







需要理解在TensorFlow中,是如何:
- 将计算流程表示成图;
- 通过Sessions来执行图计算;
- 将数据表示为tensors;
- 使用Variables来保持状态信息;
- 分别使用feeds和fetches来填充数据和抓取任意的操作结果;
接下来看具体概念:
- TensorFlow 用图来表示计算任务,图中的节点被称之为operation,缩写成op。
- 一个节点获得 0 个或者多个张量 tensor,执行计算,产生0个或多个张量。
图必须在会话(Session)里被启动,会话(Session)将图的op分发到CPU或GPU之类的设备上,同时提供执行op的方法,这些方法执行后,将产生的张量(tensor)返回。
概念描述
张量(Tensor)
其实就是指矩阵。也可以理解为tensorflow中矩阵的表示形式。Tensor的生成方式有很多种,最简单的就如
port tensorflow as tf # 在下面所有代码中,都去掉了这一行,默认已经导入
a = tf.zeros(shape=[1,2])
不过要注意,因为在训练开始前,所有的数据都是抽象的概念,也就是说,此时a只是表示这应该是个1*5的零矩阵,而没有实际赋值,也没有分配空间,所以如果此时print,就会出现如下情况:
print(a) #===>Tensor("zeros:0",shape=(1, 2), dtype=float32)
只有在训练过程开始后,才能获得a的实际值
sess = tf.InteractiveSession()
print(sess.run(a))
#===>[[ 0. 0.]]
这边设计到Session概念,后面会提到
变量(Variable)
一般用来表示图中的各计算参数,包括矩阵,向量等。例如,要表示线性相关的数据模型,那表达式就是
y=Relu(Wx+b)
这里W和b是要用来训练的参数,Relu()是激活函数,那么此时这两个值就可以用Variable来表示。Variable的初始函数有很多其他选项,这里先不提,只输入一个Tensor也是可以的
W = tf.Variable(tf.zeros(shape=[1,2]))
注意,此时W一样是一个抽象的概念,而且与Tensor不同,Variable必须初始化以后才有具体的值。
tensor = tf.zeros(shape=[1,2])
variable = tf.Variable(tensor)
sess = tf.InteractiveSession()
#print(sess.run(variable)) # 会报错
sess.run(tf.initialize_all_variables())
# 对variable进行初始化
print(sess.run(variable))
#===>[[ 0. 0.]]
占位符(placeholder)
是一个抽象的概念。用于表示输入输出数据的格式。告诉系统:这里有一个值/向量/矩阵,现在没法给你具体数值,不过在正式运行的时候会补上的!例如上式中的x和y。因为没有具体数值,所以只要指定尺寸即可
x = tf.placeholder(tf.float32,[1, 5],name='input')
y = tf.placeholder(tf.float32,[None,5],name='input')
上面有两种形式,第一种x,表示输入是一个[1,5]的横向量。
而第二种形式,表示输入是一个[?,5]的矩阵。那么什么情况下会这么用呢?就是需要输入一批[1,5]的数据的时候。比如我有一批共10个数据,那我可以表示成[10,5]的矩阵。如果是一批5个,那就是[5,5]的矩阵。tensorflow会自动进行批处理。
会话(Session)
session是抽象模型的实现者。为什么之前的代码多处要用到session?因为模型是抽象的嘛,只有实现了模型以后,才能够得到具体的值。同样,具体的参数训练,预测,甚至变量的实际值查询,都要用到session,看后面就知道了。
用法说明
构造阶段(construction phase)
组装计算图
计算图(graph):要组装的结构。由许多操作组成。
操作(ops):接受零个或多个输入,返回零个或多个输出。
数据类型:主要分为张量(tensor)、变量(variable)和常量(constant)
张量:多维array或list
创建语句:
tensor_name=tf.placeholder(type,shape, name)
placeholder叫占位符,同样是一个抽象的概念。用于表示输入输出数据的格式。告诉系统:这里有一个值/向量/矩阵,现在没法给出具体数值,不过在正式运行的时候会补上的!
