







目录
Random Walk Optimization无监督feature learning
Notation
是要找到的节点u的嵌入。
从节点u出发的random walks访问节点v的概率。
基于两个非线性函数生成所需概率:Softmax函数处理后,使大的对应的值更大,使K个概率和为1;Sigmoid函数,将值压缩到(0,1)。

random walk:给定一个图和一个起始节点,随机选择一个邻居节点,移动到邻居节点,随机选择这个邻居节点的 邻居节点(也可以移动到上一步经过的点),移动到它,持续下去直到给定步长。以这种方式随机访问的节点序列——称为图上的random walk。
两个节点嵌入的内积约等于节点u和v在图上通过一个随机游走共现的概率。
Random-Walk Embeddings
估计使用某种随机游走策略,从一个初始节点的random walk访问节点v的概率,优化嵌入。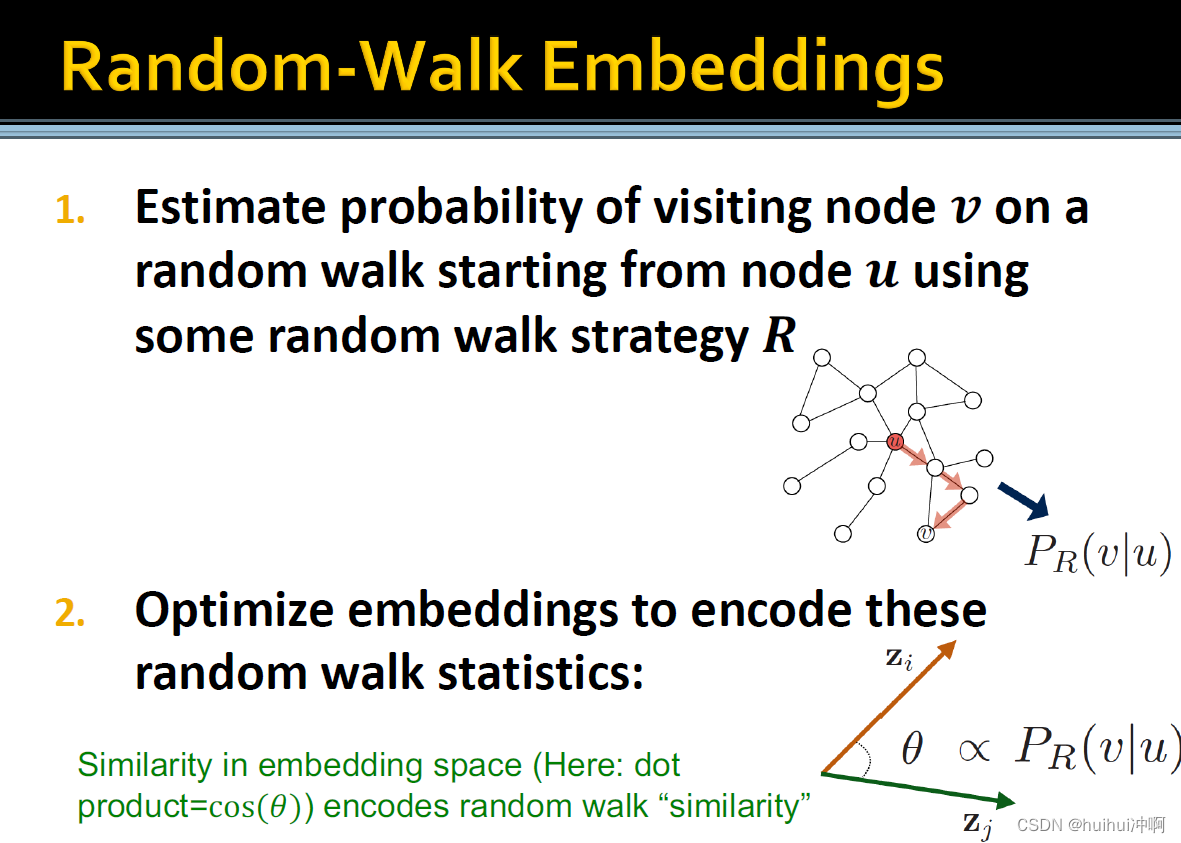
为什么Random Walks
- 更好的表达
灵活的相似性的定义:考虑了局部邻居和高阶(出现次数多)的邻居信息,如果从u开始的随机游走访问v的概率大(high-order multi-hop information),那么两者具有相似性。
- 更有效率
在训练时不需要考虑所有节点,只需要考虑在random walks上共同出现的节点对。
Random Walk Optimization
无监督feature learning

