









文章目录
前言
我们一次普通的大目录删除(含有5 Million个小文件),引发了HDFS的一次持续10分钟的读写不可用的线上事故。本文对这次事故进行了详细分析,主要从HDFS的架构本身,结合事故发生时NameNode、DataNode的各种监控指标,以NameNode端的锁控制为重要关注点,分析了HDFS对文件进行物理删除操作的整个处理过程,解释事故发生的整个过程中各个指征产生的根本原因。
其实,以此次事故为切入点介绍HDFS删除文件的基本原理和过程,只是本文的一部分。更重要的,是想引导读者身临其境地看到我们从最初的现场收集到最后通过Metrics分析、日志分析和源码分析还原出事故发生的全过程的流程。具体包括:
-
现象收集:
- 用户反馈收集:用户端的错误堆栈或者超时等异常现象,是我们对系统发生异常的最直观感受;
- 异常指标收集:在Dashboard中找到与用户问题在时间上重叠的异常指标,对Dashboard中各个看起来不正常的指标(比如,某指标的平缓上升、陡峭上升、平缓消失、陡峭消失)进行详细观察,对比各个指标异常在时间范围上的重叠或者先后关系,猜想他们之间的因果关系;
- 异常日志收集:在系统发生了直接错误(NPE等)时,日志能够给我们有价值的信息。但是,很多时候,像系统的性能瓶颈,或者系统在某一个层面的统计性异常(用户请求的增加),系统的暂停(Full GC或者锁争用) ,我们很难从日志上发现异常,Dashboard却能给我们最直观的统计结果和趋势分析。
-
现象分析:
-
对于很多事故,很多人习惯在短时间内给出一个似是而非、模棱两可、浮于表面的所谓“宏观解释”,对根本原因、具体细节往往不去探索,比如,他们经常这么表达:它看起来是用户访问量增加导致的,所以扩容就好了;它看起来是NameNode Full GC导致的,所以增加内存就好;它看起来是DataNode坏掉导致的,所以不用管;它看起来是大目录被删除导致系统短暂hang住,所以我们下次注意就行了。。。。。
-
这种浅层次的解释往往经不起推敲:用户访问量导致系统瓶颈,到底是哪里的瓶颈?用户端收到异常以前是否有自动重试?如果没有重试,那我们配置重试是不是就可以解决问题了?客户端Latency增加了,是服务器端排队时间变长了,还是具体操作时间变长了?NameNode Full GC,调整GC参数或者更换GC算法是否会有用?DataNode坏掉导致系统收到影响,可是HDFS作为分布式系统,不就应该容忍DataNode的随时损坏吗?
-
本文想表达的是,系统的逐渐稳定,就是通过解决一个个小问题所逐渐达到的效果,如果每次事故发生的时候我们的Action都只是在外围蜻蜓点水,系统稳定性不会有任何改善,我们对系统的认知和控制力也不会有任何增强。
-
探究根本原因,必须分析Metrics,日志,用户反馈,和最重要的,源代码,这个分析和判别是一个非常复杂和具有综合性的过程,尤其是像HDFS这种多角色、大型分布式系统更是这样,它要求:
- 在事故发生以后进行代码层面的专门的、专注的、及其耗时的分析,
- 管理员对HDFS的整个工作流程和源码有充分的理解和认知,
- 对上百个指标的具体含义有正确的理解。这些指标的含义很多无法从名字中直接获得,也只能看代码。
- 对Metrics上和日志中的异常点非常敏感,比如持续尖峰,持续低谷,陡峭的上升,陡峭的下降,我们都要加以分析。甚至,预期之内的尖峰等没有出现,也是我们需要解释的,因为这有可能暗含这我们的某种推断是错误的。
只有这样,才能最终让用户反馈、Dashboard中的指标、日志和代码相互印证和自洽。
-
本文所表达的重点,正是我对Dashboard和日志中关键信息进行提取的整个过程,以及结合代码对Dashboard和日志进行解释的整个过程。这是找到根本原因的唯一方法,也是加强对HDFS在知识、理解、控制方面的最重要的方式。
-
-
解决方案
- 基于对问题的正确认知,提出解决方案往往就变得轻而易举和得心应手。
- 最坏的情况,即使短时间我们什么都不做,既然对事故本质有了正确深入的认知,事故再次发生的时候,我们心理有底、对事故的Impact和持续时间有预期;
- 当然,正确的做法应该是,我们在根本原因层面解决问题,比如,可以短时间内解决的系统Bug,我们或者自己修改代码,或者在社区找到现成的解决方案;
- 如果这个问题在高版本的系统中已经解决并且对应的解决方案很难直接cherry-pick到我们目前的版本中,那么可以考虑系统升级;
- 如果问题的发生来自于性能原因,或者是一个系统性的设计缺陷而无法短时间内解决,那么我们可以通过一些Workaround的方式临时解决,比如在外围约束用户或者拦截用户的某些危险行为以避免事故再发生。
故障发生过程
整个HDFS故障发生的时序图如下所示:
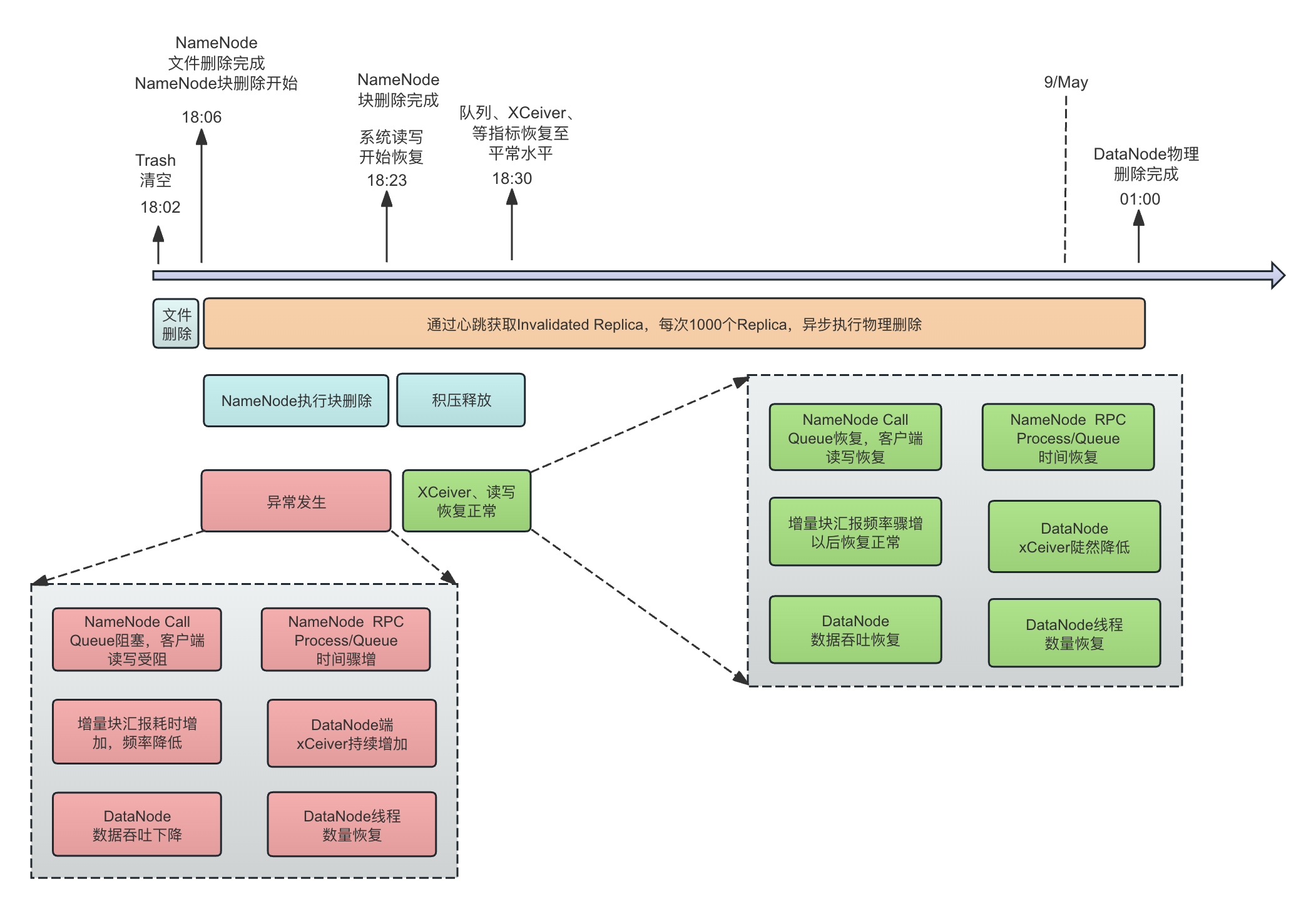
- 18:05pm 7/May: 用户删除了一个巨大的用户目录,这个目录进入了Trash
- 18:05pm 8/May: HDFS根据其Trash策略,对Trash进行了清空
- 18:06pm 8/May: 监控显式,NameNode端文件删除完成,大约5 Million的文件被删除
- 18:09pm 8/May: 监控显式,NameNode端的块删除完成,大约5 Million个Block被删除(注意,NameNode的块是逻辑块,而不是物理副本块,因此块数量大致等于文件数量)。
- 18:23pm 8/May: 删除块的汇报处理完成,系统恢复正常
- 从文件开始删除开始,到最后块汇报完成的大约18min中时间里,用户读写受到影响,RPC latency增加,块汇报耗时增加,块汇报频率降低,DataNode发XCeiver持续增加
- 01:00am 9/May: DataNode端完成了对所有块的物理删除
由于这次事故的发生是由删除了一个巨大的Trash目录引起。我们感到疑惑和无法理解的是:
- 为什么一个目录的删除会给系统带来这么大的impact?
- 这个影响是否是由于DataNode大量的磁盘删除操作引起的?如果是的,那么是否可以调整DataNode端的删除参数,使得整个删除慢慢进行,避免影响正常用户的操作?
- 如果不是由DataNode端的大量磁盘操作引起的,那么原因是什么?
基本上,从上面的时间线,我们可以得出一些初步的结论:
- NameNode端的文件删除和块删除并不是同时结束,而是分别做的。那么NameNode具体是怎么实现文件删除和块删除的?
- NameNode端和DataNode端的删除行为是完全异步的,NameNode端的删除用了10分钟,而DataNode端的物理删除用了7个小时。这说明DataNode端的删除有限流控制。
- 无论是用户的实际反馈,还是监控显式,从时间线来看,都证明整个系统受影响发生在NameNode端。
下文中,我们就结合代码和我们的Grafana监控结果,探究整个删除过程中的基本流程,以此扩展到HDFS的块管理的整个流程。
源码解析
NameNode端的Trash管理和删除过程
NameNode端的Trash清空是通过一个Emptier的Runnable来不断检查和运行的。 在NameNode构造的时候,会构造并启动对应的Emptier:
private class Emptier implements Runnable {
private Configuration conf;
private long emptierInterval;
Emptier(Configuration conf, long emptierInterval) throws IOException {
this.conf = conf;
this.emptierInterval = emptierInterval;
if (emptierInterval > deletionInterval || emptierInterval == 0) {
this.emptierInterval = deletionInterval;
}
}
对应的run()方法会不断运行,检查所有的trashRoots(就是每一个用户目录下面的.Trash目录,比如/user/root/.Trash目录),委托对应的TrashPolicyDefault来进行该目录下的清空操作:
@Override
public void run() { // 这个代码的运行虽然是在NameNode的,但是其是作为一个客户端访问NameNode的rpc进行trash的清空的
if (emptierInterval == 0)
return; // trash disabled
long now = Time.now();
long end;
while (true) {
end = ceiling(now, emptierInterval);
Thread.sleep(end - now); // 睡眠一定时间
now = Time.now();
if (now >= end) {
Collection<FileStatus> trashRoots;
trashRoots = fs.getTrashRoots(true); // list all trash dirs
for (FileStatus trashRoot : trashRoots) { // 对于每一个Trash
if (!trashRoot.isDirectory())
continue;
TrashPolicyDefault trash = new TrashPolicyDefault(fs, conf);
trash.deleteCheckpoint(trashRoot.getPath()); // 删除.Trash下面的符合时间要求的checkpoint目录
trash.createCheckpoint(trashRoot.getPath(), new Date(now)); // 将.Trash下面的Current目录生成对应的checkpoint目录
}
}
}
其实是通过ClientProtocol这个Protobuf协议,调用了NamenodeRpcServer的delete()方法:
@Override // ClientProtocol
public boolean delete(String src, boolean recursive) throws IOException {
......
