








本文的Presto源码解析基于Facebook Presto 0.212
Posted in CSDN
Split加载
作为一种MPP处理引擎, Presto的splits加载和调度是并行进行的,也就是说,Coordinator一边加载Splits, 然后一边对已经加载的Splits进行调度。也就是说,Splits的加载和调度处于不同的线程中。
在用户提交了query,生成了query plan并且开始执行的时候,通过访问者模式来处理生成的执行计划树。如果是Scan Node,就根据这个Scan Node的信息,进行元数据读取操作和调度操作,我们可以看DistributedExecutionPlanner可以看到:
@Override
public Map<PlanNodeId, SplitSource> visitTableScan(TableScanNode node, Void context)
{
// get dataSource for table
SplitSource splitSource = splitManager.getSplits(
session,
node.getLayout().get(),
stageExecutionStrategy.isGroupedExecution(node.getId()) ? GROUPED_SCHEDULING : UNGROUPED_SCHEDULING);
splitSources.add(splitSource);
return ImmutableMap.of(node.getId(), splitSource);
}
具体的调用堆栈如截图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lrMOpQyo-1603330096818)(https://raw.githubusercontent.com/VicoWu/leetcode/master/src/main/resources/images/presto/SplitLoaderCallStack.png)]
对于一个分区表,加载它的Splits的第一步,就是获取这张表的partition信息,有了partition信息,就可以逐个读取partiton目录从而获取这个partiton的splits信息。在 Presto中,获取这张表的partiton信息,是在上面堆栈截图的HiveSplitManager.getSplits()中进行的.
TableScanNode中获取TableLayout
在Presto中,把一张表的基本数据信息叫做TableLayout。所有的Connector都必须实现ConnectorTableLayoutHandle接口来定义自己的TableLayout. 这个接口没有任何方法和变量,因此是一个可以按照需要任意定义的接口
package com.facebook.presto.spi;
public interface ConnectorTableLayoutHandle
{
}
对于Hive, 这个接口的实现类是HiveTableLayoutHandle。它定了并且使用了包括但是不仅仅包括以下信息。
private final SchemaTableName schemaTableName;
private final List<ColumnHandle> partitionColumns;
private final List<HivePartition> partitions;
private final TupleDomain<? extends ColumnHandle> compactEffectivePredicate;
private final TupleDomain<ColumnHandle> promisedPredicate;
private final Optional<HiveBucketHandle> bucketHandle;
private final Optional<HiveBucketFilter> bucketFilter;
可以看到,这些变量都是这张表的一些基本信息。那么,一张表的TableLayout是在什么时候获取的呢?它是在对用户的 query生成了执行计划树以后生成的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yHJOLQOW-1603330096822)(https://raw.githubusercontent.com/VicoWu/leetcode/master/src/main/resources/images/presto/Presto-Table-Layout-Call-Stack.png)]
这里的bucketHandle和bucketFilter会用于在后面讲到的splits生成。
ConnectorSplitManager通用接口
ConnectorSplitManager是Presto SPI中的一个接口,它提供了一个接口方法getSplits(),用来给具体的Connector来实现接口:
public interface ConnectorSplitManager
{
ConnectorSplitSource getSplits(
ConnectorTransactionHandle transactionHandle,
ConnectorSession session,
ConnectorTableLayoutHandle layout,
SplitSchedulingStrategy splitSchedulingStrategy);
enum SplitSchedulingStrategy
{
UNGROUPED_SCHEDULING,
GROUPED_SCHEDULING,
}
}
对于Hive Connector,这个接口的实现类是HiveSplitManager. HiveSplitManager.getSplits()方法的主要功能是:
- 与HMS通信,先获取表的全部partition元数据,是一次性完成的 ;
- 对于每一个partition,读取partiton的splits信息,由于splits涉及到具体的HDFS文件,因此需要与HDFS通信,是通过多线程逐步完成,即边读取splits边进行splits的调度。这一步就是委托HiveSplitLoader进行的,是异步的。
我们来研究HiveSplitLoader的实现。
Iterable<HivePartitionMetadata> hivePartitions = getPartitionMetadata(metastore, table, tableName, partitions, bucketHandle.map(HiveBucketHandle::toBucketProperty));
HiveSplitLoader hiveSplitLoader = new BackgroundHiveSplitLoader(
table,
hivePartitions,
layout.getCompactEffectivePredicate(),
createBucketSplitInfo(bucketHandle, bucketFilter),
session,
hdfsEnvironment,
namenodeStats,
directoryLister,
executor,
splitLoaderConcurrency,
recursiveDfsWalkerEnabled);
从上图代码中可以看到,getPartitionMetadata()获取这张表的所有的partiton信息,其实是一个迭代器Iterable<HivePartitionMetadata>,有了这个partitions的迭代器,就可以交给BackgroundHiveSplitLoader来遍历所有的partiton,然后逐个partition加载所有的splits了。
所以,先忽略具体实现,Coordinator获取partition的步骤是:
使用BackgroundHiveSplitLoader加载Splits
@Override
public void start(HiveSplitSource splitSource)
{
this.hiveSplitSource = splitSource;
for (int i = 0; i < loaderConcurrency; i++) {
ResumableTasks.submit(executor, new HiveSplitLoaderTask());
}
}
可以看到,通过loaderConcurrency来确定并发逻辑,多个线程并发获取各个partition的具体splits信息。通过BackgroundHiveSplitLoader可以看到,通过配置hive.split-loader-concurrency 来配置并发度,默认是4, 意味着,默认情况下,对于每一个query,Coordinator会有4个线程负责不断获取这个Query里面所有的splits。每一个split loader 的线程叫做HiveSplitLoaderTask
private class HiveSplitLoaderTask
implements ResumableTask
{
@Override
public TaskStatus process()
{
while (true) {
if (stopped) {
return TaskStatus.finished();
}
ListenableFuture<?> future;
taskExecutionLock.readLock().lock();
try {
future = loadSplits();
}
catch (Exception e) {
//略
}
finally {
taskExecutionLock.readLock().unlock();
}
invokeNoMoreSplitsIfNecessary();
