







一文掌握Lambda表达式(下)![]() https://mp.csdn.net/mp_blog/creation/editor/125537895
https://mp.csdn.net/mp_blog/creation/editor/125537895
目录
一、lambda基础知识
lambda语法
在Java语言中lambda表达式包含一个参数列表和一个lambda体,两者之间使用一个函数箭头"->"分割,如果有多个参数必须包围在括号中;如下文,表示入参数为x,y;求 x,y的和
(x,y)->x+y
函数式接口
对于函数式接口实例的引用有效时就可以使用lambda表达式。什么是函数式接口呢?只有一个抽象方法的接口称为函数式接口
lambda与匿名内部类
加入我们有一个数组[1,4,8],对这个数据进行排序;使用匿名内部类的实现方式如下:
Arrays.asList(1,4,8).sort(new Comparator<Integer>() {
@Override
public int compare(Integer a, Integer b) {
return a.compareTo(b);
}
})使用lambda表达式的实现则是:
Arrays.asList(1,4,8).sort((a,b)->a.compareTo(b));
两者看起来很像,那么lambda是不是就是匿名内部类的语法糖呢?实际上两者之间还是有一些区别的
- 内部类的声明会创建一个新的命名作用域,在这个作用域中this指的是当前内部类实力;而lambda不会引入任何新的命名作用域。
- 内部类创建方式会确保创建一个拥有唯一标识的心对象,而lambda则不一定
方法引用
lambda有以下四种对现有类具名方法的引用
| 名字 | 语法 | lambada | 示例 |
| 静态方法 | ClzName | (arg)->ClzName.staticMethod(arg) | Arrays.asList(1,4,8).sort(Integer::compareTo); |
| 绑定实例方法 | expr::instMethod | (arg)->expr.instMethod(arg) | list.forEach(System.out::println); |
| 未绑定实例 | ClzName::instMethod | (arg,param)->arg.instMethod(param) | Stream.of(1).map(String::valueOf).forEach(System.out::println); |
| 构造器 | ClzName::new | (arg) ->new ClzName(arg) | Stream.of("a").map(String::new).forEach(System.out::println); |
二、 流计算
在Java8中引入Stream;流单个操作本身不是很强大,它的强大之处在于可以将各种操作组合在一起构建一个复杂的流处理l
1.流与集合
流的中心思想是延迟计算,只有需要的时候才计算。流与集合的不同之处在于流不存储值,流的目的是处理值而不是存储值;集合的目的是存储值。
2.构建流
除Java中提供了IntStream,LongStream,DoubleStream 三个原生流外,
除了上述方法以外,java.util.stream.Stream<T>类也提供了静态方法,如:
Stream.empty(); Stream.of()
2.1通过数组创建流