变量:在同一时刻对图中所有其他操作都保持静态的数据
创建语句:
name_variable = tf.Variable(value, name)
初始化语句:
#个别变量
init_op=variable.initializer()
#所有变量
init_op=tf.initialize_all_variables()
#注意:init_op的类型是操作(ops),加载之前并不执行
更新语句:
update_op=tf.assign(variable to be updated, new_value)
常量:无需初始化的变量
创建语句:
name_constant=tf.constant(value)
执行阶段(execution phase)
使用计算图
会话:执行(launch)构建的计算图。可选择执行设备:单个电脑的CPU、GPU,或电脑分布式甚至手机。
创建语句:
#常规
sess = tf.Session()
#交互
sess = tf.InteractiveSession()
#交互方式可用tensor.eval()获取值,ops.run()执行操作
#关闭
sess.close()
执行操作:使用创建的会话执行操作
执行语句:
sess.run(op)
送值(feed):输入操作的输入值
语句:
sess.run([output],feed_dict={input1:value1, input2:value1})
取值(fetch):获取操作的输出值
语句:
#单值获取
sess.run(one op)
#多值获取
sess.run([a list of ops])
创建一个 Session 对象, 如果无任何创建参数, 会话构造器将启动默认图。
会话负责传递 op 所需的全部输入,op 通常是并发执行的。
# 启动默认图.
sess = tf.Session()
# 调用sess 的 'run()' 方法,传入 'product' 作为该方法的参数,
# 触发了图中三个op (两个常量 op 和一个矩阵乘法op),
# 向方法表明,希望取回矩阵乘法op 的输出.
result = sess.run(product)
# 返回值'result' 是一个 numpy `ndarray` 对象.
print result
# ==> [[ 12.]]
# 任务完成,需要关闭会话以释放资源。
sess.close()
下面代码中有tf.initialize_all_variables,是预先对变量初始化,Tensorflow 的变量必须先初始化,然后才有值!而常值张量是不需要的。即使是assign() 操作和 add() 操作,在调用 run() 之前,
它并不会真正执行赋值和相加操作。
上面的代码定义了一个如下的计算图:
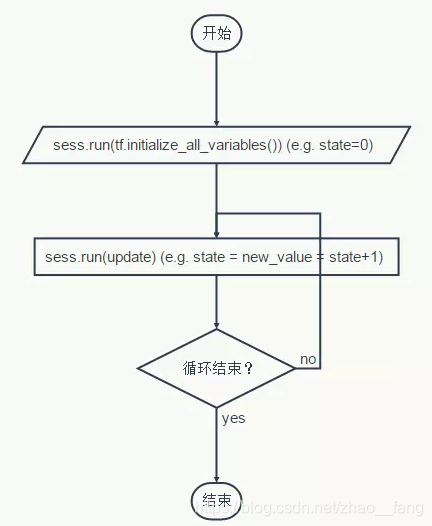
总结一下,来一个清晰的代码:
过程就是:建图->启动图->运行取值
计算矩阵相乘:
import tensorflow as tf
# 建图
matrix1 = tf.constant([[3.,3.]])
matrix2 = tf.constant([[2.],[2.]])
product = tf.matmul(matrix1, matrix2)
# 启动图
sess = tf.Session()
# 取值
result = sess.run(product)print
resultsess.close()
常用函数
算术操作函数
tf.add(x, y, name=None) 求和
tf.sub(x, y, name=None) 减法
tf.mul(x, y, name=None) 乘法
tf.div(x, y, name=None) 除法
tf.mod(x, y, name=None) 取模
tf.abs(x, name=None) 求绝对值
tf.neg(x, name=None) 取负 (y = -x).
tf.sign(x, name=None) 返回符号 y = sign(x)= -1 if x < 0; 0 if x == 0; 1 if x > 0.
tf.inv(x, name=None) 取反
tf.square(x, name=None) 计算平方 (y = x * x = x^2).
tf.round(x, name=None) 舍入最接近的整数
tf.sqrt(x, name=None) 开根号 (y = \sqrt{x} = x^{1/2}).