namesystem.checkOperation(OperationCategory.WRITE);
boolean ret = namesystem.delete(src, recursive);
return ret;
}
NOTE: 可以看到,即使是NameNode内部触发的Trash清空,也是调用的客户端的FileSystem.delete()
这里的delete()操作最终会调用到deleteInternal()方法:
private boolean deleteInternal(String src, boolean recursive,
boolean enforcePermission, boolean logRetryCache)
throws AccessControlException, SafeModeException, UnresolvedLinkException,
IOException {
BlocksMapUpdateInfo collectedBlocks = new BlocksMapUpdateInfo();
List<INode> removedINodes = new ChunkedArrayList<INode>();
List<Long> removedUCFiles = new ChunkedArrayList<>();
FSPermissionChecker pc = getPermissionChecker();
byte[][] pathComponents = FSDirectory.getPathComponentsForReservedPath(src);
boolean ret = false;
waitForLoadingFSImage();
writeLock(); // 获取写锁,这是FSNamesystemLock
try {
// Permission check and other things
// 执行到这里,说明是recursive删除,或者,尽管不是recursive,但是目录是空的(或者是一个文件)
long mtime = now();
// 进行内存目录结构的删除操作,参数removedINodes和collectedBlocks会在删除过程中存放删除的inode和block
// 同时收集这些被删除文件的block
// 这个方法会整体上FSDirectory锁
long filesRemoved = dir.delete(src, collectedBlocks, removedINodes,
removedUCFiles, mtime);
getEditLog().logDelete(src, mtime, logRetryCache); // 这里可以看到,删除整个目录,只会在edit log中记录一条数据
incrDeletedFileCount(filesRemoved); // 先从FSDirectory的INodeMap中删除所有的INode
// 这里blocks参数为空,因此只会做的事情是解除removedUCFiles的lease,同时将removedINodes中所有的INodes从inodeMap中删除
removePathAndBlocks(src, null, removedUCFiles, removedINodes, true); // 然后从BlockManager中删除所有的block
ret = true;
} finally {
writeUnlock(); // 在这里解除全局锁
}
// 递归调用收集到的所有的block,从blockmap中删除,下面的方法在删除每一个block的时候都会加FSNamesystemLock锁和放FSNamesystemLock锁,防止全局锁被长期占用
removeBlocks(collectedBlocks); // Incremental deletion of blocks
collectedBlocks.clear();
return ret;
}
FSDirectory会通过FSDirectory.delete()方法删除对应的目录结构,并在删除的过程中收集需要删除的block的信息。
HDFS中的目录结构是以树状结构组织,我们递归删除一个HDFS目录,其实等同于删除一个树状结构的一个子树,其时间复杂度O(1),空间复杂度最多为O(logn).
但是,由于FSDirectory除了维护文件系统的INode信息结构外,还维护了每一个INode的块信息结构,这些块信息结构也必须被收集到并且清除,因此,FSDirectory.delete()就不再是简单找到对应的目录的INode然后detach就行的一个O(LogN)复杂度的操作:
----------------------------------- FSDirectory ---------------------------------------
long delete(String src, BlocksMapUpdateInfo collectedBlocks,
List<INode> removedINodes, List<Long> removedUCFiles,
long mtime) throws IOException {
if (NameNode.stateChangeLog.isDebugEnabled()) {
NameNode.stateChangeLog.debug("DIR* FSDirectory.delete: " + src);
}
final long filesRemoved;
// 上FSDirectory根目录的全局锁,不是FSNameservice的全局锁
writeLock();
try {
// 将文件路径转换成INodesInPath
final INodesInPath inodesInPath = getINodesInPath4Write(
normalizePath(src), false);
List<INodeDirectory> snapshottableDirs = new ArrayList<INodeDirectory>();
......
// 在这里进行删除操作,这里会遍历这个INodeDirectory和所有子节点,收集子节点的所有的INode和这些INode对应的BlockInfo
filesRemoved = unprotectedDelete(inodesInPath, collectedBlocks,
removedINodes, removedUCFiles, mtime);
namesystem.removeSnapshottableDirs(snapshottableDirs);
} finally {
writeUnlock(); // 解锁FSDirectory全局锁
}
return filesRemoved;
}
----------------------------------- FSDirectory ---------------------------------------
long unprotectedDelete(INodesInPath iip, BlocksMapUpdateInfo collectedBlocks,
List<INode> removedINodes, List<Long> removedUCFiles, long mtime) {
assert hasWriteLock();
// check if target node exists
INode targetNode = iip.getLastINode(); // 这个INodesInPath的最后一个节点
/**
* 这里不会存在递归调用,只是将这个Inode从它的parent中detach掉
*/
// Remove the node from the namespace
long removed = removeLastINode(iip); // 删除这个iip
// set the parent's modification time
final INodeDirectory parent = targetNode.getParent();
// 处理block的信息,并将处理的block的信息放到collectedBlocks中,
// 这些block随后会通过调用FSNamesystem.removeBlocks进行逐个删除
// collect block and update quota
if (!targetNode.isInLatestSnapshot(latestSnapshot)) { // 不在最近快照中
/**
* 如果是目录,那么调用的是 INodeDirectory.destroyAndCollectBlocks
* 递归调用发生在这里
*/
targetNode.destroyAndCollectBlocks(collectedBlocks,
removedINodes, removedUCFiles);
} else {
// process the snapshot related operation
}
return removed;
}
从BlockManager中删除Block的时候,为了避免被删除的Block过多,删除时间过长导致FSNamesystemLock锁长期被占用,这里采用的策略是每删除一定数量的Block,就释放锁,然后继续尝试获取锁然后继续删除:
void removeBlocks(BlocksMapUpdateInfo blocks) {
List<BlockInfo> toDeleteList = blocks.getToDeleteList();
Iterator<BlockInfo> iter = toDeleteList.iterator();
while (iter.hasNext()) { // 每1000从释放一次锁
writeLock(); // 加 FSNamesystemLock 全局锁
try {
for (int i = 0; i < BLOCK_DELETION_INCREMENT && iter.hasNext(); i++) {
blockManager.removeBlock(iter.next());
}
} finally {
writeUnlock(); // 解除 FSNamesystemLock全局锁
}
}
}
可以看到,文件INode的删除不是和块的删除同时进行的,而是早于块的删除的。因此我们在Dashboard上看到文件数量的下降是稍微早于块数量的下降的。
文件和块数量变化分析分析
下图显示了我们采集HDFS的ActiveNameNode在Trash清空过程中的文件数量和块数量变化:

为了能够准确立减这个Panel的含义,我们需要看一下文件数量和块数量的采集源码:
我们从代码可以看到,这里的文件总数,是调用的FSNamesystem.getFilesTotal():
------------------------------------------ FSNameSystem --------------------------------------
@Metric
public long getFilesTotal() {
// There is no need to take fSNamesystem's lock as
// FSDirectory has its own lock.
return this.dir.totalInodes();
}
------------------------------------------ FSDirectory --------------------------------------
long totalInodes() {
return getInodeMapSize();
}
@VisibleForTesting
int getInodeMapSize() {
return inodeMap.size();
}
我们查看代码可以看到,这个totalBlocks是调用的BlocksMap.size()方法的结果:
------------------------------------------ FSNameSystem --------------------------------------
@Metric
public long getBlocksTotal() {
return blockManager.getTotalBlocks();
}
----------------------------------------- BlockManager ---------------------------------------
public int getTotalBlocks() {
return blocksMap.size();
}
我们看到,块数量(BlockManager中的BlocksMap的大小)的下降是稍微晚于文件数量(FSDirectory的INodes的数量)的下降的。从上面的删除文件的过程的基本讲解,我们可以从执行逻辑上看到INode的删除是早于块的删除的。
所以,我们看到,NameNode Total Blocks and Files的准确含义是NameNode端的块(Block)和文件(INode)数量,即INodeMap和BlocksMap中块的数量。INodeMap和BlocksMap中减少的文件和块很有可能还没有发送给DataNode,即使发送给DataNode了,DataNode也不一定完成了删除。
那么,怎么看出来DataNode端的删除情况呢?
首先,DataNode端每次从heartbeat的response中获取待删除的Blocks,然后通过FsDatasetImpl.invalidate()方法为这个Block在DataNode端创建异步删除任务。只要为这个Block添加了异步删除任务ReplicaFileDeleteTask,就会计数到BlocksRemoved这个Metrics中,如下所示:
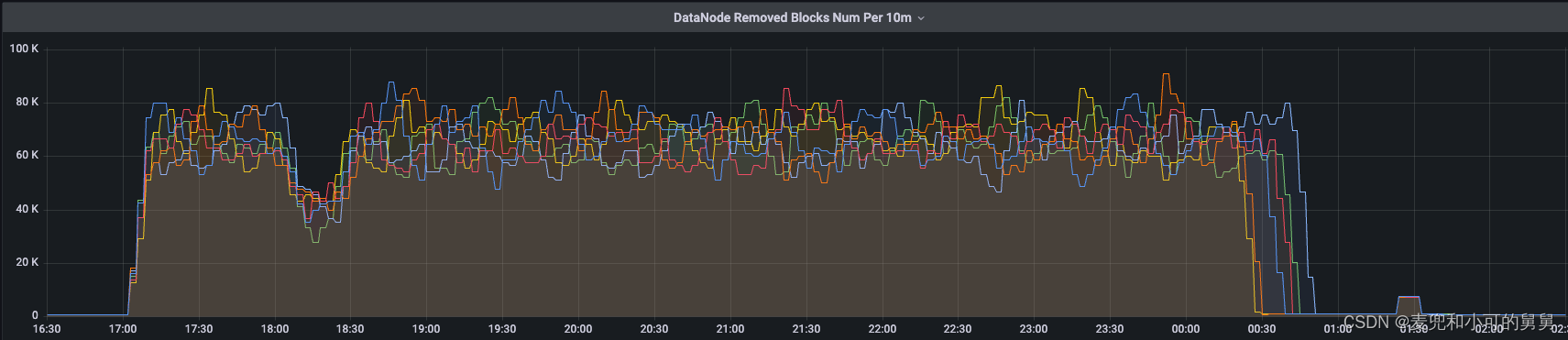
可以看到,DataNode以每次1000个Replica为一个Batch的速度,用了大概7个小时才从NameNode端拿到所有的需要删除的所有的大概4 Million个Replica并完成了磁盘上的物理删除。
下文我们会详细讲解这个指标在代码层面的具体含义。
DataNode端IBR和Heartbeat的频率和时间分析
IBR
