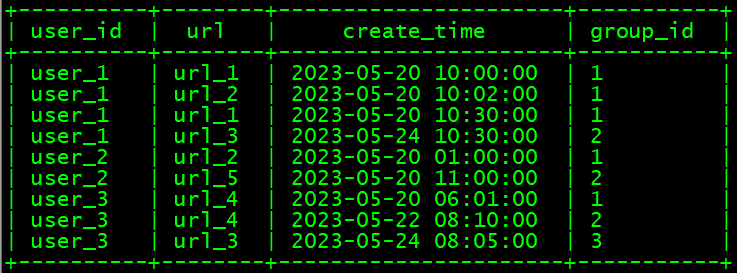
历史相关文章
以上是自己实践中遇到的一些问题,分享出来供大家参考学习,欢迎关注微信公众号:DataShare ,不定期分享干货
















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