if (!future.isDone()) {
return TaskStatus.continueOn(future);
}
}
}
}
可以看到,HiveSplitLoaderTask 通过反复调用loadSplits()方法来不断加载splits。
loadSplits()加载splits
private ListenableFuture<?> loadSplits()
throws IOException
{
//获取等待处理的split信息
Iterator<InternalHiveSplit> splits = fileIterators.poll();
if (splits == null) { //如果当前没有需要处理的splits
//尝试获取一个新的partiton进行处理
HivePartitionMetadata partition = partitions.poll();
if (partition == null) {
return COMPLETED_FUTURE;
}
//加载这个partition,即读取HDFS,将这个partition的文件转化成一个一个的split
return loadPartition(partition);
}
//开始遍历每一个splits
while (splits.hasNext() && !stopped) {
ListenableFuture<?> future = hiveSplitSource.addToQueue(splits.next());
// 如果我们发现future 不是done的状态,证明hiveSplitSource出现了队列满等可能的异常,因此需要把这个splits重新放回fileIterators中
//然后直接返回
if (!future.isDone()) {
fileIterators.addFirst(splits);
return future;
}
}
// No need to put the iterator back, since it's either empty or we've stopped
return COMPLETED_FUTURE;
}
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9DbwYtho-1603330096824)(https://raw.githubusercontent.com/VicoWu/leetcode/master/src/main/resources/images/presto/Presto Split Loader Diagram.jpeg)]
fileIterators是一个dequeue,这个dequeue里面的每一个元素是一个迭代器,从后面的代码可以看到,这个迭代器代表了一个partiton,通过遍历这个迭代器,就可以逐步获取这个partition里面的所有文件。也就是说,fileInterators是目前所有的partition的splits
loadSplits()方法的管理逻辑是:
尝试从fileIterators迭代器中获取一个splits迭代器,这个迭代器肯定是某个partiton对应的所有splits,即这个partiton后面的所有文件
- 如果发现
fileIterators是空的,那么说明当前所有的spilits已经被处理完毕,所以,需要检查是不是有新的partiton需要处理,因此,通过方法partitions.poll();从partiton迭代器中尝试获取一个partiton- 如果
partitions是空的,那么直接返回 - 如果partition不为空,那么就可以通过
loadPartition()来处理这个partition了,这里的处理,就是通过与HDFS通信,获取这个partiton对应的所有的splits,组成一个迭代器,存放到fileIterators中。
- 如果
- 如果
fileIterators不是空的,那么就取出其中的一个迭代器Iterator<InternalHiveSplit>,然后,遍历这个迭代器中的每个元素- 把这个Split加入到hiveSplitSource中
hiveSplitSource.addToQueue(splits.next());返回的Future不是done的状态,那么说明hiveSplitSource里面的队列可能出现了队列满的状态,因此此时立刻停止,然后再把这个迭代器放回到fileIterators中,这样,过一段时间,这个迭代器又会被其它的BackgroundHiveSplitLoader访问到(当然,也有可能还是自己访问到)
loadPartition()加载partition
通过上面讲解loadSplit()方法,Coordinator是先尝试加载splits, 当发现没有splits的时候,会尝试去获取一个新的partiton来加载这个partition的splist,当发现也没有新的partition的时候,说明任务已经全部结束了,当发现了新的partition,就会通过loadPartition()去加载新的partition,即,partition的加载时动态按需调用的,而不是预先就开始调用。
private ListenableFuture<?> loadPartition(HivePartitionMetadata partition)
throws IOException
{
String partitionName = partition.getHivePartition().getPartitionId();
Properties schema = getPartitionSchema(table, partition.getPartition());
List<HivePartitionKey> partitionKeys = getPartitionKeys(table, partition.getPartition());
TupleDomain<HiveColumnHandle> effectivePredicate = (TupleDomain<HiveColumnHandle>) compactEffectivePredicate;
Path path = new Path(getPartitionLocation(table, partition.getPartition()));
Configuration configuration = hdfsEnvironment.getConfiguration(hdfsContext, path);
InputFormat<?, ?> inputFormat = getInputFormat(configuration, schema, false);
FileSystem fs = hdfsEnvironment.getFileSystem(hdfsContext, path);
Optional<BucketConversion> bucketConversion = Optional.empty();
boolean bucketConversionRequiresWorkerParticipation = false;
if (partition.getPartition().isPresent()) {
Optional<HiveBucketProperty> partitionBucketProperty = partition.getPartition().get().getStorage().getBucketProperty();
if (tableBucketInfo.isPresent() && partitionBucketProperty.isPresent()) {
int tableBucketCount = tableBucketInfo.get().getBucketCount();
int partitionBucketCount = partitionBucketProperty.get().getBucketCount();
// Validation was done in HiveSplitManager#getPartitionMetadata.
// Here, it's just trying to see if its needs the BucketConversion.
if (tableBucketCount != partitionBucketCount) {
bucketConversion = Optional.of(new BucketConversion(tableBucketCount, partitionBucketCount, tableBucketInfo.get().getBucketColumns()));
if (tableBucketCount > partitionBucketCount) {
bucketConversionRequiresWorkerParticipation = true;
}
}
}
}
InternalHiveSplitFactory splitFactory = new InternalHiveSplitFactory(
fs,
partitionName,
inputFormat,
schema,
partitionKeys,
effectivePredicate,
partition.getColumnCoercions(),
bucketConversionRequiresWorkerParticipation ? bucketConversion : Optional.empty(),
isForceLocalScheduling(session));
// To support custom input formats, we want to call getSplits()
// on the input format to obtain file splits.