Random Walk Optimization
思路
- 使用某种随机游走策略R,从图中的一个初始节点u出发的,运行固定长度的random walks。
- 对于每个节点收集
,是从u出发的random walks访问的节点集multiset(指一个节点可以多次访问)
- 优化embedding,最大化两个节点共限的概率 或者指找到嵌入
最大化目标函数

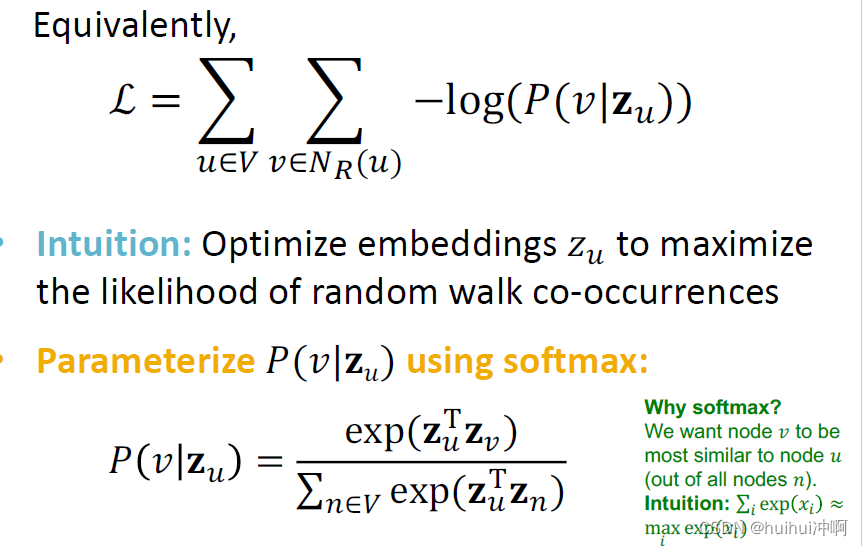
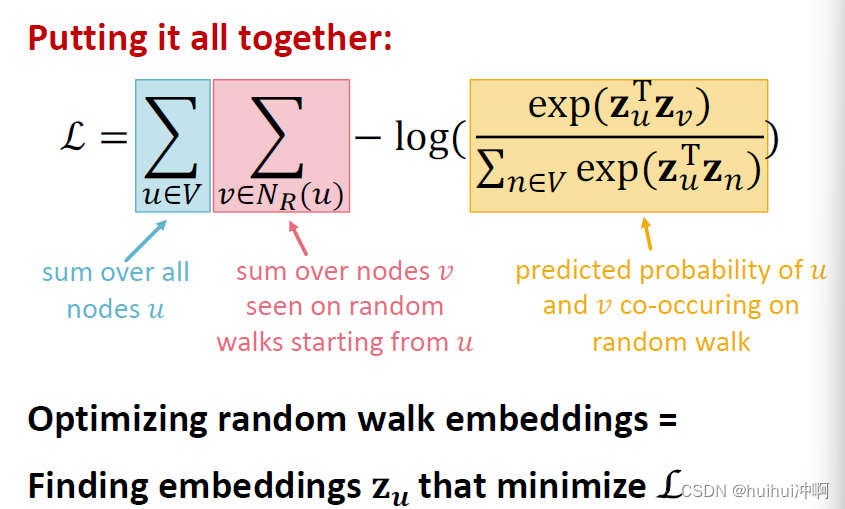
由于softmax的归一化计算涉及网络中所有节点,计算复杂度高。
Negative Sampling—降低计算复杂度
将利用所有节点归一化,改为使用k个随机的"负采样点"归一化

从一个随机分布Pv中选取,这些节点的概率与其度数成正比

SGD
在获得目标函数后使用SGD优化 而不是GD,即不是使用所有节点计算梯度,而是使用单独的一个训练样本.'