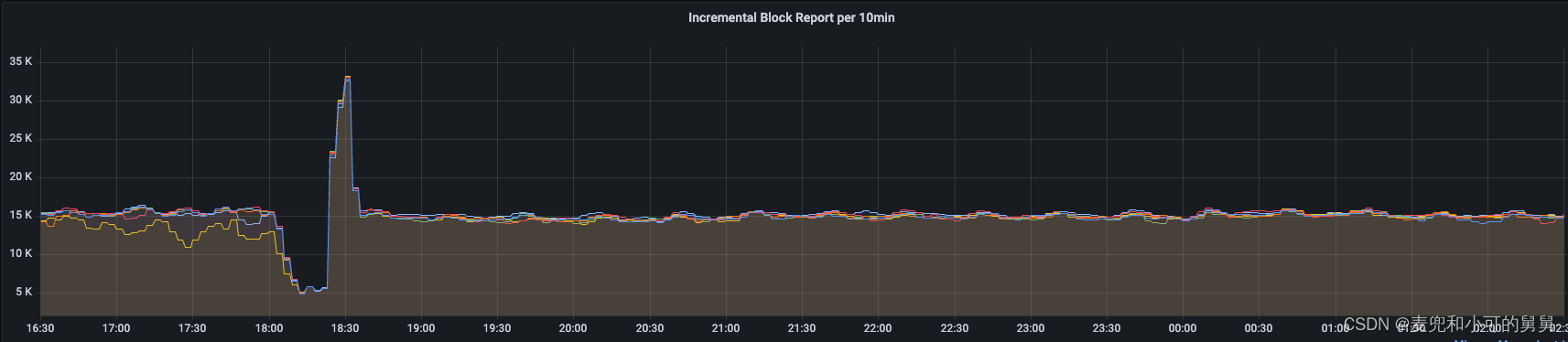
下图显示了DataNode端IncrementalBlockReport在单位时间内的数量以及平均的相应时间:
每10分钟完成的IncrementalBlockReport的数量:
IncrementalBlockReport完成所需要的时间:
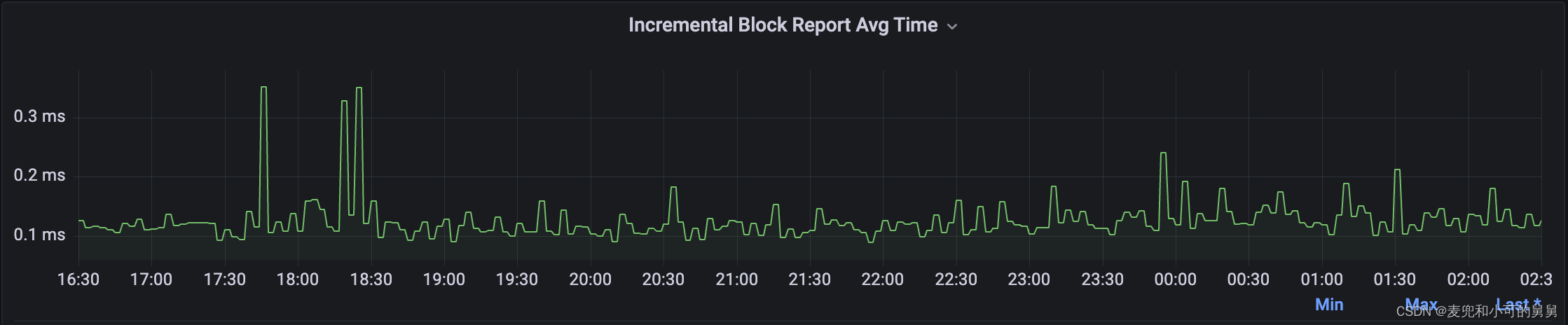
可以看到,在事故发生的十几分钟(18:05 ~ 18:23)期间,整个集群所有的DataNode在单位时间内完成的IncrementalBlockReport的次数在降低,同时每个IncrementalBlockReport的平均时间变长。IBR的降低时间与NameNode端文件和Block的快速降低时间是完全吻合的。
而在NameNode端,BlockReceivedAndDeleted就是从DataNode的IncrementalBlockReport中收到的已经被DataNode删除的Block,可以看到,这个数量在事故发生期间也同样下降了:
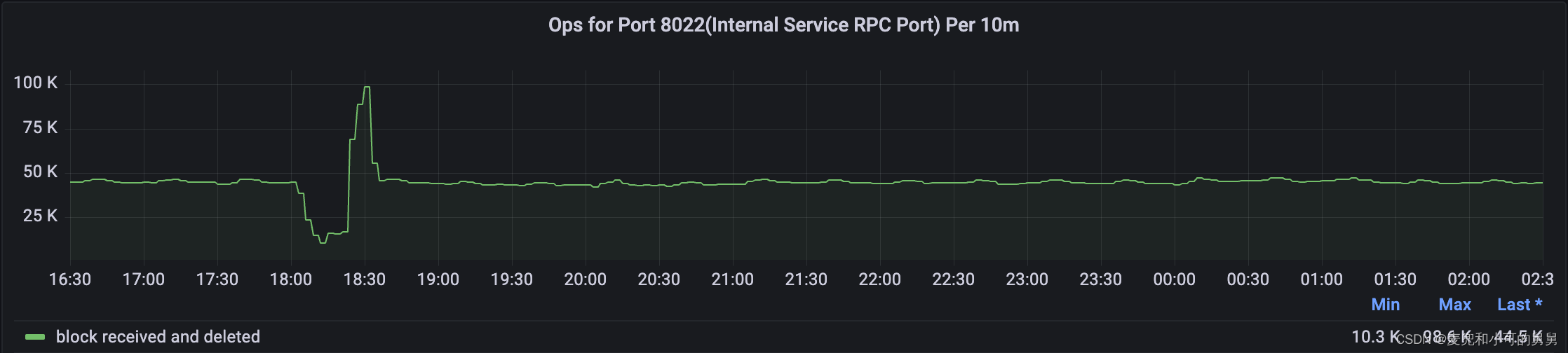
IncrementalBlockReport频率降低、IBR的平均耗时增加、NameNode端通过IBR收到的BlockReceivedAndDeleted的单位时间的数量降低的原因是:
对于已经建立好的ReplicaFileDeleteTask, DataNode通过一个数量有限的线程池(下面会讲到DataNode的实际物理删除) 来执行ReplicaFileDeleteTask以进行删除操作,每实际物理删除一个replica,就会添加到一个待通知的队列中,下次心跳,这个已经物理删除的Replica就会发送给NameNode(实际上也是按照batch发送给NameNode的,而不是每删除一个Replica就告知NameNode一次):
------------------------------------- FsDatasetAsyncDiskService --------------------------------
@Override
public void run() {
long dfsBytes = blockFile.length() + metaFile.length();
boolean result;
// 执行物理删除
result = (trashDirectory == null) ? deleteFiles() : moveFiles();
if(block.getLocalBlock().getNumBytes() != BlockCommand.NO_ACK){
// 这里不是直接通知,而是先添加到IncrementalBlockReportManager中保存,下次IBR的时候发送
datanode.notifyNamenodeDeletedBlock(block, volume.getStorageID());
}
volume.decDfsUsed(block.getBlockPoolId(), dfsBytes);
}
}
NameNode收到IBR以后,会更新BlockReceivedAndDeletedOps的Metrics,这个NameNode端的metrics代表实际已经从DataNode物理删除的Block数量:
---------------------------------------- NamenodeRpcServer --------------------------------
@Override // DatanodeProtocol
public void blockReceivedAndDeleted(final DatanodeRegistration nodeReg,
String poolId, StorageReceivedDeletedBlocks[] receivedAndDeletedBlocks)
throws IOException {
checkNNStartup();
verifyRequest(nodeReg);
metrics.incrBlockReceivedAndDeletedOps(); // 更新 BlockReceivedAndDeletedOps的metrics
final BlockManager bm = namesystem.getBlockManager();
for (final StorageReceivedDeletedBlocks r : receivedAndDeletedBlocks) {
bm.enqueueBlockOp(new Runnable() {
@Override
public void run() {
namesystem.processIncrementalBlockReport(nodeReg, r); // 这里会加FSNamesystem写锁
}
});
}
}
我们看到,processIncrementalBlockReport()处理IBR的时候,会加FSNamesystem写锁:
--------------------------------------- FSNamesystem --------------------------------------
public void processIncrementalBlockReport(final DatanodeID nodeID,
final StorageReceivedDeletedBlocks srdb)
throws IOException {
writeLock();
try {
blockManager.processIncrementalBlockReport(nodeID, srdb);
} finally {
writeUnlock();
}
}
Heartbeat
除了IBR,我们也统计了NameNode端每10min收到DataNode端的心跳次数,其在事故发生期间也降到很低。
下面的Panel展示了每10分钟NameNode收到DataNode的心跳次数: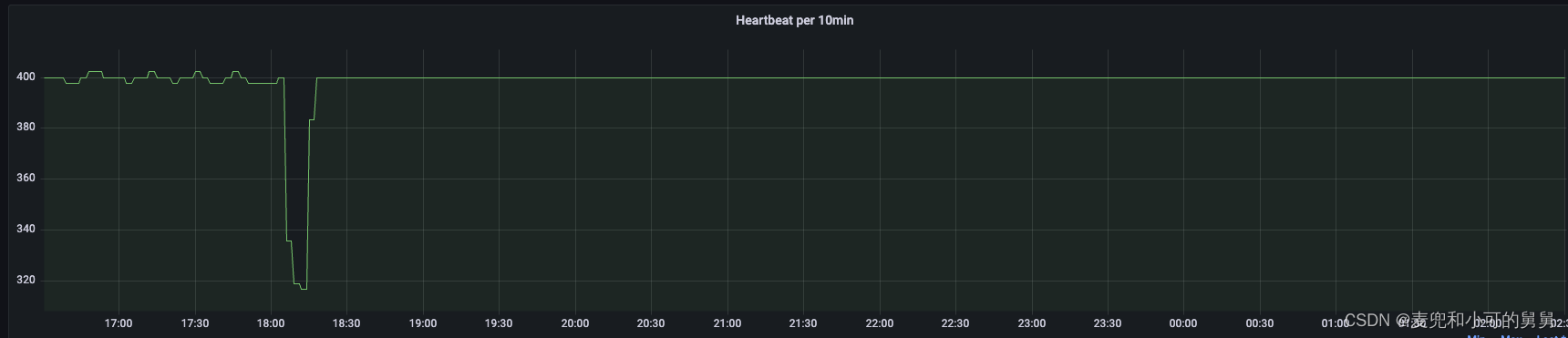
代码层面我们可以看到,心跳的处理与文件的删除同样存在锁争用:
-
NameNode端在处理心跳的时候,会添加FSNamesystem的读锁。这意味着,如果此时FSNamesystem已经被Trash清空的操作带来的写锁频繁占用并相互争用,那么Heartbeat在Namenode端就需要等待:
---------------------------------------- FSNameSystem ------------------------------------ HeartbeatResponse handleHeartbeat(DatanodeRegistration nodeReg,.....e) throws IOException { readLock(); // FSNamesystem的读锁 try { //get datanode commands final int maxTransfer = blockManager.getMaxReplicationStreams() - xmitsInProgress; DatanodeCommand[] cmds = blockManager.getDatanodeManager().handleHeartbeat( nodeReg, reports, blockPoolId, cacheCapacity, cacheUsed, xceiverCount, maxTransfer, failedVolumes, volumeFailureSummary);对应堆栈如下所示:

-
NameNode端收到了DataNode的heartbeat以后除了会加FSNamesystem的读锁,还会在
InvalidateBlocks.getInvalidateBlocks()方法从invalidateBlocks中取出指定数量的Block放到Response中,这个过程中需要加invalidateBlocks对象锁:------------------------------ DatanodeDescriptor(in NameNode) ------------------------------ /** * Remove the specified number of blocks to be invalidated */ public Block[] getInvalidateBlocks(int maxblocks) { synchronized (invalidateBlocks) { Block[] deleteList = invalidateBlocks.pollToArray(new Block[Math.min( invalidateBlocks.size(), maxblocks)]); return deleteList.length == 0 ? null : deleteList; } }其对应堆栈如下所示:

-
NameNode端在删除一个INode和对应的Block的时候,会通过方法 InvalidateBlocks.add() 往BlockManager中的InvalidateBlocks中添加待删除的Block的时候需要,添加InvalidateBlocks对象锁。同时,结合下面的调用堆栈,我们知道,add()方法的上层调用者比如FSNamesystem.deleteBlocks()方法还会加FSNamesystem的写锁:
--------------------------------------- InvalidateBlocks -------------------------------- /** * Add a block to the block collection * which will be invalidated on the specified datanode. * 这是一个同步方法 */ synchronized void add(final Block block, final DatanodeInfo datanode, final boolean log) { // 或者这个datanode的所有的block LightWeightHashSet<Block> set = node2blocks.get(datanode); if (set == null) { // 还没有这个DataNode的信息 set = new LightWeightHashSet<Block>(); node2blocks.put(datanode, set); } if (set.add(block)) { // 将这个block添加到这个datanode的blockset中去 numBlocks++; // invalidate block的数量+1 } }调用堆栈如下所示:

因此可以看到,NameNode端对Block的删除操作,和NameNode处理来自DataNode的心跳并将待删除的Replica放入心跳响应的操作存在锁竞争。因此,Heartbeat的频率在NameNode执行文件(INode)和块(Block)删除过程中频率逐渐降低。
综上所述,在18:06 ~ 18:23的事故发生期间,NameNode端在执行块删除阶段,由于删除操作同IBR以及Heartbeat都存在锁争用,IBR和Heartbeat的频率降低,NameNode收到因此,这样的因果关系形成:
- 由于锁争用,DataNode完成一次heartbeat和IBR的时间增加,因此heartbeat和IBR频率降低
- heartbeat和IBR的频率降低,那么单位时间内,DataNode从NameNode端领取(通过heartbeat响应)的需要invalidate的块数量降低,所以DataNode端单位时间内可删除的块数量很低
- 汇报给NameNode的BlockReceivedAndDeleted降低
DataNode端块删除行为分析
当DataNode通过心跳响应,收到了来自于NameNode的删除块的命令,即
DatanodeProtocol.DNA_INVALIDATE,会调用FSDatasetImpl.invalidate()方法来执行对应的删除(其实是异步删除):
-------------------------------------------- BPServiceActor -------------------------------------------
private boolean processCommandFromActive(DatanodeCommand cmd,
BPServiceActor actor) throws IOException {
.....
case DatanodeProtocol.DNA_INVALIDATE: // 删除Block的时候发生
Block toDelete[] = bcmd.getBlocks();
// using global fsdataset // 这里会加FSDatasetImpl锁
dn.getFSDataset().invalidate(bcmd.getBlockPoolId(), toDelete);
dn.metrics.incrBlocksRemoved(toDelete.length); // 这里记录删除的块的数量的metrics
------------------------------------------ FSDatasetImpl ---------------------------------------------------
public void invalidate(String bpid, Block invalidBlks[]) throws IOException {
final List<String> errors = new ArrayList<String>();
for (int i = 0; i < invalidBlks.length; i++) {
final File f;
final FsVolumeImpl v;
// 这里是同步方法,加 FsDatasetImpl锁
synchronized (this) {
final ReplicaInfo info = volumeMap.get(bpid, invalidBlks[i]);
.....