if (shouldUseFileSplitsFromInputFormat(inputFormat)) {
if (tableBucketInfo.isPresent()) {
throw new PrestoException(NOT_SUPPORTED, "Presto cannot read bucketed partition in an input format with UseFileSplitsFromInputFormat annotation: " + inputFormat.getClass().getSimpleName());
}
JobConf jobConf = toJobConf(configuration);
FileInputFormat.setInputPaths(jobConf, path);
InputSplit[] splits = inputFormat.getSplits(jobConf, 0);
return addSplitsToSource(splits, splitFactory);
}
// Bucketed partitions are fully loaded immediately since all files must be loaded to determine the file to bucket mapping
if (tableBucketInfo.isPresent()) {
return hiveSplitSource.addToQueue(getBucketedSplits(path, fs, splitFactory, tableBucketInfo.get(), bucketConversion));
}
boolean splittable = getHeaderCount(schema) == 0 && getFooterCount(schema) == 0;
fileIterators.addLast(createInternalHiveSplitIterator(path, fs, splitFactory, splittable));
return COMPLETED_FUTURE;
}
从上述代码可以看到,loadPartition()对于bucketed table进行了一些额外的处理。
对于bucket table的处理逻辑
对于hive bucket,可以参考以下文档:Wiki: Hive Bucketed Tables
从上述代码可以看到,如果是bucket表,那么就会调用getBucketedSplits()方法来生成对应的splits,如果不是bucket表,就调用createInternalHiveSplitIterator()来生成splits的迭代器。从代码
// Bucketed partitions are fully loaded immediately since all files must be loaded to determine the file to bucket mapping
if (tableBucketInfo.isPresent()) {
return hiveSplitSource.addToQueue(getBucketedSplits(path, fs, splitFactory, tableBucketInfo.get(), bucketConversion));
}
可以看出,对于bucket table,所有的splits是一次性全部加到hiveSplitSource中, 而如果不是bucket 表,那么其实生成的是一个迭代器,可以逐步迭代。
我们来看getBucketedSplits()方法的具体实现:
private List<InternalHiveSplit> getBucketedSplits(Path path, FileSystem fileSystem, InternalHiveSplitFactory splitFactory, BucketSplitInfo bucketSplitInfo, Optional<BucketConversion> bucketConversion)
{
int tableBucketCount = bucketSplitInfo.getBucketCount();
int partitionBucketCount = bucketConversion.isPresent() ? bucketConversion.get().getPartitionBucketCount() : tableBucketCount;
// list all files in the partition
ArrayList<LocatedFileStatus> files = new ArrayList<>(partitionBucketCount);
try {
Iterators.addAll(files, new HiveFileIterator(path, fileSystem, directoryLister, namenodeStats, FAIL));
}
catch (NestedDirectoryNotAllowedException e) {
// Fail here to be on the safe side. This seems to be the same as what Hive does
throw new PrestoException(
HIVE_INVALID_BUCKET_FILES,
format("Hive table '%s' is corrupt. Found sub-directory in bucket directory for partition: %s",
new SchemaTableName(table.getDatabaseName(), table.getTableName()),
splitFactory.getPartitionName()));
}
// verify we found one file per bucket
if (files.size() != partitionBucketCount) {
throw new PrestoException(
HIVE_INVALID_BUCKET_FILES,
format("Hive table '%s' is corrupt. The number of files in the directory (%s) does not match the declared bucket count (%s) for partition: %s",
new SchemaTableName(table.getDatabaseName(), table.getTableName()),
files.size(),
partitionBucketCount,
splitFactory.getPartitionName()));
}
// Sort FileStatus objects (instead of, e.g., fileStatus.getPath().toString). This matches org.apache.hadoop.hive.ql.metadata.Table.getSortedPaths
files.sort(null);
// convert files internal splits
List<InternalHiveSplit> splitList = new ArrayList<>();
for (int bucketNumber = 0; bucketNumber < Math.max(tableBucketCount, partitionBucketCount); bucketNumber++) {
int partitionBucketNumber = bucketNumber % partitionBucketCount; // physical
int tableBucketNumber = bucketNumber % tableBucketCount; // logical
if (bucketSplitInfo.isBucketEnabled(tableBucketNumber)) {
LocatedFileStatus file = files.get(partitionBucketNumber);
splitFactory.createInternalHiveSplit(file, tableBucketNumber)
.ifPresent(splitList::add);
}
}
return splitList;
}
对于非bucket table的处理逻辑
private Iterator<InternalHiveSplit> createInternalHiveSplitIterator(Path path, FileSystem fileSystem, InternalHiveSplitFactory splitFactory, boolean splittable)
{
return Streams.stream(new HiveFileIterator(path, fileSystem, directoryLister, namenodeStats, recursiveDirWalkerEnabled ? RECURSE : IGNORED))
.map(status -> splitFactory.createInternalHiveSplit(status, splittable))
.filter(Optional::isPresent)
.map(Optional::get)
.iterator();
}
HiveSplitSource 通用接口向Coordinator交付Split
ConnectorSplitSource通用接口
当Presto通过SplitLoader加载了所有的split,就将这些splits交付给对应的ConnectorSplitSource的具体实现了。所有的Presto Connector都需要实现ConnectorSplitSource接口,通过接口的方式,Presto的核心代码不需要关心ConnectorSplitSources的具体实现是什么, 只需要根据接口提供的方法来获取对应的splits然后对splits进行调度就行了。这就是为什么Presto可以支持那么多的connector,因为它设计了一套通用的SPI,各个Connector只需要实现这套SPI就可以了。
public interface ConnectorSplitSource
extends Closeable
{
CompletableFuture<ConnectorSplitBatch> getNextBatch(ConnectorPartitionHandle partitionHandle, int maxSize);
@Override
void close();
/**
* Returns whether any more {@link ConnectorSplit} may be produced.
*
* This method should only be called when there has been no invocation of getNextBatch,
* or result Future of previous getNextBatch is done.
* Calling this method at other time is not useful because the contract of such an invocation
* will be inherently racy.
