







一、特征选择
1.特征来源
- 业务已经整理好的各种特征数据,我们需要选择适合我们问题需要的特征
- 从业务特征中自己去寻找高级数据特征
2.选择合适的特征
首先是找到该领域懂业务的专家,让他们给一些建议。比如我们需要解决一个药品疗效的分类问题,那么先找到领域专家,向他们咨询哪些因素(特征)会对该药品的疗效产生影响,较大影响的和较小影响的都要。这些特征就是我们的特征的第一候选集。
特征选择的方法一般分三类:
- 过滤法:按照特征的发散性或者相关性指标对各个特征进行评分,设定评分阈值或者待选择阈值的个数,选择合适特征。
- 包装法:根据目标函数,通常是预测效果评分,每次选择部分特征,或者排除部分特征。
- 嵌入法:先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小来选择特征。类似于过滤法,但是它是通过机器学习训练来确定特征的优劣,而不是直接从特征的一些统计学指标来确定特征的优劣。
2.1 过滤法选择特征
- 方差筛选:方差越大的特征,那么我们可以认为它是比较有用的。如果方差较小,比如小于1,那么这个特征可能对我们的算法作用没有那么大。最极端的,如果某个特征方差为0,即所有的样本该特征的取值都是一样的,那么它对我们的模型训练没有任何作用,可以直接舍弃。在实际应用中,我们会指定一个方差的阈值,当方差小于这个阈值的特征会被我们筛掉。
- 相关系数:这个主要用于输出连续值的监督学习算法中。我们分别计算所有训练集中各个特征与输出值之间的相关系数,设定一个阈值,选择相关系数较大的部分特征。
- 假设检验:比如卡方检验。卡方检验可以检验某个特征分布和输出值分布之间的相关性。做卡方检验得到所有特征的卡方值与显著性水平P临界值,我们可以给定卡方值阈值, 选择卡方值较大的部分特征。
除了卡方检验,我们还可以使用F检验和t检验,它们都是使用假设检验的方法,只是使用的统计分布不是卡方分布,而是F分布和t分布而已。 - 互信息(信息增益):即从信息熵的角度分析各个特征和输出值之间的关系评分。互信息值越大,说明该特征和输出值之间的相关性越大,越需要保留。
在没有什么思路的 时候,可以优先使用卡方检验和互信息来做特征选择。
2.2 包装法选择特征
最常用的包装法是递归消除特征法(recursive feature elimination,以下简称RFE)。递归消除特征法使用一个机器学习模型来进行多轮训练,每轮训练后,消除若干权值系数的对应的特征,再基于新的特征集进行下一轮训练。在sklearn中,可以使用RFE函数来选择特征。
下面以经典的SVM-RFE算法来讨论这个特征选择的思路。这个算法以支持向量机来做RFE的机器学习模型选择特征。它在第一轮训练的时候,会选择所有的特征来训练,得到了分类的超平面wx˙+b=0后,如果有n个特征,那么RFE-SVM会选择出w中分量的平方值wi^2 最小的那个序号i对应的特征,将其排除,在第二类的时候,特征数就剩下n-1个了,我们继续用这n-1个特征和输出值来训练SVM,同样的,去掉wi^2最小的那个序号i对应的特征。以此类推,直到剩下的特征数满足我们的需求为止。
2.3 嵌入法选择特征
嵌入法也是用机器学习的方法来选择特征,但是它和RFE的区别是它不是通过不停的筛掉特征来进行训练,而是使用的都是特征全集。
最常用的是使用L1正则化和L2正则化来选择特征。正则化惩罚项越大,那么模型的系数就会越小。当正则化惩罚项大到一定的程度的时候,部分特征系数会变成0,当正则化惩罚项继续增大到一定程度时,所有的特征系数都会趋于0. 但是我们会发现一部分特征系数会更容易先变成0,这部分系数就是可以筛掉的。也就是说,我们选择特征系数较大的特征。常用的L1正则化和L2正则化来选择特征的基学习器是逻辑回归。
3.寻找高级特征
寻找高级特征最常用的方法有:
- 若干项特征加和: 我们假设你希望根据每日销售额得到一周销售额的特征。你可以将最近的7天的销售额相加得到。
- 若干项特征之差: 假设你已经拥有每周销售额以及每月销售额两项特征,可以求一周前一月内的销售额。
- 若干项特征乘积: 假设你有商品价格和商品销量的特征,那么就可以得到销售额的特征。
- 若干项特征除商: 假设你有每个用户的销售额和购买的商品件数,那么就是得到该用户平均每件商品的销售额。
寻找高级特征的方法远不止于此,它需要你根据你的业务和模型需要而得,而不是随便的两两组合形成高级特征,这样容易导致特征爆炸,反而没有办法得到较好的模型。经验是聚类的时候高级特征尽量少一点,分类回归的时候高级特征适度的多一点。
二、特征表达
1.缺失值处理
大部分机器学习模型在拟合前需要所有的特征都有值,不能是空或者NULL。
处理缺失值首先要看该特征是连续值还是离散值。