ReplicaInfo removing = volumeMap.remove(bpid, invalidBlks[i]);
addDeletingBlock(bpid, removing.getBlockId());
asyncDiskService.deleteAsync(v.obtainReference(), f,
FsDatasetUtil.getMetaFile(f, invalidBlks[i].getGenerationStamp()),
new ExtendedBlock(bpid, invalidBlks[i]),
dataStorage.getTrashDirectoryForBlockFile(bpid, f));
}
}
从代码可以看到其基本步骤:
- 获取待删除的块,为其创建异步的删除任务:
Block toDelete[] = bcmd.getBlocks(); // using global fsdataset // 这里会加FSDatasetImpl锁 dn.getFSDataset().invalidate(bcmd.getBlockPoolId(), toDelete); - 提交删除任务。即使短时间内有大量Block的需要删除,但是执行删除任务的并发被严格控制在4 threads per volume,pending的删除任务挂载在thread pool的任务队列中:
dn.getFSDataset().invalidate(bcmd.getBlockPoolId(), toDelete); - 记录对应的metrics信息
dn.metrics.incrBlocksRemoved(toDelete.length); // 这里记录删除的块的数量的metrics
上文已经讲过,DataNode Removed Blocks Num Per 10m 这个DataNode面板的准确含义是:DataNode从NameNode端拿到的Invalidated block并且已经创建了对应的ReplicaFileDeleteTask任务的Block的数量,不代表这些Block的确已经在DataNode上物理删除,因为这些Block对应的ReplicaFileDeleteTask任务不一定已经开始执行,更不一定执行完毕。
我们查看asyncDiskService.deleteAsync()方法,可以看到DataNode为每一个待删除的Replica创建了一个ReplicaFileDeleteTask,然后提交给一个线程池执行:
/**
* Delete the block file and meta file from the disk asynchronously, adjust
* dfsUsed statistics accordingly.
*/
void deleteAsync(FsVolumeReference volumeRef, File blockFile, File metaFile,
ExtendedBlock block, String trashDirectory) {
ReplicaFileDeleteTask deletionTask = new ReplicaFileDeleteTask(
volumeRef, blockFile, metaFile, block, trashDirectory);
execute(((FsVolumeImpl) volumeRef.getVolume()).getCurrentDir(), deletionTask);
}
为每一个Volume添加一个ThreadPool进行删除,其中MAXIMUM_THREADS_PER_VOLUME=1,MAXIMUM_THREADS_PER_VOLUME=4且不可配置,即DataNode端为每一个Volume设置了一个最大4个线程的线程池执行删除操作:
private void addExecutorForVolume(final File volume) {
ThreadFactory threadFactory = new ThreadFactory() {
int counter = 0;
@Override
public Thread newThread(Runnable r) {
......
}
};
// 对于每一个Volume,并发严格控制在4,pending的任务挂载在LinkedBlockingQueue中
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_THREADS_PER_VOLUME, MAXIMUM_THREADS_PER_VOLUME,
THREADS_KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(), threadFactory);
// This can reduce the number of running threads
executor.allowCoreThreadTimeOut(true);
executors.put(volume, executor);
}
所以,其实DataNode端对于来自于NameNode的待删除块的爆发式增长,进行了很好的速率控制,无论突然有多少待删除块,每个Volume都只会安排4个并发线程进行物理删除,这是一个非常稳定且低频的操作。在事故刚发生、还没有进行仔细的时间线分析的时候,我们很容易认为大量的删除操作对HDFS的那20分钟左右的影响应该是来自DataNode的磁盘瓶颈。但是在看到了时间线(DataNode 进行物理删除实际上持续了7个小时,并且代码也证明DataNode进行物理删除的时候严格控制并发)以后,我们清除地知道,瓶颈不在DataNode和磁盘。
客户端读写吞吐变化分析
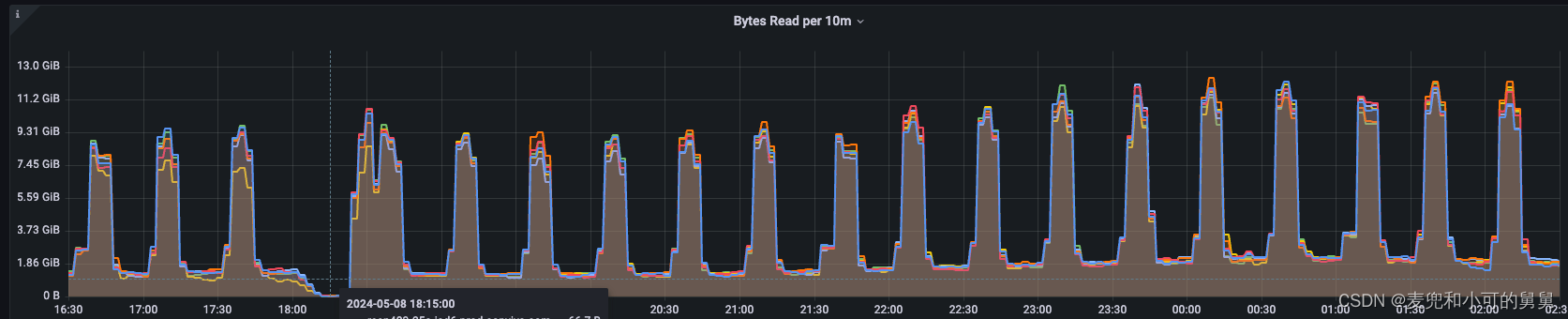
先看写流量的变化。
下图显示了在事故发生的十几分钟(18:05 ~ 18:23)期间,我们从DataNode端采集到写吞吐量是在下降的。事故过去以后,写吞吐有一个短暂的高峰,这个高峰看起来是某种锁或者其他阻塞因素消失以后的压力释放过程:
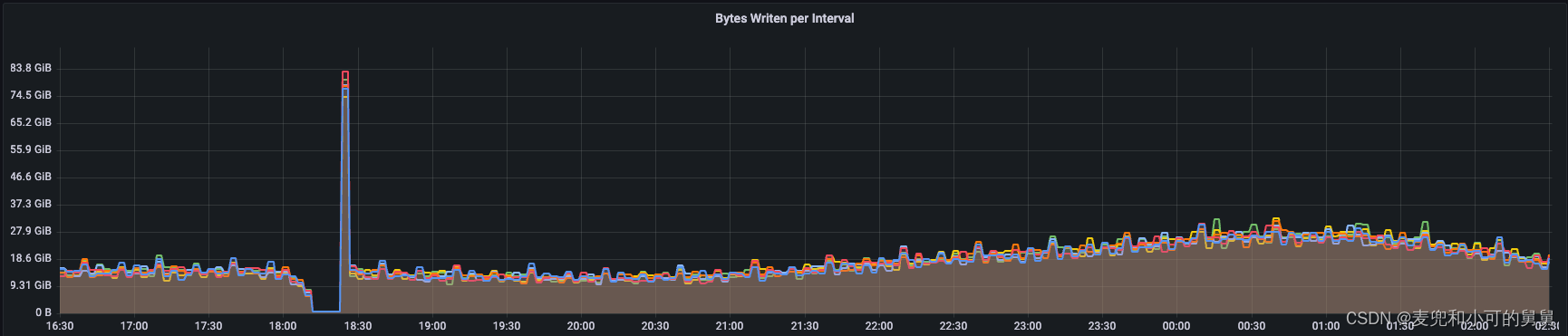
同时,HDFS用户反馈读写已经无法正确进行,因此对用户产生影响。
在我的HDFS的EC(Erasure Coding,纠删码)和块管理这篇文章中讲过写文件的基本过程。其中与NameNode交互的过程主要是包含了两个部分,打开文件的过程和申请Block的过程。我们从代码中可以看到,这两个过程会频繁用到FSNamesystem的读写锁以及FSDirectory的全局读写锁,因此,假如此NameNode正在进行回收站的文件的清空操作,会频繁对FSNamesystem加写锁,从而影响到客户端的写过程:
- 写文件的第一步是创建文件,会通过
NamenodeRpcServer.create(),实际上会调用FSNamesystem.startFile()方法:
向FSDirectory中添加文件:----------------------------------------------- FSNamesystem --------------------------------------------- HdfsFileStatus startFile(String src, PermissionStatus permissions, .....) status = startFileInt(src, permissions, holder, clientMachine, flag, createParent, replication, blockSize, supportedVersions, cacheEntry != null); return status; } private HdfsFileStatus startFileInt(final String srcArg,......) { ....... if (provider != null) { readLock(); // 路径解析,因此加读锁 try { src = dir.resolvePath(pc, src, pathComponents); INodesInPath iip = dir.getINodesInPath4Write(src); //根据文件的数据路径,解析出文件的全路径INode ..... } finally { readUnlock(); } } writeLock(); // 开始创建文件,即添加对应的INode信息,需要使用FSDirectory,同时FSNamesystem也需要加写锁 try { .... src = dir.resolvePath(pc, src, pathComponents); toRemoveBlocks = startFileInternal(pc, src, permissions, holder, clientMachine, create, overwrite, createParent, replication, blockSize, isLazyPersist, suite, protocolVersion, edek, logRetryCache); stat = dir.getFileInfo(src, false, FSDirectory.isReservedRawName(srcArg), true); } finally { writeUnlock(); } return stat; } private BlocksMapUpdateInfo startFileInternal(FSPermissionChecker pc....) { assert hasWriteLock(); // 确保这个方法的调用必须已经加了读锁 .... INodeFile newNode = null; // 这里还会加FSDirectory的写锁,以添加INode信息 newNode = dir.addFile(src, permissions, replication, blockSize, holder, clientMachine); ... leaseManager.addLease(newNode.getFileUnderConstructionFeature() .getClientName(), newNode.getId()); // 添加文件租约 ...... return toRemoveBlocks; } }----------------------------------------------- FSDiretory ----------------------------------------------- INodeFile addFile(String path, PermissionStatus permissions ....) { .... writeLock(); try { added = addINode(path, newNode, permissions.getPermission()); } finally { writeUnlock(); } - 写文件的第二步是申请文件块,这是通过
NameNodeRpcServer.addBlock()接口完成的,实际上是调用FSNamesystem.getAdditionalBlock()来添加Block,包括先创建逻辑Block,然后通过PlacementPolicy选定具体副本的物理位置:
在getAdditionalBlock()方法主要分成了三个步骤,1)文件校验,2)副本位置选择, 3)块的创建,在步骤1中对文件路径进行分析的过程中加FSNamesystem读锁然后释放,同时,在创建完Block以后更新BlocksMap等信息的时候加FSNamesystem写锁然后释放:---------------------------------- NamenodeRpcServer -------------------------------------- @Override public LocatedBlock addBlock(String src, String clientName, ExtendedBlock previous, DatanodeInfo[] excludedNodes, long fileId, String[] favoredNodes, EnumSet<AddBlockFlag> addBlockFlags) throws IOException { List<String> favoredNodesList = (favoredNodes == null) ? null : Arrays.asList(favoredNodes); LocatedBlock locatedBlock = namesystem.getAdditionalBlock(src, fileId, clientName, previous, excludedNodesSet, favoredNodesList, addBlockFlags); return locatedBlock; }