*/
boolean isFinished();
}
从上面的代码可以看到, ConnectorSplitSource提供了三个接口,即
-
获取下一个batch的splits 方法getNextBatch()
-
关闭这个source的方法close()
-
判断splits是否已经全部获取完毕的isFinished()方法
这三个接口非常直观,就是Presto用来从底层的具体实现来获取数据,并且,通过
getNextBatch()方法可以看到,是一次获取一批数据,而非逐条获取数据。
对于Hive Connection,ConnectorSplitSources对实现类是HiveSplitSource。
我们可以参考presto的官方文档获取关于Presto Connector的一些基本实现。
HiveSplitSource的具体实现
TaskExecutor
TaskExecutor的启动和主要参数
TaskExecutor在每一个Presto的worker node 启动的时候被构造,用来管理这个worker node上的所有的task的执行:
所有的worker节点的入口是ServerMainModule, 所有的Presto的workernode的main函数入口是CoordinatorMain, 通过注入的方式,每一个ServerMainModule启动的时候会启动一个单例的TaskExecutor:
binder.bind(TaskExecutor.class).in(Scopes.SINGLETON);
然后我们来看TaskExecutor的构造方法:
@Inject
public TaskExecutor(TaskManagerConfig config, MultilevelSplitQueue splitQueue)
{
this(requireNonNull(config, "config is null").getMaxWorkerThreads(),
config.getMinDrivers(),
config.getMinDriversPerTask(),
config.getMaxDriversPerTask(),
splitQueue,
Ticker.systemTicker());
}
@VisibleForTesting
public TaskExecutor(int runnerThreads, int minDrivers, int minimumNumberOfDriversPerTask, int maximumNumberOfDriversPerTask, Ticker ticker)
{
this(runnerThreads, minDrivers, minimumNumberOfDriversPerTask, maximumNumberOfDriversPerTask, new MultilevelSplitQueue(2), ticker);
}
@VisibleForTesting
public TaskExecutor(int runnerThreads, int minDrivers, int minimumNumberOfDriversPerTask, int maximumNumberOfDriversPerTask, MultilevelSplitQueue splitQueue, Ticker ticker)
{
checkArgument(runnerThreads > 0, "runnerThreads must be at least 1");
checkArgument(minimumNumberOfDriversPerTask > 0, "minimumNumberOfDriversPerTask must be at least 1");
checkArgument(maximumNumberOfDriversPerTask > 0, "maximumNumberOfDriversPerTask must be at least 1");
checkArgument(minimumNumberOfDriversPerTask <= maximumNumberOfDriversPerTask, "minimumNumberOfDriversPerTask cannot be greater than maximumNumberOfDriversPerTask");
// we manage thread pool size directly, so create an unlimited pool
this.executor = newCachedThreadPool(threadsNamed("task-processor-%s"));
this.executorMBean = new ThreadPoolExecutorMBean((ThreadPoolExecutor) executor);
this.runnerThreads = runnerThreads;
this.ticker = requireNonNull(ticker, "ticker is null");
this.minimumNumberOfDrivers = minDrivers;
this.minimumNumberOfDriversPerTask = minimumNumberOfDriversPerTask;
this.maximumNumberOfDriversPerTask = maximumNumberOfDriversPerTask;
this.waitingSplits = requireNonNull(splitQueue, "splitQueue is null");
this.tasks = new LinkedList<>();
}
可以看到,这个TaskExecutor会创建一个cached thread pool,一个线程池来管理这个worker上的所有的执行线程,然后逐个启动线程:
@PostConstruct
public synchronized void start()
{
checkState(!closed, "TaskExecutor is closed");
for (int i = 0; i < runnerThreads; i++) {
addRunnerThread();
}
}
private synchronized void addRunnerThread()
{
try {
executor.execute(new TaskRunner());
}
catch (RejectedExecutionException ignored) {
}
}
TaskExecutor的分时间片调度逻辑
public ListenableFuture<?> processFor(Duration duration)
{
checkLockNotHeld("Cannot process for a duration while holding the driver lock");
requireNonNull(duration, "duration is null");
// if the driver is blocked we don't need to continue
SettableFuture<?> blockedFuture = driverBlockedFuture.get();
if (!blockedFuture.isDone()) {
return blockedFuture;
}
long maxRuntime = duration.roundTo(TimeUnit.NANOSECONDS);
Optional<ListenableFuture<?>> result = tryWithLock(100, TimeUnit.MILLISECONDS, () -> {
OperationTimer operationTimer = createTimer();
driverContext.startProcessTimer();
driverContext.getYieldSignal().setWithDelay(maxRuntime, driverContext.getYieldExecutor());
try {
long start = System.nanoTime();
do {
ListenableFuture<?> future = processInternal(operationTimer);
// if future is not done, we will return directly, otherwise, we will loop until block the loop
if (!future.isDone()) {
return updateDriverBlockedFuture(future);
}
}
while (System.nanoTime() - start < maxRuntime && !isFinishedInternal());
}
finally {
driverContext.getYieldSignal().reset();
driverContext.recordProcessed(operationTimer);
}
return NOT_BLOCKED;
});
return result.orElse(NOT_BLOCKED);
}
What does method updateDriverBlockedFuture() do?
private ListenableFuture<?> updateDriverBlockedFuture(ListenableFuture<?> sourceBlockedFuture)
{
// driverBlockedFuture will be completed as soon as the sourceBlockedFuture is completed
// or any of the operators gets a memory revocation request
SettableFuture<?> newDriverBlockedFuture = SettableFuture.create();