Random Walks:Summary
- 使用某种随机游走策略R,从图中的一个初始节点u出发的,运行固定长度的random walks。
- 对于每个节点u收集
- 使用SGD优化embedding,可以使用negative sampling近似计算目标函数。

node2vec:Biased Walks
使用灵活的,有偏向的random walks可以平衡网络的局部全局视角,使用BFS搜索(局部)DFS搜索(全局)搜寻节点u的邻居。
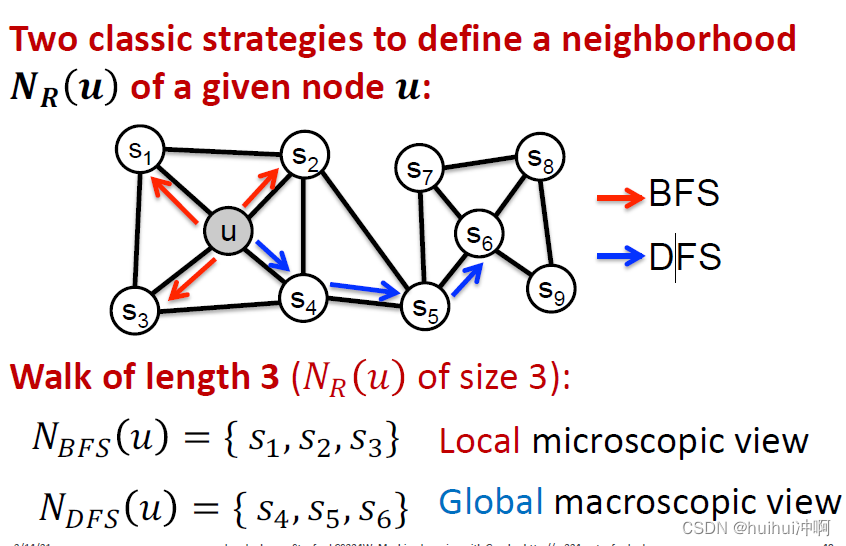
有两个超参数p和q:p是返回上一个节点,q是走开远离参数。1代表和上一个节点同一水平。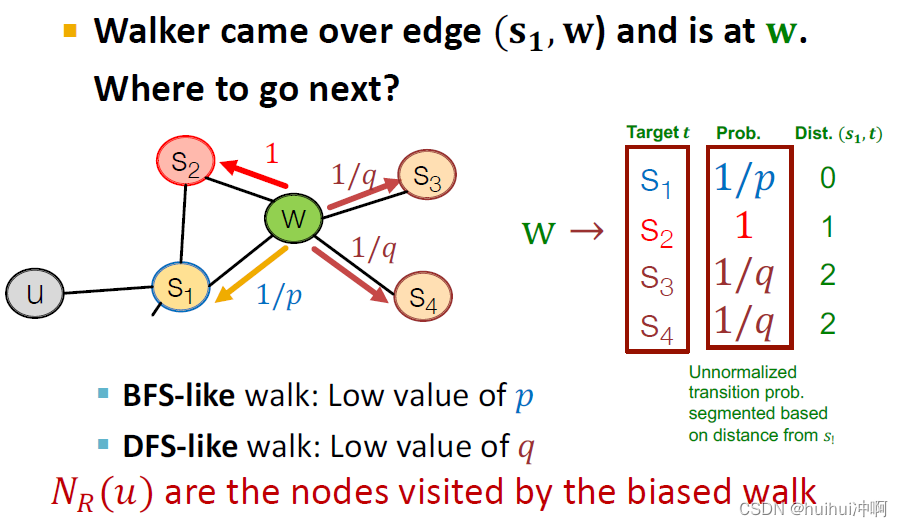


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