在---------------------------------------------- FSNamesystem ----------------------------------------------------- LocatedBlock getAdditionalBlock(String src, long fileId) { // 步骤1. Analyze the state of the file with respect to the input data. byte[][] pathComponents = FSDirectory.getPathComponentsForReservedPath(src); FSPermissionChecker pc = getPermissionChecker(); readLock(); // 上读锁,因为此时需要读取文件块的具体信息,以指导块的创建 try { src = dir.resolvePath(pc, src, pathComponents); LocatedBlock[] onRetryBlock = new LocatedBlock[1]; FileState fileState = analyzeFileState( src, fileId, clientName, previous, onRetryBlock); final INodeFile pendingFile = fileState.inode; src = fileState.path; blockSize = pendingFile.getPreferredBlockSize(); clientMachine = pendingFile.getFileUnderConstructionFeature() .getClientMachine(); clientNode = blockManager.getDatanodeManager().getDatanodeByHost( clientMachine); replication = pendingFile.getFileReplication(); storagePolicyID = pendingFile.getStoragePolicyID(); } finally { readUnlock(); } // 步骤2 为这个逻辑块选定物理目标节点,此时只是选择节点,还没有创建逻辑Block,也没有将分配的节点绑定到Block上 final DatanodeStorageInfo targets[] = getBlockManager().chooseTarget4NewBlock( src, replication, clientNode, excludedNodes, blockSize, favoredNodes, storagePolicyID, flags); // 步骤3 创建一个block,并且将这个Block添加到INode中和BlocksMap中 Block newBlock = null; writeLock(); // 上写锁,因为申请了新的块,因此需要更新INode的块信息,以及更新BlocksMap中的块信息 try { ..... FileState fileState = analyzeFileState(src, fileId, clientName, previous, onRetryBlock); final INodeFile pendingFile = fileState.inode; src = fileState.path; ..... // commit the last block and complete it if it has minimum replicas commitOrCompleteLastBlock(pendingFile, ExtendedBlock.getLocalBlock(previous)); // allocate new block, record block locations in INode. newBlock = createNewBlock(); // 创建一个逻辑block // 步骤4 将文件和块、以及块的位置信息分别添加给INode和BlocksMap中 INodesInPath inodesInPath = INodesInPath.fromINode(pendingFile); // 获取刚刚创建的这个文件的全路径INodes信息 // 在这里会将对应的Block,targets信息添加到FSDirectory所管理的原信息中,包括添加到INode的blocks信息中,添加到BlocksMap中,因此也会加FSDirectory写锁 saveAllocatedBlock(src, inodesInPath, newBlock, targets); // 这里是写edit log,以将对应信息持久化 persistNewBlock(src, pendingFile); offset = pendingFile.computeFileSize(); } finally { writeUnlock(); } getEditLog().logSync(); // 最后一步,返回结果 return makeLocatedBlock(newBlock, targets, offset); }FSNamesystem.saveAllocatedBlock()中,会调用FSDirectory.addBlock()方法,将对应的Block添加到BlockManager中并将Block添加到INode中:------------------------------------------- FSDirectory ------------------------------------------- BlockInfo addBlock(String path, INodesInPath inodesInPath, Block block, DatanodeStorageInfo[] targets) throws IOException { writeLock(); // 添加FSDirectory全局写锁,因为此时会将这个新的Block更新到INode中,同时会更新BlocksMap try { // associate new last block for the file BlockInfoUnderConstruction blockInfo = new BlockInfoUnderConstruction( block, fileINode.getFileReplication(), BlockUCState.UNDER_CONSTRUCTION, targets); // 将对应的block添加到BlocksMap中 getBlockManager().addBlockCollection(blockInfo, fileINode); // 将对应的block添加到对应的INode的块信息中 fileINode.addBlock(blockInfo); return blockInfo; } finally { writeUnlock();// 释放FSDirectory全局写锁 } }
下图的Metrics显示了客户端的读流量的变化。
从图中可以看到,这个HDFS的读流量基本上每半个小时一个周期的流量尖峰,而我们的事故发生的时间18:05 ~ 18:23的故障时间刚好落入了对应的流量尖峰,导致这个读流量尖峰没有出现,读流量在此期间变得极低:
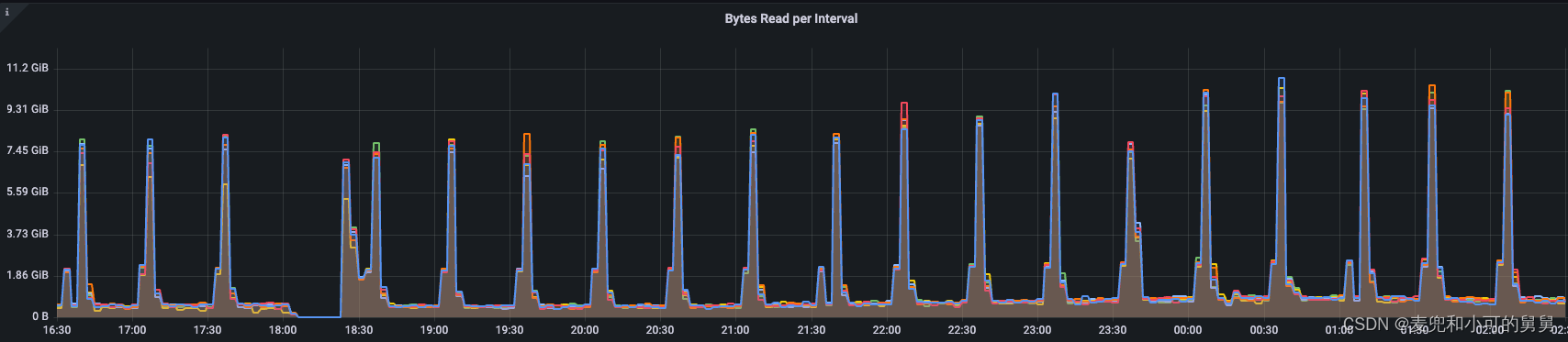
客户端在读取数据的时候,会根据当前的offset信息,向NameNode请求对应的Block信息。这是通过NamenodeRpcServer.getBlockLocation()接口完成的。我们看到,获取一个文件的Block的Location,会上FSNamesystem的全局对象锁,最终是通过BlockManager.createLocatedBlocks()方法完成的:
----------------------------------------- FSNamesystem --------------------------------------
/**
* Get block locations within the specified range.
* @see ClientProtocol#getBlockLocations(String, long, long)
*/
LocatedBlocks getBlockLocations(String clientMachine, String srcArg,
long offset, long length) throws IOException {
......
readLock(); // 读取的时候,加FSNamesystem读锁
try {
res = getBlockLocations(pc, srcArg, offset, length, true, true);
} finally {
readUnlock(); // 读取完成,释放FSNamesystem读锁
}
所以,读文件的过程主要涉及到获取文件的块位置信息,在NameNode端,这个过程需要加FSNamesystem的读锁,显然,这个读锁与文件删除过程中FSNamesystem的写锁存在锁争用。因此,事故发生过程中,本应该规律发生的读峰值没有产生,读流量变得很低,读操作受到影响。
DataNode端XCeiver和线程数量变化分析
我们单独将XCeiver的数量拿出来分析是因为它比较特殊:事故发生过程中,伴随着读写流量由于锁争用而降低,XCeiver却是在不断增加的过程,这两种现象看起来似乎是矛盾的。
总的说来,在事故发生期间,以下事件在时间上完全吻合:
- XCeiver数量逐渐增加
- DataNode端的线程数量逐渐增加,增加的线程主要状态是Runnable状态(注意不是Blocked阻塞状态)和小部分的Waiting状态
- 数据的读写吞吐处在一个极低的水平
DataNode端 XCeiver、Threads数量变化、读写吞吐变化如下图所示:
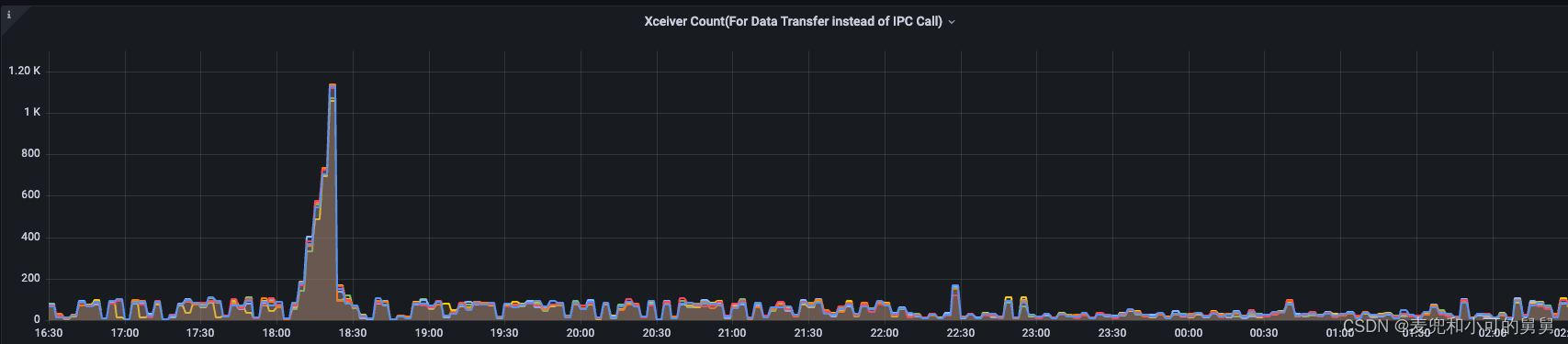
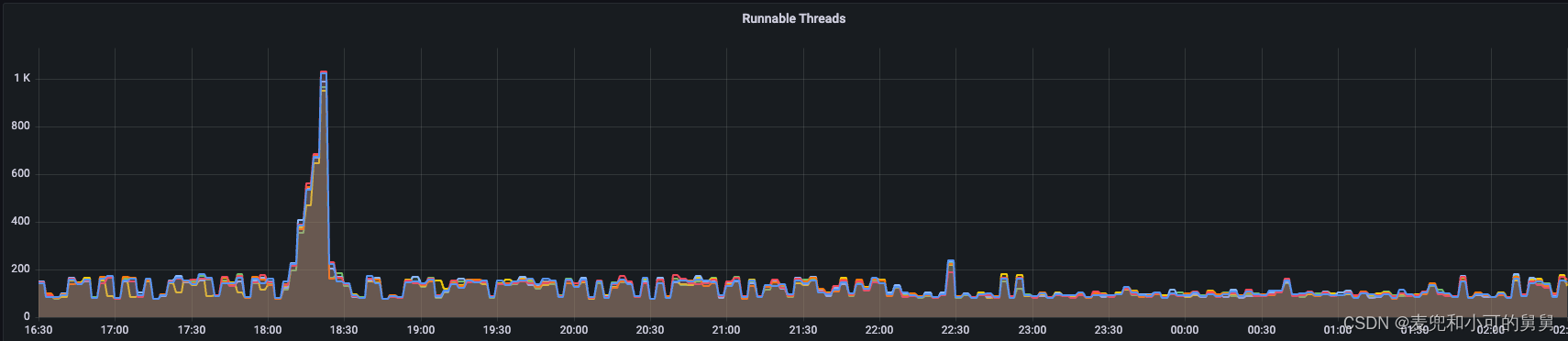
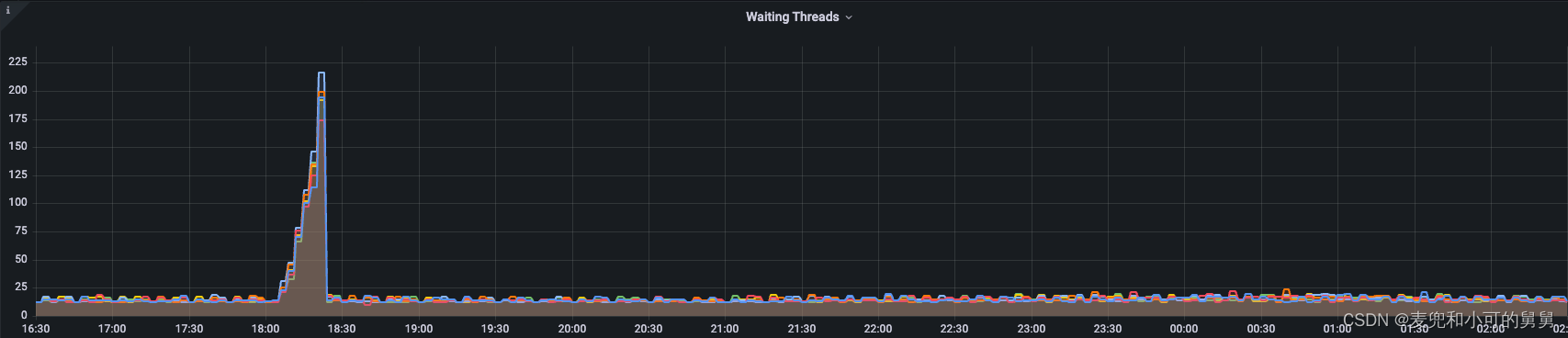
由于事故发生的时间很短,我们当时我们并没有来得及保存事故发生时候的DataNode堆栈,但是,看到线程数量的增加,我们有理由认为,这些线程是DataNode用来删除突然产生的、大量的块文件的任务线程,因此,DataNode的IO负载是系统瓶颈。
但是当我们详细查看了事故发生的十几分钟期间的磁盘负载和CPU负载,我们发现非常平稳,而且我们也看到DataNode端的删除过程其实持续了7个小时,因此物理删除的时间跨度和线程暴增的时间跨度不一致,所以,线程数量的骤增并不是删除文件的线程暴增引起的。
由于事故发生期间的Xceiver数量剧增,其发生时间和线程数量的暴增时间完全一致(都是在18:05 ~ 18:23 期间发生),同时,这个Xceiver的增加数量差不多等于Runnable线程的数量和Waiting线程的数量。逐渐,我们才认识到,说明这些增加的线程其实是来自于XCeiver,即用来处理用户读写的线程池中的线程的剧增,而不是负责块删除的线程。上文也讲过,代码显式,DataNode对删除任务的并发控制是很严格的。
我们看一下XCeiver这个metrics的源码。
在DataNode端,会有一个唯一的DataXCeiverServer以一个独立线程的方式启动监听端口,监听客户端的读写请求,其本身是一个Runnable:
--------------------------------------------- DataXceiverServer --------------------------------
class DataXceiverServer implements Runnable {
.....