driverBlockedFuture.set(newDriverBlockedFuture);
sourceBlockedFuture.addListener(() -> newDriverBlockedFuture.set(null), directExecutor());
// it's possible that memory revoking is requested for some operator
// before we update driverBlockedFuture above and we don't want to miss that
// notification, so we check to see whether that's the case before returning.
boolean memoryRevokingRequested = activeOperators.stream()
.filter(operator -> !revokingOperators.containsKey(operator)) //remove the revoking operators
.map(Operator::getOperatorContext)
.anyMatch(OperatorContext::isMemoryRevokingRequested); // the memory revoking is requested
if (memoryRevokingRequested) {
newDriverBlockedFuture.set(null); //un block the future
}
return newDriverBlockedFuture;
}
Let’s check the code of DriverYieldSignal:
public synchronized void setWithDelay(long maxRunNanos, ScheduledExecutorService executor)
{
checkState(yieldFuture == null, "there is an ongoing yield");
checkState(!isSet(), "yield while driver was not running");
this.runningSequence++;
long expectedRunningSequence = this.runningSequence;
yieldFuture = executor.schedule(() -> {
synchronized (this) {
if (expectedRunningSequence == runningSequence && yieldFuture != null) {
yield.set(true);
}
}
}, maxRunNanos, NANOSECONDS);
}
public synchronized void reset()
{
checkState(yieldFuture != null, "there is no ongoing yield");
yield.set(false);
yieldFuture.cancel(true);
yieldFuture = null;
}
Split的处理逻辑和三种状态
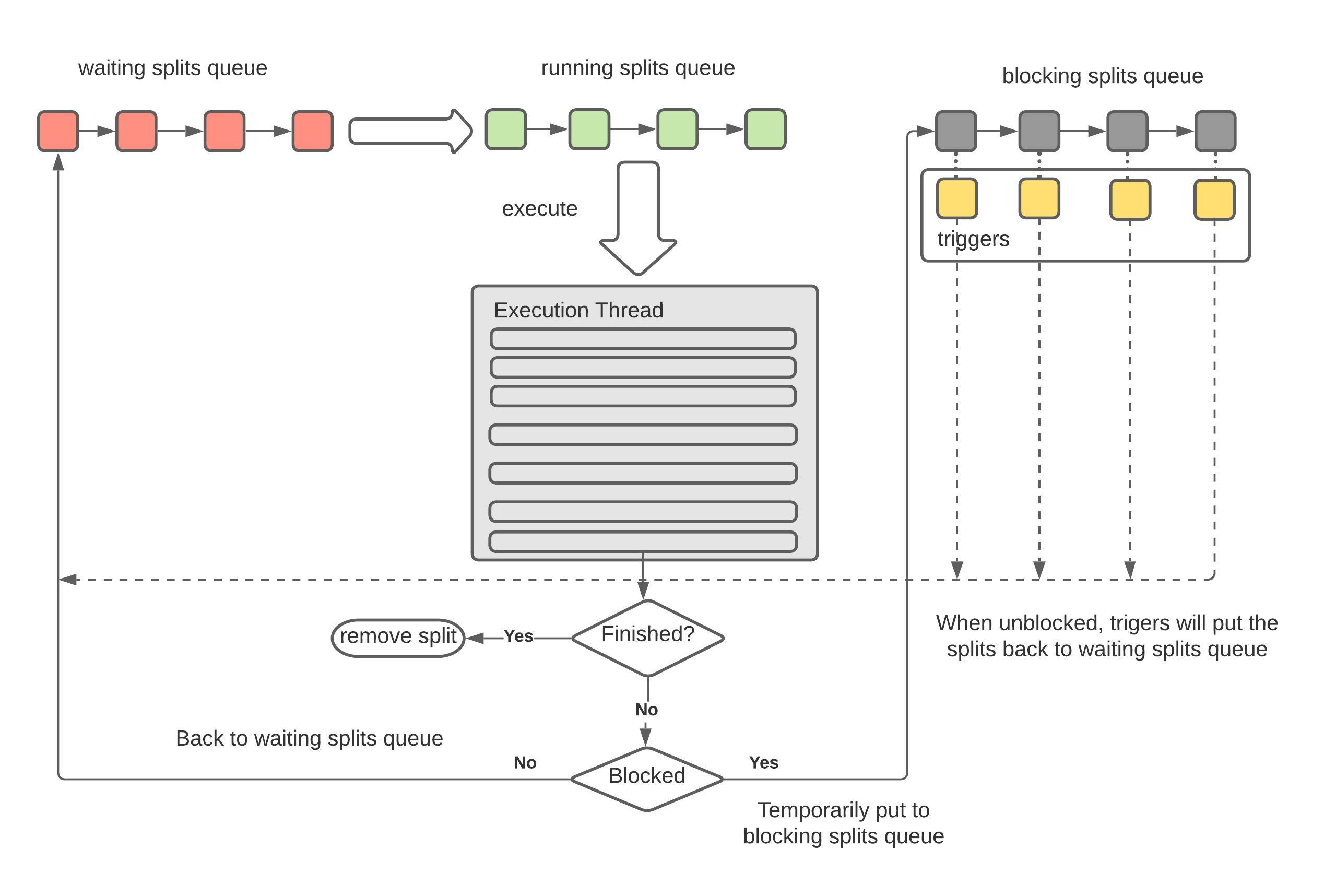
在TaskExecutor勒中,定义了三种不同状态的split的集合:
/**
* Splits waiting for a runner thread.
*/
private final MultilevelSplitQueue waitingSplits;
/**
* Splits running on a thread.
*/
private final Set<PrioritizedSplitRunner> runningSplits = newConcurrentHashSet();
/**
* Splits blocked by the driver.
*/
private final Map<PrioritizedSplitRunner, Future<?>> blockedSplits = new ConcurrentHashMap<>();
从名字可以看到, TaskExecutor负责Split的轮流执行,由于Split的数量不可预知且大部分情况下都非常大,因此我们不可能为每一个Split启动对应的线程,唯一的方法就是采用操作系统的设计,创建有限的固定数量的线程,然后不同的SplitRunner按照时间片使用这些线程;
TaskHandle负责管理这个worker上所有的SplitRunner的生命周期,我们可以简单理解为,TaskHandle负责将需要执行的SplitRunner提交给TaskExecutor,TaskExecutor使用时间片共享的方式来执行这些SplitRunner直到结束:
下图是TaskHandle将Split交付给TaskExecutor的整个状态转换过程:
[TODO]https://www.lucidchart.com/documents/edit/ac59e316-4360-488f-ae3d-5eb709616dd9/0_0
private class TaskRunner
implements Runnable
{
private final long runnerId = NEXT_RUNNER_ID.getAndIncrement();
@Override
public void run()
{
try (SetThreadName runnerName = new SetThreadName("SplitRunner-%s", runnerId)) {
while (!closed && !Thread.currentThread().isInterrupted()) {
// select next worker
final PrioritizedSplitRunner split;
split = waitingSplits.take();
String threadId = split.getTaskHandle().getTaskId() + "-" + split.getSplitId();
try (SetThreadName splitName = new SetThreadName(threadId)) {
RunningSplitInfo splitInfo = new RunningSplitInfo(ticker.read(), threadId, Thread.currentThread());
runningSplitInfos.add(splitInfo);
runningSplits.add(split);
ListenableFuture<?> blocked;
try {
//process()方法并不是真正开始执行split,而是返回一个future,即异步执行的一个句柄
blocked = split.process();
}
finally {
runningSplitInfos.remove(splitInfo);
runningSplits.remove(split);
}
if (split.isFinished()) {
log.debug("%s is finished", split.getInfo());
splitFinished(split);
}
else {
if (blocked.isDone()) {
waitingSplits.offer(split);
}
else {
blockedSplits.put(split, blocked);
blocked.addListener(() -> {
blockedSplits.remove(split);
// reset the level priority to prevent previously-blocked splits from starving existing splits
split.resetLevelPriority();
waitingSplits.offer(split);
}, executor);
}
}
}
catch (Throwable t) {
...
splitFinished(split);
}
}
}
...
}
}
我们从这段代码里面可以清晰看到split的不同状态的转换关系:
- finished splits: 意思是已经完全执行完毕的splits,即这个split对应的driver的状态已经是finished的
- waiting splits: 等待分配时间片的split
- blocked splist: splits没有执行完,但是时间片已经到了
所以,从以上代码可以看出:
- 如果
split.isFinished() == true,那就进行split的结束清理逻辑; - 否则,就有两种选择:
- 如果
blocked.isDone(),就是说这个时间片对应的future已经done(但是split并不一定处理完),那么这个split就放入到waitingSplits中等待下一个时间片到达然后继续执行 - 否则,说明future还没有结束(比如,这个future里面有一些operator正在做长时间的spilling 或者 unspilling 操作),这时候什么也做不了,因为我们不可能强行中断某些operator的执行,只能添加一个future,在它执行结束以后放到waitingSplits中;
- 如果
Split调度的优先级:
我们先来看优先级的定义,即明白优先级有哪些衡量指标,然后我们再探讨每一个SplitRunner的优先级是怎么计算得到的、是根据什么策略去更新以及更新以后怎么根据优先级来确定SplitRunner的调度顺序的。
优先级的定义
@Immutable
public final class Priority
{
private final int level;
private final long levelPriority;
....