java.util.Arrays中提供的静态方法stream(T[])可以通过数组创建流,也可以使用Stream接口提供的静态方法Stream.of(T[])创建流,我们通过代码可以发现of方法也是调用Arrays.stream
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}2.2通过集合类创建流
java.util.Collection<T>中提供的默认方法是我们平时最常用生成流的方式;其中parallelStream方法表示生产并行流。
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}示例代码
Stream<Integer> stream = Arrays.asList(1, 2, 3).stream();
Set<Integer> sets=new HashSet<>();
sets.add(1);
sets.add(2);
sets.add(3);
sets.stream();2.3创建持续流
在Stream中提供了iterator方法,可以根据传入的种子和一个函数式接口创建一个连续流,如下问代码所示,生成一个从1开始自增的流
Stream.iterate(0,i->i+1).forEach(System.out::println);
除了iterator方法外也可以通过generate创建一个常量流
Stream.generate(()->1).forEach(System.out::println);
3.流处理
一个标准的流处理包含以下三个部分:
- 流创建
- 流操作
- 流终止处理
其中流创建和流终止是必备可少的两个部分,上文也说到流的核心思想就是延迟处理,如果没有终止操作流是不会做任何处理的。流的终止操作可以分为以下几种
- 匹配
- 搜索
- 汇聚
- 收集
- 副作用
下文会进行详细介绍。
3.1过滤
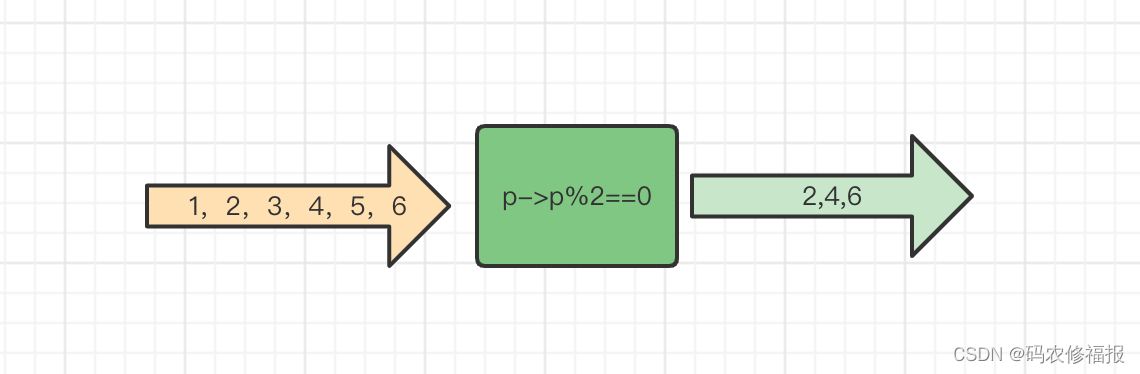
Stream<T> filter(Predicate<? super T> predicate);是Stream提供的一个可以选择地处理元素的方法,仅仅处理输入流中满足predicate条件的元素。如下图所示,输入流为[1,2,3,4,5,6];predicate 是p%2==0,那么经过filter处理后的结果是2,4,6
3.2映射
方法map会通过提供的Function<T,R>转换每个流元素
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
如下图:将[1,2,3,4,5,6]转换为字符串 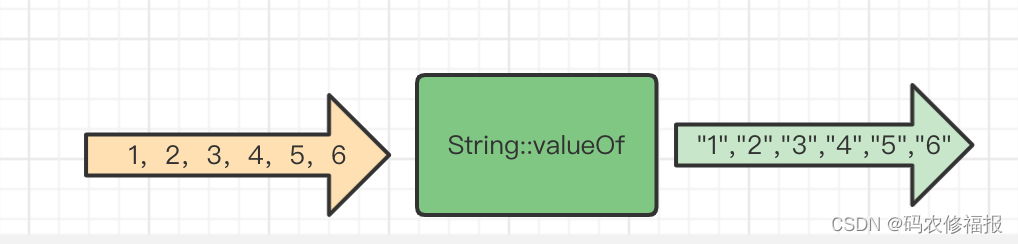
除了上述这种简单的映射外还有一种一对多的映射操作flatMap
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
如果所示,输入流是中的元素是一个collection,经过flatMap操作以后,将其平铺到一个流中。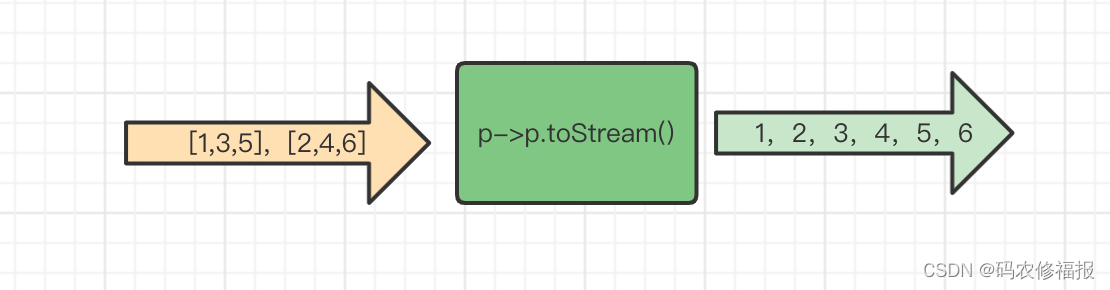
3.3调试
流处理带来便利的同时也有不便之处,对于中间执行操作的参数很难调试;Stream提供了一个peek操作,它输入和输出流的元素以及顺序相同,我们可以通过它来打印调试信息
Arrays.asList(1,4,8).stream().peek(System.out::println).collect(Collectors.toList());