DataXceiverServer(PeerServer peerServer, Configuration conf,
DataNode datanode) {
this.peerServer = peerServer;
this.datanode = datanode;
在DataNode启动的时候,会将DataXceiverServer启动,负责监听客户端的读写请求:
------------------------------------------ DataNode -------------------------------------------
private void initDataXceiver(Configuration conf) throws IOException {
....
this.threadGroup = new ThreadGroup("dataXceiverServer"); //这是专门给DataXCeiver用的ThreadGroup,所有的DataXCeiver放在一个group中,方便统计和计数
xserver = new DataXceiverServer(tcpPeerServer, conf, this);
this.dataXceiverServer = new Daemon(threadGroup, xserver);
this.threadGroup.setDaemon(true); // auto destroy when empty
}
DataXceiverServer.run()方法就是在指定端口上监听客户端请求,一旦有请求过来,即创建一个独立线程处理用户请求,这个独立线程的实现类是DataXceiver,这种线程都放在同一个ThreadGroup中以方便进行数量统计:
@Override
public void run() {
Peer peer = null;
while (datanode.shouldRun && !datanode.shutdownForUpgrade) {
try {
peer = peerServer.accept();
.....
//
new Daemon(datanode.threadGroup,
DataXceiver.create(peer, datanode, this))
.start();
} ....
}
从上面的代码可以看到:
- DataXceiverServer.run()会阻塞式监听客户端连接(也有可能来自其他DataNode):
peer = peerServer.accept(); - 当有连接进来,则创建一个DataXceiver对象来专门处理这个连接请求。一个DataXceiver是一个Runnable实现。实际上创建的这个DataXceiver、对应的连接peer以及对应的ThreadGroup是被封装在一个叫做Daemon对象中的,这里不再赘述:
new Daemon(datanode.threadGroup, DataXceiver.create(peer, datanode, this)) .start();
我们在监控中看到的xceiver数量,其实就是这个thread group中的活跃线程数,如下所示:
------------------------------------------------------- DataNode --------------------------------------------------
/** Number of concurrent xceivers per node. */
@Override // DataNodeMXBean
public int getXceiverCount() {
return threadGroup == null ? 0 : threadGroup.activeCount();
}
显然,这个剧增不可能是由于实际上客户端的访问量剧增引起的,显然也是与当前的incident相关。
从上面的代码,可以看到Xceiver代表了客户端和Namenode之间读写数据的存活的线程数量,可以理解成客户端读写的连接数。因此,我们怀疑的思路有两个:
- DataNode本身也存在类似于NameNode的一些全局锁控制,客户端正常向DataNode写入数据需要获得该锁,但是在incident发生的十几分钟内,DataNode由于暴增的Block删除任务,该锁被长期占用。
- DataNode本身并没有性能下降或者锁的阻挡,虽然客户端已经正常写入比如一个Block的数据到DataNode,但是由于需要NameNode的某种最终确认以后客户端才能关闭和DataNode的连接。但是此时NameNode由于FSNamesystem和FSDirectory的锁控制而无法给出对应响应。
我们最后的结论其实是第二个。
我们排除DataNode端的锁控制导致了DataXceiver的升高以及读写吞吐的降低的原因有:
- DataNode端通过心跳获取待删除的块,整个过程持续了7个小时,而Xceiver骤增只发生在很短的十几分钟内。因此时间不匹配;
- 并且,DataNode端的锁的确会在Heartbeat和用户正常读写之间带来争用,但是下面我们会讲到,这种争用仅仅是发生在客户端和DataNode建立连接、最后需要关闭连接的过程中,在真正数据传输过程中不会需要这个锁。因此,锁的影响应该微乎其微;
- 如果是锁争用(synchronized)导致的读写吞吐降低和XCeiver升高,那么对应的线程的状态应该大部分是Blocked状态,但是我们看到,暴增的线程是由大部分的Runnable和小部分的Waiting组成,Blocked状态的基本没有,如下图所示:
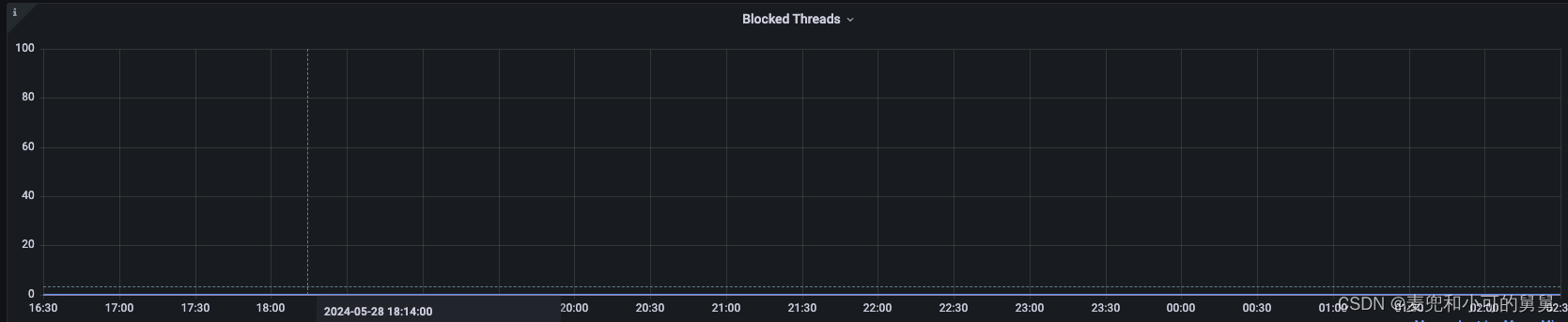
- 大量Xceiver线程处于Runnable状态,但是整个读写吞吐却处于一个极低的水平,这种状态看起来更像是一种空转,即连接保持存活,但是客户端似乎在做其他的事情而没有读或者写数据。
那么,第二种猜测所对应的事故过程具体是怎么产生的呢?
我们遇到的第一个问题是,客户端在读写过程中,假如向一个DataNode写完一个Block,这个读写连接是否会立刻关闭?这个问题的答案直接决定了我们的推理是否和现象匹配,这是因为:
- 假设客户端读写完一个Block就会关闭和DataNode之间的连接,即,1) 向NameNode申请Block,获取Block的Location,2) 和DataNode建立连接并开始写入 3) 关闭和DataNode的连接 4) 和NameNode通信以告知文件或者块写入完毕,步骤1和步骤4由于NameNode端的锁争用而变得很慢,但是,2和3的整个过程都只是和DataNode通信,因此和DataNode之间的连接保持过程完全不受影响(读写完成即关闭),不应该造成DataNode上的空转的XCeiver增加的问题。
- 假设客户端读写完一个Block不会立刻关闭DataNode之间的连接,而是保持住这个Peer 连接(也许只是保持一段时间,主要是出于性能考虑,避免重复创建和关闭连接带来的开销),那么,由于NameNode端的锁争用,客户端在完成了DataNode的写数据以后,由于需要和NameNode通信才能继续后面的(比如关闭当前文件、打开下一个文件等)读写操作,而NameNode的阻塞导致后面的操作无法继续进行,随着越来越多的读写客户端的建立(来自于Spark Job的所有Executor),这些连接越来越多,都无法正常关闭,对应了XCeiver越来越多,Runnable的空转线程越来越多,却没有实际的数据读写流量。
先看一下DataNode服务器端的连接管理。
首先,我们说过,一个DataXceiver线程就是一个连接,其run()方法就是具体的运行逻辑:
public void run() {
int opsProcessed = 0;
Op op = null;
dataXceiverServer.addPeer(peer, Thread.currentThread(), this);
socketOut = saslStreams.out;
..
do {
op = readOp();
// restore normal timeout
if (opsProcessed != 0) {
peer.setReadTimeout(dnConf.socketTimeout);
}
opStartTime = now();
processOp(op);
++opsProcessed;
} while ((peer != null) &&
(!peer.isClosed() && dnConf.socketKeepaliveTimeout > 0));
}
从上面打开可以看到, 一个DataXCeiver 线程是一个循环操作,用来反复处理来自客户端的各种op,如果客户端不主动关闭连接,或者这个连接timeout,那么Server端就不会主动关闭这个连接:
do {
......
} while ((peer != null) &&
(!peer.isClosed() && dnConf.socketKeepaliveTimeout > 0));
}
那么,客户端的行为是什么样的呢?
我们从代码中发现,写入过程的客户端是在完成了一个Block的写入以后立刻关闭的,而读取过程的客户端是通过缓存管理的,保证一个HDFS客户端进程(一个Spark Executor)和一个DataNode之间的Peer Connection是公用的。
-
对于写操作,整个和DataNode通信的过程是在类DFSOutputStream类中。
- 一个DFSOutputStream对象代表了一个文件的写入操作,DFSOutputStream会调用addBlock()接口,向NameNode获取对应的块的Location信息,然后将具体的数据发送工作交付给对应的DataStreamer对象;
- 一个DataStreamer对象代表了一个Block的写入操作,DataStreamer会负责将这个Block的数据以带编号的Packet为单位、以流水线的方式发送给远程的DataNode,并通过检查ack确认发送的数据的完整性;
- 具体的和DataNode建立Socket连接则是交给StreamerStreams。StreamerStreams在构造的时候,会建立和DataNode的Socket连接和对应的OutputStream/InputStream :
然后上层的DataStreamer会通过StreamerStreams发送数据,如下所示。从finally代码块可以看到,一个block发送完毕以后,立刻关闭了socket连接(注意是关闭了socket连接,而不仅仅是关闭了InputStream/OutputStream)------------------------------------------------ StreamerStreams ------------------------------------------------- StreamerStreams(final DatanodeInfo src, final long writeTimeout, final long readTimeout, final Token<BlockTokenIdentifier> blockToken) throws IOException { sock = createSocketForPipeline(src, 2, dfsClient); // 建立和DataNode对应的socket连接 .... out = new DataOutputStream(new BufferedOutputStream(unbufOut, HdfsConstants.SMALL_BUFFER_SIZE)); in = new DataInputStream(unbufIn); // 创建对应的输入输出流 }------------------------------------------------ StreamerStreams ------------------------------------------------- private void transfer(final DatanodeInfo src, final DatanodeInfo[] targets, final StorageType[] targetStorageTypes, final Token<BlockTokenIdentifier> blockToken) throws IOException { //向DataNode传输数据 do { StreamerStreams streams = null; try { streams = new StreamerStreams(src, writeTimeout, readTimeout, blockToken); streams.sendTransferBlock(targets, targetStorageTypes, blockToken); return; } finally { IOUtils.closeStream(streams); // 关闭socket } } while (policy.continueRetryingOrThrow()); }------------------------------------------------ StreamerStreams ------------------------------------------------- @Override public void close() throws IOException { IOUtils.closeStream(in); // 关闭InputStream IOUtils.closeStream(out); // 关闭OutputStream IOUtils.closeSocket(sock); // 关闭socket连接,即完全断开连接 }
-
对于读操作,我们可以清晰看到,用户在构建DFSClient的时候,是构造了一个类似连接池的连接缓存。