}
可以看到,优先级是由1. level 2. level内部的优先级来决定的。level决定了这个split被放到哪个queue里面执行,而levelPriority则是在相同的level里面,这些split的执行顺序。所以,这种优先级其实是两层优先级的策略。
优先级的计算
整个优先级的更新是在方法updatePriority()中进行
public Priority updatePriority(Priority oldPriority, long quantaNanos, long scheduledNanos)
{
int oldLevel = oldPriority.getLevel();
int newLevel = computeLevel(scheduledNanos);
long levelContribution = Math.min(quantaNanos, LEVEL_CONTRIBUTION_CAP);
if (oldLevel == newLevel) {
addLevelTime(oldLevel, levelContribution);
return new Priority(oldLevel, oldPriority.getLevelPriority() + quantaNanos);
}
long remainingLevelContribution = levelContribution;
long remainingTaskTime = quantaNanos;
// a task normally slowly accrues scheduled time in a level and then moves to the next, but
// if the split had a particularly long quanta, accrue time to each level as if it had run
// in that level up to the level limit.
for (int currentLevel = oldLevel; currentLevel < newLevel; currentLevel++) {
long timeAccruedToLevel = Math.min(SECONDS.toNanos(LEVEL_THRESHOLD_SECONDS[currentLevel + 1] - LEVEL_THRESHOLD_SECONDS[currentLevel]), remainingLevelContribution);
addLevelTime(currentLevel, timeAccruedToLevel);
remainingLevelContribution -= timeAccruedToLevel;
remainingTaskTime -= timeAccruedToLevel;
}
addLevelTime(newLevel, remainingLevelContribution);
long newLevelMinPriority = getLevelMinPriority(newLevel, scheduledNanos);
return new Priority(newLevel, newLevelMinPriority + remainingTaskTime);
}
对SplitRunner的优先级的管理,是在MultilevelSplitQueue中:
@ThreadSafe
public class MultilevelSplitQueue
{
static final int[] LEVEL_THRESHOLD_SECONDS = {0, 1, 10, 60, 300};
static final long LEVEL_CONTRIBUTION_CAP = SECONDS.toNanos(30);
@GuardedBy("lock")
private final List<PriorityQueue<PrioritizedSplitRunner>> levelWaitingSplits;
private final AtomicLong[] levelScheduledTime = new AtomicLong[LEVEL_THRESHOLD_SECONDS.length];
levelWaitingSplits 用来存放不同的level的PrioritizedSplitRunner, 而levelScheduledTime存放了不同level的所有SplitRunner的调度时间;
level的计算:
level的衡量标准是这个SplitRunner的运行已经消耗掉这个Task的时间积累量,我们看computeLevel()方法:
static final int[] LEVEL_THRESHOLD_SECONDS = {0, 1, 10, 60, 300};
public static int computeLevel(long threadUsageNanos)
{
long seconds = NANOSECONDS.toSeconds(threadUsageNanos);
for (int i = 0; i < (LEVEL_THRESHOLD_SECONDS.length - 1); i++) {
if (seconds < LEVEL_THRESHOLD_SECONDS[i + 1]) {
return i;
}
}
return LEVEL_THRESHOLD_SECONDS.length - 1;
}
可以看到,按照执行时间,分成了5个档次,0s-1s, 1s-10s, 10s-60s, 60s - 300s, 随着执行时间增加,通过已经消耗掉执行时间来获取level的数值,从0 到 4 一共五个level
levelPriority的计算:
根据优先级取出SplitRunner执行
由于在TaskRunner()中调用MultilevelSplitQueue.take()方法取出PrioritiesSplitRunner()执行,因此,这个take()方法就是根据Priority来决定SplitRunner的取出顺序,我们来看take()方法:
public PrioritizedSplitRunner take()
throws InterruptedException
{
while (true) {
lock.lockInterruptibly();
try {
PrioritizedSplitRunner result;
while ((result = pollSplit()) == null) {
notEmpty.await();
}
...
}
finally {
lock.unlock();
}
}
}
因此关键方法是pollSplit():
/**
* Presto attempts to give each level a target amount of scheduled time, which is configurable
* using levelTimeMultiplier.
* <p>
* This function selects the level that has the the lowest ratio of actual to the target time
* with the objective of minimizing deviation from the target scheduled time. From this level,
* we pick the split with the lowest priority.
*/
@GuardedBy("lock")
private PrioritizedSplitRunner pollSplit()
{
long targetScheduledTime = getLevel0TargetTime();
double worstRatio = 1;
int selectedLevel = -1;
for (int level = 0; level < LEVEL_THRESHOLD_SECONDS.length; level++) {
if (!levelWaitingSplits.get(level).isEmpty()) {
long levelTime = levelScheduledTime[level].get();
double ratio = levelTime == 0 ? 0 : targetScheduledTime / (1.0 * levelTime);
if (selectedLevel == -1 || ratio > worstRatio) {
worstRatio = ratio;
selectedLevel = level;
}
}
targetScheduledTime /= levelTimeMultiplier;
}
if (selectedLevel == -1) {
return null;
}
PrioritizedSplitRunner result = levelWaitingSplits.get(selectedLevel).poll();
checkState(result != null, "pollSplit cannot return null");
return result;
}
pollSplit的调度逻辑是:
首先,每一个level,都有一个目标的总调度时间,然后这样的level,即这个level对应的已经使用的调度时间占总调度时间的比例最小。
waitSplit中存放的是一个实现了Comparable接口的PrioritizedSplitRunner, 从名字可以看到,这个PrioritizedSplitRunner由于实现了Comparable接口,因此TaskRunner.run()中从waitingSplit中取出SplitRunner执行的时候,就已经是按照优先级排列顺序取出的,那么,这个优先级是怎么定义的呢?我们看一下PrioritizedSplitRunner实现的compareTo方法:
@Override
public int compareTo(PrioritizedSplitRunner o)
{
int result = Long.compare(priority.get().getLevelPriority(), o.getPriority().getLevelPriority());
if (result != 0) {
return result;
}
return Long.compare(workerId, o.workerId);
}
我们看一下PrioritizedSplitRunner的process()方法,可以看到,在每次一个SplitRunner(实际上的实现是DriverSplitRunner)调用完processFor(SPLIT_RUN_QUANTA)以后,这个SplitRunner的优先级都会被更新:
public ListenableFuture<?> process()
{
try {
long startNanos = ticker.read();
....