- 连续值:
-
- 第一种:选择所有该特征值的样本取平均值来填充缺失值;
-
- 第二种:取中位数来填充缺失值。
- 离散值:
-
- 选择该特征值的样本中最频繁出现的值来填充缺失值。
2.特殊的特征处理
有些特征的默认取值比较特殊,需要做了处理后才能用于算法,比如日期时间(如20190324)和地理特征(如“广州市海珠区XX街道XX号”)。
2.1 时间原始特征
- 使用连续的时间差值法:计算出所有样本的时间到某一个未来时间的差值,从而将时间特征转化为连续值。
- 根据时间所在的年,月,日,星期几,小时数,将一个时间特征转化为若干个离散特征,这种方法在分析具有明显时间趋势的问题时比较好用。
- 权重法:根据时间的新旧得到一个权重值。比如对于商品,三个月前前购买的设置一个较低的权重,最近三天购买的设置一个中等的权重,在三个月内但是三天前的设置一个较大的权重。设置权重的方法根据要解决的问题来灵活确定。
2.2 地理特征
- 处理成离散值:转化为多个离散的特征,比如城市名特征,区县特征,接到特征等。
- 处理成连续值:将地址处理成经度和纬度的特征。可用于需要判断用户分布区域时。
3.离散特征的连续化处理
有很多机器学习算法只能处理连续值特征,不能处理离散值特征,比如线性回归,逻辑回归等。
3.1 one-hot 编码(encoding)
比如某特征的取值是高,中和低,那么就可以创建三个取值为0或者1的特征,将高编码为1,0,0这三个特征;中编码为0,1,0这三个特征;低编码为0,0,1这三个特征。也就是之前的一个特征被转化为了三个特征。(连续化可理解为特征one-hot之后变到了[0,1]区间)
3.2 特征嵌入(embedding)
一般用于深度学习中。比如对于用户的ID这个特征,如果要使用one-hot编码,维度会爆炸,如果使用特征嵌入维度会低很多。对于每个要嵌入的特征,会有一个特征嵌入矩阵,这个矩阵的行很大,对应该特征的数目(比如用户的ID,如果有100万个,那么嵌入的特征矩阵是100万行),列一般较小(比如取为20),这样每个用户的ID就转化为了一个20维的特征向量。
4.离散特征的离散化处理
- one-hot编码
- 虚拟编码(dummy coding):与one-hot类似,但特点是如果特征有N个取值,那么只需要N-1个新的0,1特征来代替,而one-hot编码会用N个0,1特征代替。比如一个特征的取值是高,中和低,那么我们只需要两位编码,比如只编码中和低,如果是1,0则是中,0,1则是低。0,0则是高了。目前虚拟编码使用的没有独热编码广,因此一般有需要的话还是使用独热编码比较好。
5.连续特征的离散化处理
对于连续特征,有时候我们也可以将其做离散化处理。这样特征变得高维稀疏,方便一些算法的处理。
对常用的方法是根据阈值进行分组,比如我们根据连续值特征的分位数,将该特征分为高,中和低三个特征。将分位数从0-0.3的设置为高,0.3-0.7的设置为中,0.7-1的设置为高。
当然还有高级一些的方法。比如使用GBDT。在LR+GBDT的经典模型中,就是使用GDBT来先将连续值转化为离散值。那么如何转化呢?比如我们用训练集的所有连续值和标签输出来训练GBDT,最后得到的GBDT模型有两颗决策树,第一颗决策树有三个叶子节点,第二颗决策树有4个叶子节点。如果某一个样本在第一颗决策树会落在第二个叶子节点,在第二颗决策树落在第4颗叶子节点,那么它的编码就是0,1,0,0,0,0,1,一共七个离散特征,其中会有两个取值为1的位置,分别对应每颗决策树中样本落点的位置。在sklearn中,我们可以用GradientBoostingClassifier的 apply方法很方便的得到样本离散化后的特征,然后使用独热编码即可。
三、特征预处理
1.特征的标准化与归一化
1.1 z-score标准化
基于正态分布的假设,将数据变换为均值为0、标准差为1的标准正态分布。但即使数据不服从正态分布,也可以用此法。特别适用于数据的最大值和最小值未知,或存在孤立点。
具体的方法是求出样本特征x的均值mean和标准差std,然后用(x-mean)/std来代替原特征。这样特征就变成了均值为0,方差为1了。
1.2 max-min标准化(也称离差标准化)
归一化的常用方法,使特征值映射到[0,1]之间,可以使数据处理过程更加便捷快速。经过归一化处理的数据,处于同一数量级,可以消除指标之间的量纲和量纲单位的影响,提高不同数据指标之间的可比性。
具体的方法是求出样本特征x的最大值max和最小值min,然后用(x-min)/(max-min)来代替原特征。如果我们希望将数据映射到任意一个区间[a,b],而不是[0,1],那么用(x-min)(b-a)/(max-min)+a来代替原特征即可。