- 和写操作对应,与DataNode进行交互以进行读操作,对应过程封装在DFSInputStream中。
- 当客户端需要读取某个Block(或者是从Block的某个位置开始读,即seek操作),DFSInputStream会委托BlockReaderFactory构造对应的BlockReader对象,一个BlockReader对象封装了和DataNode建立好的连接:
------------------------------------------ DFSInputStream ------------------------------------- private synchronized DatanodeInfo blockSeekTo(long target) throws IOException { .... while (true) { LocatedBlock targetBlock = getBlockAt(target, true); // 含有位置信息的Block ..... try { ... blockReader = new BlockReaderFactory(dfsClient.getConf()). setInetSocketAddress(targetAddr). ......... build(); // 构造BlockReader return chosenNode; } } }
-
其实是调用getRemoteBlockReaderFromTcp(远程读取)或者是getRemoteBlockReaderFromDomain(基于DomainSocket读取)创建连接:
---------------------------------------- BlockReaderFactory ---------------------------------- private BlockReader getRemoteBlockReaderFromTcp() throws IOException { BlockReader blockReader = null; while (true) { try { curPeer = nextTcpPeer(); // 从缓存获取连接 ..... peer = curPeer.peer; blockReader = getRemoteBlockReader(peer); // 返回封装了连接的BlockReader } -
nextTcpPeer()就是从缓存中获取对应连接。显然,这个缓存的key就是DataNode,value就是对应的Peer连接。如果和对应DataNode的连接在缓存中存在,那么就直接从缓存中重用该链接,否则,创建新链接(这个创建的新连接也会放回缓存中)。
---------------------------------------- BlockReaderFactory ---------------------------------- private BlockReaderPeer nextTcpPeer() throws IOException { if (remainingCacheTries > 0) { Peer peer = clientContext.getPeerCache().get(datanode, false); if (peer != null) { return new BlockReaderPeer(peer, true); // 缓存直接提供连接信息 } } // 缓存中不存在,创建连接 Peer peer = remotePeerFactory.newConnectedPeer(inetSocketAddress, token, datanode); return new BlockReaderPeer(peer, false); } -
连接池中的连接生命周期是基于过期时间的自动关闭,不是一个客户端使用完以后自动关闭。有兴趣的读者可以自行查看PeerCache的代码。
综上,可以看到,客户端在写数据和读数据的时候与DataNode之间的连接的管理方式不同,写数据的时候,每完成一个Block的写入,就会关闭连接,而读数据的时候采用连接池的方式来管理连接,以实现连接的重用。
我们查看出问题以前以及出问题过程中系统的读写吞吐规律,可以看到,事故发生的时间区间刚好落入了一个有规律发生的读高峰:
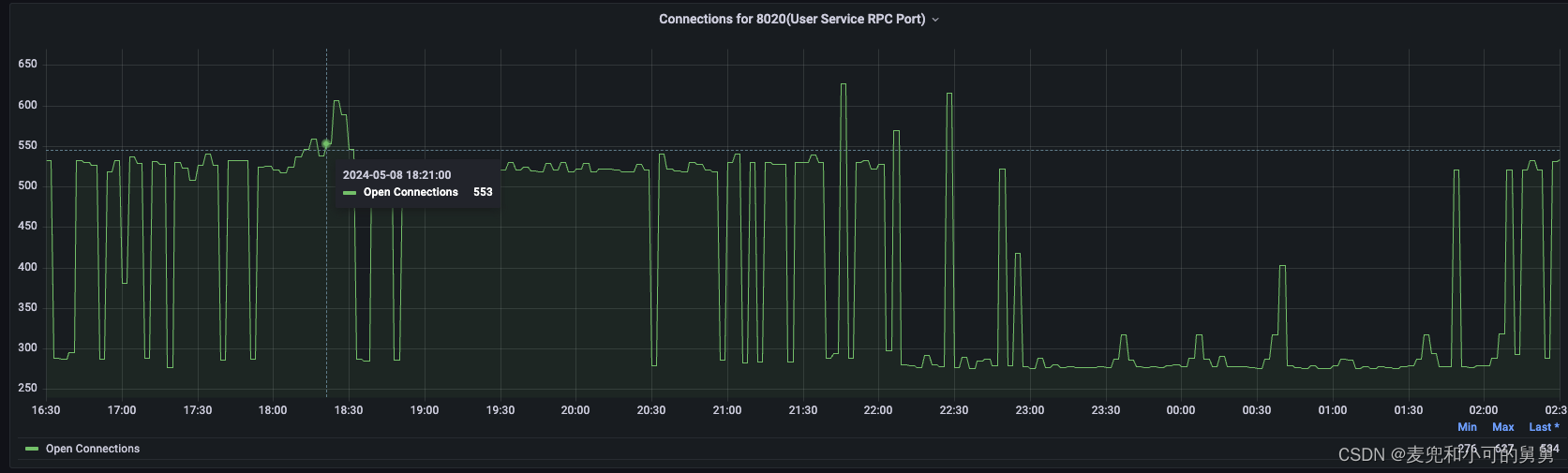
同时,我们也的确可以看到,事故发生的时候,客户端和NameNode的连接数也刚好有对应的尖峰,这和我们推测的由于多个无法正常关闭的客户端(Spark Executor)的堆积带来的DataNode端的XCeiver的堆积是一致的:
总而言之,我们对XCeiver的数量在事故期间陡增的原因总结为:
- 由于大部分的XCeiver线程不是BLOCKED状态,而是RUNNABLE和WAITING状态,因此排除了Datanode端的锁阻塞导致的问题
- 从客户端的读写规律看到,客户端半个小时一次的读流量高峰刚好落在了事故发生期间;
- 从代码分析来看,HDFS客户端读数据的时候使用了连接线程池以重用连接,当完成了一个Block的读操作,并不会立刻关闭与DataNode的连接,而是保持一段时间;
- 从代码分析来看,读操作在NameNode端存在和删除操作在FSNamesystem上的锁争用,读操作由于需要获取文件的块信息,因此需要加FSNamesystem的读锁;
- 由于NameNode端删除操作和客户端的读操作的锁争用,比如客户端在读取文件的时候,读完第一个文件的时候与一些DataNode建立的连接,在试图关闭文件的时候被NameNode端的锁争用阻塞,因此客户端与DataNode之间的连接的关闭只能依赖连接缓存(PeerCache)的自动过期,随着越来越多的读操作发生(客户端越来越多的读线程或者越来越多的读进程),越来越多的没有实际读写流的空转XCeiver保持住了。
DataNode端的锁控制
DataNode端的锁争用主要指的是从NameNode端认领并删除对应的块所需要的锁,和客户端的正常读写的锁之前的锁争用。
从上面的过程可以看到,DataNode对于从NameNode中收到的需要删除(invalidate)的块会逐个调用asyncDiskService.deleteAsync()进行异步删除,期间每处理一个块,就会上一个FSDatasetImpl的对象锁,当有大量的块需要删除的时候,针对FSDatasetImpl对象的频繁上锁、解锁的过程:
@Override // FsDatasetSpi
public void invalidate(String bpid, Block invalidBlks[]) throws IOException {
final List<String> errors = new ArrayList<String>();
for (int i = 0; i < invalidBlks.length; i++) {
final File f;
final FsVolumeImpl v;
synchronized (this) { // 对这一批待删除的块加FSDatasetImpl对象锁,
.....
// 执行异步删除,只是提交任务到线程池的任务队列,并不等待删除结束
asyncDiskService.deleteAsync(v.obtainReference(), f,
FsDatasetUtil.getMetaFile(f, invalidBlks[i].getGenerationStamp()),
new ExtendedBlock(bpid, invalidBlks[i]),
dataStorage.getTrashDirectoryForBlockFile(bpid, f));
}
.....
}
因此,我们的问题是,DataNode端删除操作对FSDatasetImpl加对象锁,是否会影响正常的客户端的读写呢?会。至少,从代码层面我们看到,因为客户端向DataNode写入数据的时候,需要加FSDatasetImpl对象锁。
上面说过,一个 DataXCeiver线程会负责一个客户端的读(READ_BLOCK)或者写(WRITE_BLOCK)请求,其中,读请求会交付给BlockSender进行处理,而写请求会交付给BlockReceiver进行处理。我们没有在BlockSender(读取数据)中发生对FSDatasetImpl的上锁过程,但是我们在BlockReceiver(写入数据)的构造的时候看到,会加FSDatasetImpl对象锁:
-------------------------------------------- Receiver -----------------------------------------------
protected final void processOp(Op op) throws IOException {
switch(op) {
case READ_BLOCK:
opReadBlock(); // 会调用DataXCeiver.readBlock()
break;
case WRITE_BLOCK:
opWriteBlock(in); // 会调用DataXCeiver.writeBlock()
break;
......
-------------------------------------------- DataXCeiver -------------------------------------------------
@Override
public void writeBlock(final ExtendedBlock block,
final StorageType storageType,......) throws IOException {
.......
blockReceiver = new BlockReceiver(block, storageType, in,
peer.getRemoteAddressString(),
peer.getLocalAddressString(),
stage, latestGenerationStamp, minBytesRcvd, maxBytesRcvd,
clientname, srcDataNode, datanode, requestedChecksum,
cachingStrategy, allowLazyPersist, pinning);
...... // 进行写操作
}
在构造BlockReceiver的过程中,会为这个正在写的Block构建对应的ReplicaHandler。一个ReplicaHandler代表了一个正在进行写的一个Replica(ReplicaInPipelineInterface)以及这个Replica在磁盘上的引用信息。因此,需要调用FSDatasetImpl.createTemporary()和FSDatasetImpl.createRbw()来获取。其中具体的区别,这里不进行赘述。这两个方法都需要上FSDatasetImpl的对象锁:
------------------------------------------- BlockReceiver ---------------------------------------
BlockReceiver(final ExtendedBlock block, .......) throws IOException {
try{
.....
if (isDatanode) { //replication or move
replicaHandler = datanode.data.createTemporary(storageType, block);
} else {
switch (stage) {
case PIPELINE_SETUP_CREATE:
replicaHandler = datanode.data.createRbw(storageType, block, allowLazyPersist);
datanode.notifyNamenodeReceivingBlock(
block, replicaHandler.getReplica().getStorageUuid());
break;
FSDatasetImpl.createTemporary()和FSDatasetImpl.createRbw()的代码如下,他们分别是为块的复制(DataNode之间的副本复制或者块的移动)以及写文件的时候的块的写入创建临时文件:
------------------------------------------ FsDatasetImpl -----------------------------------
@Override // 为块的复制或者移动创建临时文件
public ReplicaHandler createTemporary(
StorageType storageType, ExtendedBlock b) throws IOException {
.....
do {
synchronized (this) { // 上FsDatasetImpl对象锁
FsVolumeReference ref =
volumes.getNextVolume(storageType, b.getNumBytes());
FsVolumeImpl v = (FsVolumeImpl) ref.getVolume();
f = v.createTmpFile(b.getBlockPoolId(), b.getLocalBlock());
ReplicaInPipeline newReplicaInfo =
new ReplicaInPipeline(b.getBlockId(), b.getGenerationStamp(), v,
f.getParentFile(), 0);
volumeMap.add(b.getBlockPoolId(), newReplicaInfo);
return new ReplicaHandler(newReplicaInfo, ref);
}
......