waitNanos.getAndAdd(startNanos - lastReady.get());
CpuTimer timer = new CpuTimer();
ListenableFuture<?> blocked = split.processFor(SPLIT_RUN_QUANTA);
CpuTimer.CpuDuration elapsed = timer.elapsedTime();
long quantaScheduledNanos = ticker.read() - startNanos;
scheduledNanos.addAndGet(quantaScheduledNanos);
//重新设置这个PrioritySplitRunner的优先级
priority.set(taskHandle.addScheduledNanos(quantaScheduledNanos));
.....
return blocked;
}
catch (Throwable e) {
finishedFuture.setException(e);
throw e;
}
}
从代码可以看到,优先级的设置是使用taskHandle.addScheduledNanos()来获取新的优先级;
TaskRunner的执行策略是不断从waitingSplit中取出SplitRunner来执行,但是只会执行一段时间(默认1s),然后当1s中的时间片结束,开始进行如下判断:
-
如果发现SplitRunner的状态已经结束,代表这个SplitRunner下面的所有的Split的执行都已经结束,开始运行splitFinished逻辑,结束逻辑主要包括:
-
运行时间统计: 对这个
SplitRunner的运行时间进行相关统计,比如等待时间,调度时间,cpu耗时等等 -
引用数据清理:由于
TaskHandle负责管理当前Task的所有的SplitRunner的生命周期,因此TaskHandle此时会负责清理掉这个SplitRunner的相关信息 -
调度新的Task:
TaskHandle会负责从自己的queuedSplit中取出新的SplitRunner(如果有的话), 对这个split执行startSplit操作;startSplit操作的主要内容,就是把这个SplitRunner放入到TaskExecutor.waitingSplit队列,等待自己的运行时间片:private synchronized void scheduleTaskIfNecessary(TaskHandle taskHandle) { // if task has less than the minimum guaranteed splits running, // immediately schedule a new split for this task. This assures // that a task gets its fair amount of consideration (you have to // have splits to be considered for running on a thread). if (taskHandle.getRunningLeafSplits() < minimumNumberOfDriversPerTask) { PrioritizedSplitRunner split = taskHandle.pollNextSplit(); if (split != null) { startSplit(split); splitQueuedTime.add(Duration.nanosSince(split.getCreatedNanos())); } } } private synchronized void startSplit(PrioritizedSplitRunner split) { allSplits.add(split); waitingSplits.offer(split); }
-
这里的SplitRunner的实现是DriverSplitRunner, 这是DriverSplitRunner.processFor()方法,即创建所需的Driver实现, 然后,调用Driver.run()方法,在指定的时间片内处理这个DriverSplitRunner中的splits(有可能处理完,有可能处理不完),所以DriverSplitRunner.processFor()返回的并不是处理结果,而是一个类似获取结果的一个Future,名字叫做ListenableFuture
@Override
public ListenableFuture<?> processFor(Duration duration)
{
Driver driver;
synchronized (this) {
// if close() was called before we get here, there's not point in even creating the driver
if (closed) {
return Futures.immediateFuture(null);
}
if (this.driver == null) {
this.driver = driverSplitRunnerFactory.createDriver(driverContext, partitionedSplit);
}
driver = this.driver;
}
return driver.processFor(duration);
}
从类的名字可以看到,DriverSplitRunner用来管理Driver, 驱动Driver下面所有的
然后,针对这个split,创建对应的Driver, 并调用Driver的processFor():
public ListenableFuture<?> processFor(Duration duration)
{
checkLockNotHeld("Can not process for a duration while holding the driver lock");
requireNonNull(duration, "duration is null");
// if the driver is blocked we don't need to continue
SettableFuture<?> blockedFuture = driverBlockedFuture.get();
if (!blockedFuture.isDone()) {
return blockedFuture;
}
long maxRuntime = duration.roundTo(TimeUnit.NANOSECONDS);
Optional<ListenableFuture<?>> result = tryWithLock(100, TimeUnit.MILLISECONDS, () -> {
OperationTimer operationTimer = createTimer();
driverContext.startProcessTimer();
driverContext.getYieldSignal().setWithDelay(maxRuntime, driverContext.getYieldExecutor());
try {
long start = System.nanoTime();
do {
ListenableFuture<?> future = processInternal(operationTimer);
if (!future.isDone()) {
return updateDriverBlockedFuture(future);
}
}
while (System.nanoTime() - start < maxRuntime && !isFinishedInternal());
}
finally {
driverContext.getYieldSignal().reset();
driverContext.recordProcessed(operationTimer);
}
return NOT_BLOCKED;
});
return result.orElse(NOT_BLOCKED);
}
从这段代码里面我们其实可以看到Presto是如何实现时间片控制的, 关键代码在这里:
driverContext.getYieldSignal().setWithDelay(maxRuntime, driverContext.getYieldExecutor());
public synchronized void setWithDelay(long maxRunNanos, ScheduledExecutorService executor)
{
checkState(yieldFuture == null, "there is an ongoing yield");
checkState(!isSet(), "yield while driver was not running");
this.runningSequence++;
long expectedRunningSequence = this.runningSequence;
yieldFuture = executor.schedule(() -> {
synchronized (this) {
if (expectedRunningSequence == runningSequence && yieldFuture != null) {
yield.set(true); //按照时间片设置delay,当时间片到期,设置yield标记位
}
}
}, maxRunNanos, NANOSECONDS);
}
基本思想是,假如说,当前这个Driver获取了1s的时间片,那么, 我就设置一个delay为一秒的Future,即这个Future会在1s以后被调度,被调度的时候,把一个yield变量设置为true,然后,就是各个不同的Operator去自行check这个标记位,我们以ScanFilterAndProjectOperator为例:
private Page processPageSource()
{
DriverYieldSignal yieldSignal = operatorContext.getDriverContext().getYieldSignal();
if (!finishing && mergingOutput.needsInput() && !yieldSignal.isSet()) {
Page page = pageSource.getNextPage();
可以看到,每一次取出一个page的时候,都会检查yieldSignal,如果被set了,那么就不会往下去取了,因为时间片已经用完了;
我们从Driver的变量可以看到,Driver其实是data source 和一系列Operator的组合, data source 的意思代表了一系列即将被顺序读取的split, operator代表了对这些split数据的处理过程,常见的Operator的实现有比如用来直接读取底层table的TableScanOperator, 用来进行跨stage的exchange操作的ExchangeOperator, 用来扫描表中的数据然后对数据进行过滤和字段投射的ScanFilterAndProjectOperator等等。我们可以通过全局搜索implements SourceOperator获取到接口SourceOperator的所有实现;
private static final Logger log = Logger.get(Driver.class);
private final DriverContext driverContext;
private final List<Operator> activeOperators;
// this is present only for debugging
@SuppressWarnings("unused")
private final List<Operator> allOperators;
private final Optional<SourceOperator> sourceOperator;
private final Optional<DeleteOperator> deleteOperator;
// This variable acts as a staging area. When new splits (encapsulated in TaskSource) are
// provided to a Driver, the Driver will not process them right away. Instead, the splits are
// added to this staging area. This staging area will be drained asynchronously. That's when
// the new splits get processed.