3.4排序
在上文中的排序可以使用Stream提供的sort方法进行排序
Arrays.asList(1,4,8).stream().peek(System.out::println).sorted(Integer::compareTo).collect(Collectors.toList());
3.5去重
Stream提供了distinct方法进行去重操作
3.6截断
Stream提供了skip()和limit()两个方法用于流的截断处理,skip()是丢掉前n的元素保留剩余元素,而limit则是保留前n个元素;如下代码输出的结果是[8,10]
System.out.println(Arrays.asList(1,4,8,10).stream().skip(2).collect(Collectors.toList()));
而这段代码输出的结果是[1,4]
System.out.println(Arrays.asList(1,4,8,10).stream().limit(2).collect(Collectors.toList()));
3.7匹配
匹配是用于测试流中的某个元素或全部元素满足指定的predicate;anyMatch任意一个元素满足就返回true,allMatch全部元素都满足返回true;如果是流是empty也会返回true;noneMatch全部都不满足返回true
boolean anyMatch(Predicate<? super T> predicate);
boolean allMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);
3.8搜索
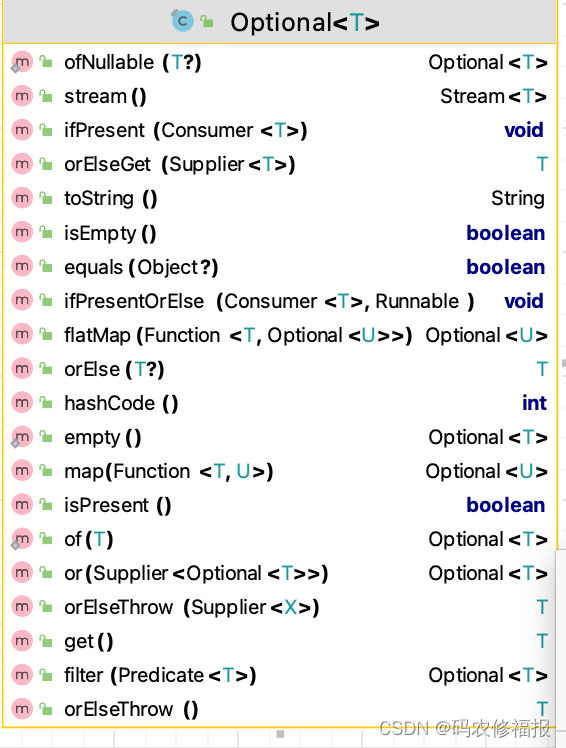
搜索主要有两个方法findFirst()和findAny(),区别就在于findFirst返回匹配的第一个元素,findAny()返回元素的位置就无从得知
Optional<T> findFirst();
Optional<T> findAny();我们看这两个方法的返回值是Optional,他的主要方法有
3.9汇聚
Steam提供了几个汇聚方法,见名知意,方法如下:
long count();
Optional<T> max(Comparator<? super T> comparator);
Optional<T> min(Comparator<? super T> comparator);
Optional<T> max(Comparator<? super T> comparator);
3.10收集
收集元素是使用Stream.collection方法将元素积聚到可变容器中,这个是流操作中重要的部分,后续文章中将重点介绍
<R, A> R collect(Collector<? super T, A, R> collector);
3.11副作用
Stream提供了可以替代迭代器操作的方法foreach
void forEach(Consumer<? super T> action);
void forEachOrdered(Consumer<? super T> action);
总结
本文主要对流与操作做了一个总体的介绍,后续将详细介绍流的收集与汇聚
















 224
224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











