







 AdaBoost算法是一种自适应提升算法,由Freund和Schapire于1995年提出,用于从弱分类器构建强分类器。它通过迭代改变样本分布,调整分类错误样本的权重,最终形成加权弱分类器的组合。算法通过最小化误差率来确定最佳弱分类器和权重,从而提高分类性能。在每次迭代后,根据误差率更新样本权重,确保分类错误的样本在下一次迭代中获得更高的重视。
AdaBoost算法是一种自适应提升算法,由Freund和Schapire于1995年提出,用于从弱分类器构建强分类器。它通过迭代改变样本分布,调整分类错误样本的权重,最终形成加权弱分类器的组合。算法通过最小化误差率来确定最佳弱分类器和权重,从而提高分类性能。在每次迭代后,根据误差率更新样本权重,确保分类错误的样本在下一次迭代中获得更高的重视。
AdaBoost(Adaptive Boosting,自适应提升)算法是由来自AT&T实验室的Freund和Schapire于1995年首次提出,该算法解决了早期Boosting算法的一些实际执行难题,而且该算法可以作为一种从一系列弱分类器中产生一个强分类器的通用方法。正由于AdaBoost算法的优异性能,Freund和Schapire因此获得了2003年度的哥德尔奖(Gödel Prize,该奖是在理论计算机科学领域中最负盛名的奖项之一)。
AdaBoost算法如下:

上图,我给出了adaboost的一个详细的算法过程,可以总结如下:
1)每次迭代改变的是样本的分布,而不是重复采样;
2)样本分布的改变取决于样本是否被正确分类总是分类正确的样本权值低,总是分类错误的样本权值高。
3)最终的结果是弱分类器的加权组合权值表示该弱分类器的性能。
下面我们给出具体解释(这里引用原文来自于这里 ,Opencv2.4.9源码分析——Boosting,作者zhaocj)。
假设我们有一个集合{(x1, y1),(x2, y2), …, (xN,yN)},每一个数据项xi是一个表示事物特征的矢量,yi是一个与其相对应的分类yi∈{-1, 1},即xi要么属于-1,要么属于1。AdaBoost算法通过M次迭代得到了一个弱分类器集合{k1, k2,…, kM},对于每一个数据项xi来说,每个弱分类器都会给出一个分类结果来,即km(xi)∈{-1, 1}。这M个弱分类器通过某种线性组合(式1所示)就得到了一个强分类器Cm,这样我们就可以通过Cm来判断一个新的数据项xk是属于-1,还是1。这就是一个训练的过程。
在进行了第m-1次迭代后,我们可以把这m-1个弱分类器进行线性组合,所得到的强分类器为:
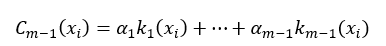
式中&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