private final AtomicReference<TaskSource> pendingTaskSourceUpdates = new AtomicReference<>();
private final Map<Operator, ListenableFuture<?>> revokingOperators = new HashMap<>();
private final AtomicReference<State> state = new AtomicReference<>(State.ALIVE);
private final DriverLock exclusiveLock = new DriverLock();
@GuardedBy("exclusiveLock")
private TaskSource currentTaskSource;
我们看一下TaskSource类的定义,可以知道一个TaskSource是一系列需要进行处理的Split集合:
public class TaskSource
{
private final PlanNodeId planNodeId;
private final Set<ScheduledSplit> splits;
private final Set<Lifespan> noMoreSplitsForLifespan;
private final boolean noMoreSplits;
Driver的核心方法是process() -> processInternal():
在processInternal()方法开始,会调用processNewSources()方法,用来获取将要进行处理的新的split集合,放到Driver的source里面:
@GuardedBy("exclusiveLock")
private ListenableFuture<?> processInternal(OperationTimer operationTimer)
{
checkLockHeld("Lock must be held to call processInternal");
handleMemoryRevoke();
try {
processNewSources();
// If there is only one operator, finish it
// Some operators (LookupJoinOperator and HashBuildOperator) are broken and requires finish to be called continuously
// TODO remove the second par SPILLING_INPUTt of the if statement, when these operators are fixed
// Note: finish should not be called on the natural source of the pipeline as this could cause the task to finish early
if (!activeOperators.isEmpty() && activeOperators.size() != allOperators.size()) {
Operator rootOperator = activeOperators.get(0);
rootOperator.finish();
rootOperator.getOperatorContext().recordFinish(operationTimer);
}
boolean movedPage = false;
for (int i = 0; i < activeOperators.size() - 1 && !driverContext.isDone(); i++) {
Operator current = activeOperators.get(i);
Operator next = activeOperators.get(i + 1);
// skip blocked operator and start to check the next operator
if (getBlockedFuture(current).isPresent()) {
continue;
}
// if the current operator is not finished and next operator isn't blocked and needs input...
if (!current.isFinished() && !getBlockedFuture(next).isPresent() && next.needsInput()) {
// get an output page from current operator
Page page = current.getOutput();
current.getOperatorContext().recordGetOutput(operationTimer, page);
// if we got an output page, add it to the next operator
if (page != null && page.getPositionCount() != 0) {
next.addInput(page);
next.getOperatorContext().recordAddInput(operationTimer, page);
movedPage = true;
}
if (current instanceof SourceOperator) {
movedPage = true;
}
}
// if current operator is finished...
if (current.isFinished()) {
// let next operator know there will be no more data
next.finish();
next.getOperatorContext().recordFinish(operationTimer);
}
}
for (int index = activeOperators.size() - 1; index >= 0; index--) {
if (activeOperators.get(index).isFinished()) {
// close and remove this operator and all source operators
List<Operator> finishedOperators = this.activeOperators.subList(0, index + 1);
Throwable throwable = closeAndDestroyOperators(finishedOperators);
finishedOperators.clear();
if (throwable != null) {
throwIfUnchecked(throwable);
throw new RuntimeException(throwable);
}
// Finish the next operator, which is now the first operator.
if (!activeOperators.isEmpty()) {
Operator newRootOperator = activeOperators.get(0);
newRootOperator.finish();
newRootOperator.getOperatorContext().recordFinish(operationTimer);
}
break;
}
}
// if we did not move any pages, check if we are blocked
if (!movedPage) {
List<Operator> blockedOperators = new ArrayList<>();
List<ListenableFuture<?>> blockedFutures = new ArrayList<>();
for (Operator operator : activeOperators) {
Optional<ListenableFuture<?>> blocked = getBlockedFuture(operator);
if (blocked.isPresent()) {
blockedOperators.add(operator);
blockedFutures.add(blocked.get());
}
}
if (!blockedFutures.isEmpty()) {
// unblock when the first future is complete
ListenableFuture<?> blocked = firstFinishedFuture(blockedFutures);
// driver records serial blocked time
driverContext.recordBlocked(blocked);
// each blocked operator is responsible for blocking the execution
// until one of the operators can continue
for (Operator operator : blockedOperators) {
operator.getOperatorContext().recordBlocked(blocked);
}
return blocked;
}
}
return NOT_BLOCKED;
}
catch (Throwable t) {
......
}
}
How to decide whether or not an operator is blocked or not?
private Optional<ListenableFuture<?>> getBlockedFuture(Operator operator)
{
ListenableFuture<?> blocked = revokingOperators.get(operator);
if (blocked != null) {
// We mark operator as blocked regardless of blocked.isDone(), because finishMemoryRevoke has not been called yet.
return Optional.of(blocked);
}
blocked = operator.isBlocked();
if (!blocked.isDone()) {
return Optional.of(blocked);
}
blocked = operator.getOperatorContext().isWaitingForMemory();
if (!blocked.isDone()) {
return Optional.of(blocked);
}
blocked = operator.getOperatorContext().isWaitingForRevocableMemory();
if (!blocked.isDone()) {
return Optional.of(blocked);
}
return Optional.empty();
}
- As long as the operator instance is in the list of
revokingOperators, we think it is in the blocked status. Please notice that although this operator is in therevokingOperators, but maybe the memory revoking has been finished already, but the corresponding driver has not yet check whether or not it has been finished, so it still exists inrevokingOperators - As long as the
Operator.isBlocked(), we think it is in the blocked status. This depends on the dedicated implements of methodisBlocked() - As long as the operator is waiting for memory, or waiting for revocable memory, we think the operator instance is in blocked status
当TaskRunner的线程选出对应的SplitRunner的process
每一个Driver实际上属于一个Pipeline, 然后Pipeline属于task, task属于stage















 1759
1759

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