这种方法的问题就是如果测试集或者预测数据里的特征有小于min,或者大于max的数据,会导致max和min发生变化,需要重新计算。所以实际算法中, 除非你对特征的取值区间有需求,否则max-min标准化没有 z-score标准化好用。
1.3 L1/L2范数标准化
如果我们只是为了统一量纲,那么通过L2范数整体标准化也是可以的,具体方法是求出每个样本特征向量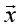 的L2范数
的L2范数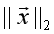 ,然后用
,然后用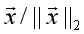 代替原样本特征即可。当然L1范数标准化也是可以的,即用
代替原样本特征即可。当然L1范数标准化也是可以的,即用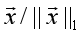 代替原样本特征。通常情况下,范数标准化首选L2范数标准化。
代替原样本特征。通常情况下,范数标准化首选L2范数标准化。
此外,经常我们还会用到中心化,主要是在PCA降维的时候,此时我们求出特征x的平均值mean后,用x-mean代替原特征,也就是特征的均值变成了0, 但是方差并不改变。
虽然大部分机器学习模型都需要做标准化和归一化,也有不少模型可以不做做标准化和归一化,主要是基于概率分布的模型,比如决策树大家族的CART,随机森林等。当然此时使用标准化也是可以的,大多数情况下对模型的泛化能力也有改进。
2.异常特征样本的清洗
- 第一种是聚类,比如我们可以用KMeans聚类将训练样本分成若干个簇,如果某一个簇里的样本数很少,而且簇质心和其他所有的簇都很远,那么这个簇里面的样本极有可能是异常特征样本了。我们可以将其从训练集过滤掉。
- 第二种是异常点检测方法,主要是使用iForest或者one class SVM,使用异常点检测的机器学习算法来过滤所有的异常点。
3.处理不平衡数据
做分类算法训练时,如果训练集里的各个类别的样本数量不是大约相同的比例,就需要处理样本不平衡问题。如果不处理,那么拟合出来的模型对于训练集中少样本的类别泛化能力会很差。举个例子,我们是一个二分类问题,如果训练集里A类别样本占90%,B类别样本占10%。 而测试集里A类别样本占50%, B类别样本占50%, 如果不考虑类别不平衡问题,训练出来的模型对于类别B的预测准确率会很低,甚至低于50%。
一般是两种方法:权重法或者采样法。
- 权重法:可以对训练集里的每个类别加一个权重class weight。如果该类别的样本数多,那么它的权重就低,反之则权重就高。如果更细致点,我们还可以对每个样本加权重sample weight,思路和类别权重也是一样,即样本数多的类别样本权重低,反之样本权重高。
- 采样法:如果权重法做了以后发现预测效果还不好,可以考虑采样法。
-
- 第一种是对样本数多的类别的样本做子采样, 比如训练集里A类别样本占90%,B类别样本占10%。那么我们可以对A类的样本子采样,直到子采样得到的A类样本数和B类别现有样本一致为止,这样我们就只用子采样得到的A类样本数和B类现有样本一起做训练集拟合模型。
-
- 第二种是对样本数少的类别的样本做过采样,我们对B类别的样本做过采样,直到过采样得到的B类别样本数加上B类别原来样本一起和A类样本数一致,最后再去拟合模型。
以上两种采样法的问题是改变了训练集的分布,可能导致泛化能力差。所以有的算法可以通过其他方法来避免这个问题,比如SMOTE算法通过人工合成的方法来生成少类别的样本。方法是对于一个缺少样本的类别,随机找出几个该类别的样本,再找出最靠近这些样本的若干个该类别的样本,组成一个候选合成集合,然后在这个集合中不停地选择距离较近的两个样本,在这两个样本之间,比如说中点,构造一个新的该类别的样本。比如该类别的候选合成集合有两个样本(x1,y),(x2,y),那么SMOTE采样后,可以得到一个新的训练样本((x1+x2)/2,y),通过这种方法就可以得到不改变训练集分布的新样本,让训练集中各个类别的样本数趋于平衡。
参考:
特征选择(https://www.cnblogs.com/pinard/p/9032759.html)
特征表达(https://www.cnblogs.com/pinard/p/9061549.html)
特征预处理(https://www.cnblogs.com/pinard/p/9093890.html)















 1517
1517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