@Override // 为块的写入(replica being writing)创建临时文件
public synchronized ReplicaHandler createRbw(
StorageType storageType, ExtendedBlock b, boolean allowLazyPersist)
throws IOException {
ReplicaInfo replicaInfo = volumeMap.get(b.getBlockPoolId(),
b.getBlockId());
// create a new block
FsVolumeReference ref;
ref = volumes.getNextVolume(storageType, b.getNumBytes());
FsVolumeImpl v = (FsVolumeImpl) ref.getVolume();
// create an rbw file to hold block in the designated volume
File f;
f = v.createRbwFile(b.getBlockPoolId(), b.getLocalBlock());
ReplicaBeingWritten newReplicaInfo = new ReplicaBeingWritten(b.getBlockId(),
b.getGenerationStamp(), v, f.getParentFile(), b.getNumBytes());
volumeMap.add(b.getBlockPoolId(), newReplicaInfo);
return new ReplicaHandler(newReplicaInfo, ref);
}
同时,我们看到,在一个Block的写操作结束以后,会调用FSDatasetImpl.finalizeBlock()方法来最终close这个block,这个方法也需要上FSDatasetImpl的对象锁:
@Override // FsDatasetSpi
public void finalizeBlock(ExtendedBlock b, boolean fsyncDir)
throws IOException {
synchronized (this) { // 这里是synchronzied
replicaInfo = getReplicaInfo(b);
finalizedReplicaInfo = finalizeReplica(b.getBlockPoolId(), replicaInfo);// 这个方法也是synchronized
}
}
// 这是一个synchronized方法,加FSDatasetImpl对象锁
private synchronized FinalizedReplica finalizeReplica(String bpid,
ReplicaInfo replicaInfo) throws IOException {
FsVolumeImpl v = (FsVolumeImpl)replicaInfo.getVolume();
File f = replicaInfo.getBlockFile();
File dest = v.addFinalizedBlock(
bpid, replicaInfo, f, replicaInfo.getBytesReserved());
newReplicaInfo = new FinalizedReplica(replicaInfo, v, dest.getParentFile());
volumeMap.add(bpid, newReplicaInfo);
return newReplicaInfo;
}
总之,FSDatasetImpl类是进行DataNode端的块操作的核心类,但是这个类的很多方法都加了很重的FSDatasetImpl对象锁,因此当IBR带来的待处理的Block非常多的时候,其对FSDatasetImpl对象锁的需求就会与正常的写操作对该锁的需求相冲突。
但是总体来讲,DataNode作为一个Worker节点,端FSDatasetImpl对象锁所加锁的操作都是元数据操作(比如提交副本删除删除任务asyncDiskService.deleteAsync()),而不会对一些耗时的文件物理操作(比如物理删除文件,比如写入块数据的整个过程)加锁,因此,相比于NameNode端的全局锁,DataNode端的这个FSDatasetImpl对象锁虽然的确会影响客户端读写,但是往往不是性能下降的关键。
如果不结合Dashboard进行详细的分析,当由于Trash的清空导致客户端写数据的吞吐降低的时候,我们很容易错误地以为是磁盘的高负载导致的。但是我们可以看到,DataNode端的异步删除设计起到了削峰填谷的作用,巨大的删除操作不会在磁盘负载上带来压力,写性能的下降来自于FSDatasetImpl的锁控制。
我们发现到了Hadoop 3,FSDatasetImpl上的锁控制逻辑,主要是将简单通过synchronized方法来加FSDatasetImpl对象锁,替换成AutoCloseableLock,目的是方便进行锁冲突的相关分析,其实并没有针对锁控制逻辑进行优化:
HADOOP-10682. Replace FsDatasetImpl object lock with a separate lock
同时在另一个仍然处于open()状态的PR中,其作者是发现了我们所发现的相同问题并试图进行优化,目前还处在进行中:HDFS-9668
NameNode端的RPC变化分析
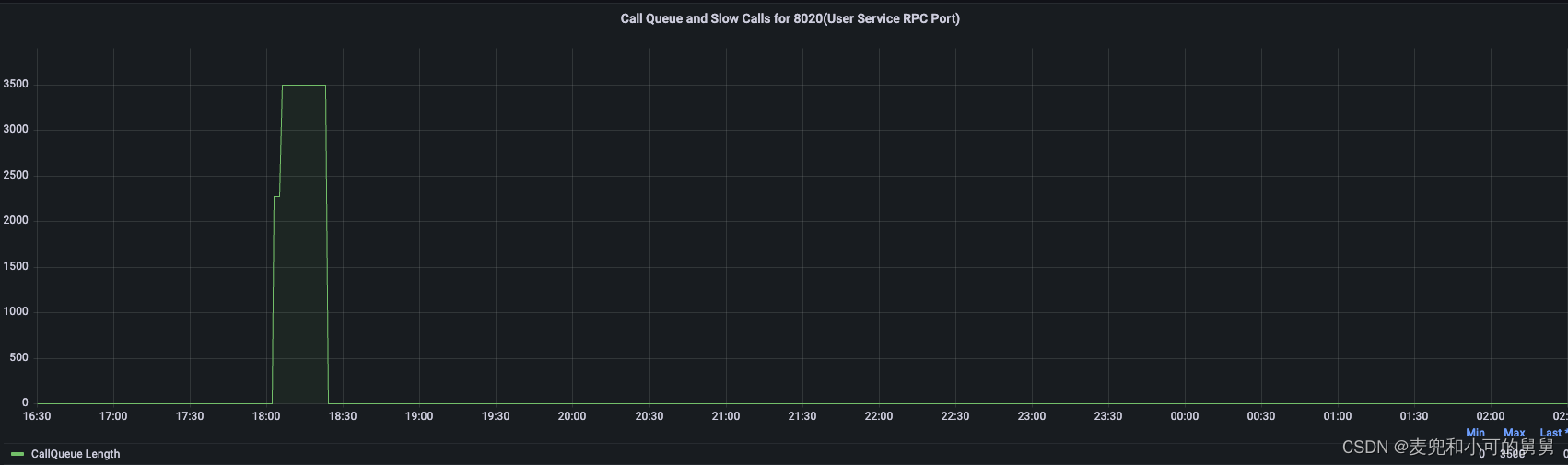
我们看到,NameNode端的CallQueue在事故发生期间是暴增的,如下图所示:
 为了理解暴增的原因,我们必须理解HDFS RPC框架中的CallQueue的含义,它其实是Reactor模型中的概念,在我的另外一篇文章《Hadoop RPC Server 基于Reactor模型和NIO的框架详解》中,已经详细介绍了RPC框架。其中,callQueue就是用来存放封装好的Call对象的队列。
为了理解暴增的原因,我们必须理解HDFS RPC框架中的CallQueue的含义,它其实是Reactor模型中的概念,在我的另外一篇文章《Hadoop RPC Server 基于Reactor模型和NIO的框架详解》中,已经详细介绍了RPC框架。其中,callQueue就是用来存放封装好的Call对象的队列。
NameNode中的Listener线程收到客户端(8020端口)或者DataNode(8022端口)的RPC请求以后,Listener线程池中的线程会将对应的请求组装成Call对象,放入到ipc.Server对象的callQueue中:
------------------------------------ ipc.Server.Connection --------------------------------
private void processRpcRequest(RpcRequestHeaderProto header,
DataInputStream dis) throws WrappedRpcServerException,
InterruptedException {
.......
Call call = new Call(header.getCallId(), header.getRetryCount(),
rpcRequest, this, ProtoUtil.convert(header.getRpcKind()),
header.getClientId().toByteArray(), traceScope);
....
callQueue.put(call); // queue the call; maybe blocked here
Reactor框架中的Handler线程池中任意一个Handler线程会不断从callQueue中取出Call进行处理:
--------------------------------------- Handler -------------------------------------------
@Override
public void run() {
LOG.debug(Thread.currentThread().getName() + ": starting");
SERVER.set(Server.this);
while (running) {
TraceScope traceScope = null;
try {
final Call call = callQueue.take(); // pop the queue; maybe blocked here
.....
value = call(call.rpcKind, call.connection.protocolName, call.rpcRequest,
call.timestamp);
}
}
Handler线程池中的Handler线程是有限的。在ipc.Server启动的时候,会构建Handler线程数组,数组大小通过ipc.server.handler.queue.size进行配置,默认100:
public synchronized void start() {
responder.start();
listener.start();
handlers = new Handler[handlerCount];// 默认构建100个Handler线程
for (int i = 0; i < handlerCount; i++) {
handlers[i] = new Handler(i);
handlers[i].start();
}
}
Call Queue Length所表达的就是callQueue中还没来得及被处理的Call对象:
-------------------------------------------- Server -------------------------------------
public int getCallQueueLen() {
return callQueue.size();
}
Call Queue Length在事故发生期间陡增,说明Handler的处理变慢。怎样衡量Handler的处理能力?下面两个Panel分别显式了8020(面向客户端的RPC端口)和8022(面向DataNode的RPC端口,比如heartbeat或者IBR)在单位时间内处理的请求次数。下面的代码就是基于Protobuf的RPC Engine中,Handler实际调用的方法,可以看到,当用户请求处理完毕以后,会更新对应的Rpc Queue/Processing Metrics:
----------------------------------------- ProtobufRpcEngine ----------------------------------
public Writable call(RPC.Server server, String protocol,
Writable writableRequest, long receiveTime) throws Exception {
....
result = service.callBlockingMethod(methodDescriptor, null, param); // 业务逻辑处理
....
server.rpcMetrics.addRpcQueueTime(qTime); // 更新Rpc Queue Time Metrics
server.rpcMetrics.addRpcProcessingTime(processingTime); // 更新Rpc Processing Time Metrics
server.rpcDetailedMetrics.addProcessingTime(detailedMetricsName,
processingTime);
if (server.isLogSlowRPC()) {
server.logSlowRpcCalls(methodName, processingTime);
}
}
return new RpcResponseWrapper(result);
}
}
下图显示了8020和8022两个端口的Rpc Queue/Processing Time的趋势,可以看到,Handler的处理能力在事故发生期间降低了。很显然,这也是因为客户端的读写请求与我们的删除操作发生了锁争用。
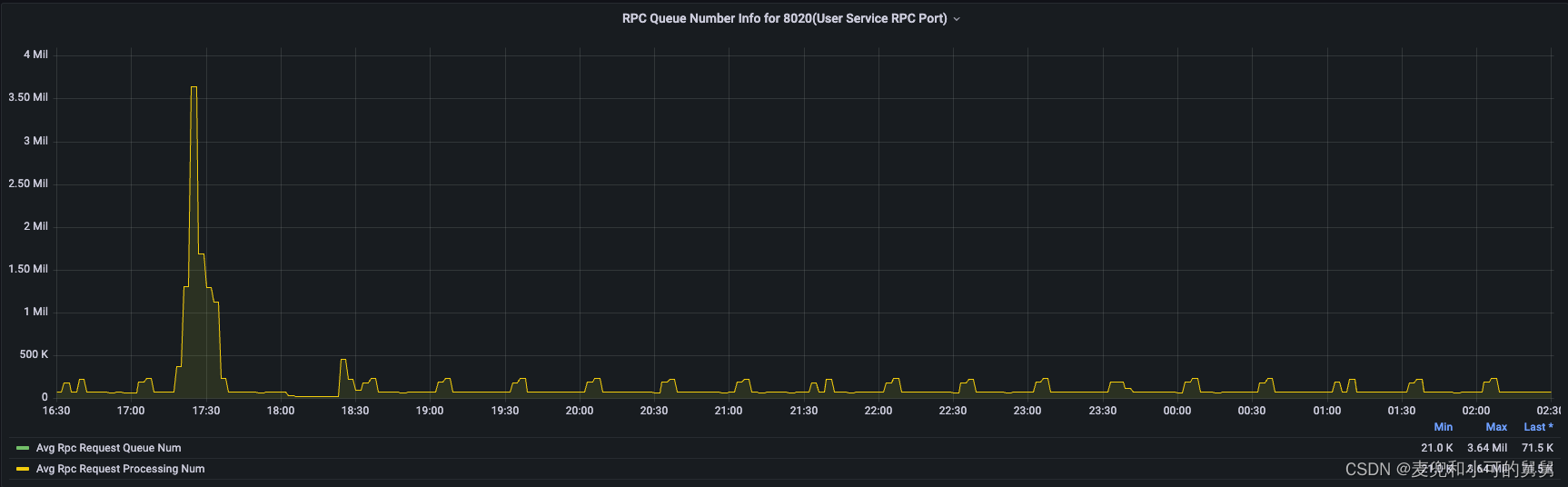
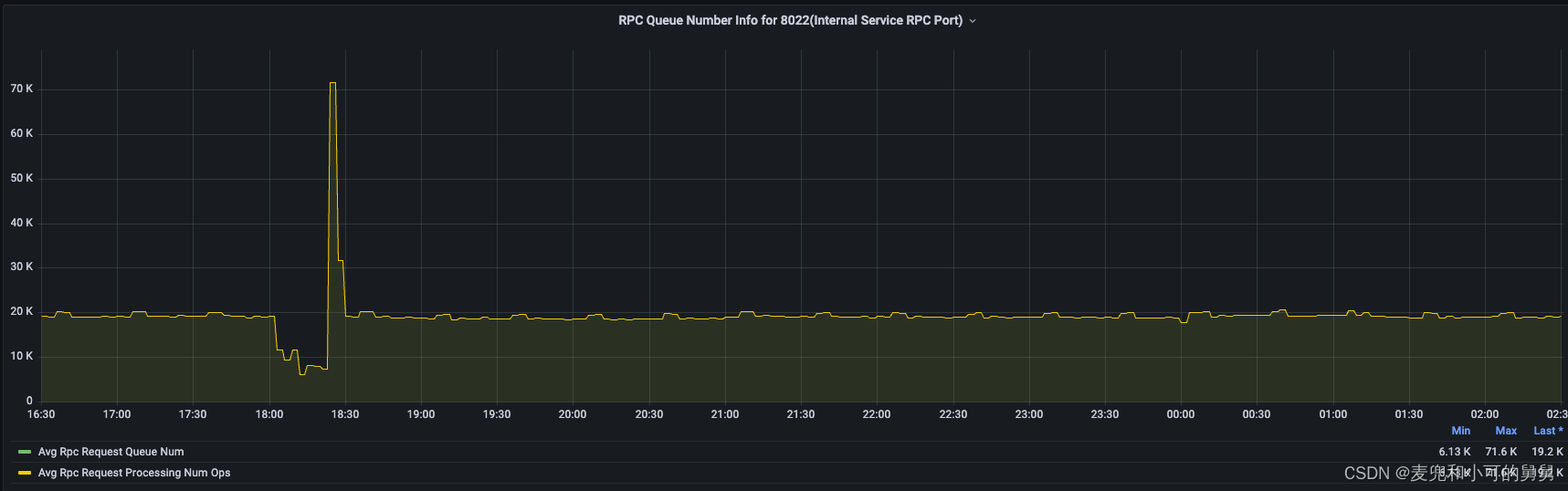
总之,由于锁争用,事故发生期间Handler的处理能力降低,即RPC请求的处理时间会边长,因此Call Queue中会积累越来越多无法处理的Call请求。

















 1479
1479

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