tf.pow(x, y, name=None) 幂次方
tf.exp(x, name=None) 计算e的次方
tf.log(x, name=None) 计算log,一个输入计算e的ln,两输入以第二输入为底
tf.maximum(x, y, name=None) 返回最大值 (x > y ? x : y)
tf.minimum(x, y, name=None) 返回最小值 (x < y ? x : y)
数据类型转换
tf.string_to_number(string_tensor, out_type=None, name=None) 字符串转为数字
tf.to_double(x, name=’ToDouble’) 转为64位浮点类型–float64
tf.to_float(x, name=’ToFloat’) 转为32位浮点类型–float32
tf.to_int32(x, name=’ToInt32’) 转为32位整型–int32
tf.to_int64(x, name=’ToInt64’) 转为64位整型–int64
tf.cast(x, dtype, name=None) 将x或者x.values转换为dtype
# tensor a is [1.8, 2.2],dtype=tf.float
tf.cast(a, tf.int32) ==> [1, 2] # dtype=tf.int32
矩阵操作
tf.ones | tf.zeros
tf.ones(shape,type=tf.float32,name=None)
tf.zeros([2, 3], int32)
用法类似,都是产生尺寸为shape的张量(tensor)。
tf.ones_like | tf.zeros_like
tf.ones_like(tensor,dype=None,name=None)
tf.zeros_like(tensor,dype=None,name=None)
新建一个与给定的tensor类型大小一致的tensor,其所有元素为1和0。
tf.fill
tf.fill(shape,value,name=None)
创建一个形状大小为shape的tensor,其初始值为value
print(sess.run(tf.fill([2,3],2))) #[[2 2 2], # [2 2 2]]
tf.constant
tf.constant(value,dtype=None,shape=None,name=’Const’)
创建一个常量tensor,按照给出value来赋值,可以用shape来指定其形状。value可以是一个数,也可以是一个list。
如果是一个数,那么这个常亮中所有值的按该数来赋值。
如果是list,那么len(value)一定要小于等于shape展开后的长度。赋值时,先将value中的值逐个存入。不够的部分,则全部存入value的最后一个值。
tf.random_normal | tf.truncated_normal | tf.random_uniform
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
tf.truncated_normal(shape, mean=0.0,
stddev=1.0, dtype=tf.float32, seed=None, name=None)
tf.random_uniform(shape,minval=0,maxval=None,dtype=tf.float32,seed=None,name=None)
这几个都是用于生成随机数tensor的。尺寸是shape
random_normal: 正太分布随机数,均值mean,标准差stddev
truncated_normal:截断正态分布随机数,均值mean,标准差stddev,不过只保留[mean-2stddev,mean+2stddev]范围内的随机数
random_uniform:均匀分布随机数,范围为[minval,maxval]。
tf.get_variable
get_variable(name, shape=None, dtype=dtypes.float32, initializer=None, regularizer=None, trainable=True, collections=None, caching_device=None, partitioner=None, validate_shape=True, custom_getter=None):
如果在该命名域中之前已经有名字=name的变量,则调用那个变量;如果没有,则根据输入的参数重新创建一个名字为name的变量。
name: 这个不用说了,变量的名字
shape: 变量的形状,[]表示一个数,[3]表示长为3的向量,[2,3]表示矩阵或者张量(tensor)
dtype: 变量的数据格式,主要有tf.int32, tf.float32, tf.float64等等
initializer: 初始化工具,有tf.zero_initializer, tf.ones_initializer, tf.constant_initializer, tf.random_uniform_initializer, tf.random_normal_initializer, tf.truncated_normal_initializer等
tf.shape
tf.shape(Tensor)
Returns the shape of a tensor.返回张量的形状。但是注意,tf.shape函数本身也是返回一个张量。而在tf中,张量是需要用sess.run(Tensor)来得到具体的值的。
tf.expand_dims
tf.expand_dims(Tensor, dim) 为张量 +1维。
tf.pack
tf.pack(values,axis=0, name=”pack”)
Packs a list of rank-R tensors into one rank-(R+1) tensor
将一个R维张量列表沿着axis轴组合成一个R+1维的张量。
tf.concat
tf.concat(concat_dim, values, name=”concat”)
Concatenates tensors along one dimension.
将张量沿着指定维数拼接起来。
tf.sparse_to_dense
稀疏矩阵转密集矩阵
定义为:
def sparse_to_dense(sparse_indices, output_shape, sparse_values, default_value=0, validate_indices=True, name=None):
几个参数的含义:
sparse_indices: 元素的坐标[[0,0],[1,2]]表示(0,0),和(1,2)处有值
output_shape:得到的密集矩阵的shape
sparse_values: sparse_indices坐标表示的点的值,可以是0D或者1D张量。若0D,则所有稀疏值都一样。若是1D,则len(sparse_values)应该等于len(sparse_indices)
default_values: 缺省点的默认值
tf.random_shuffle
tf.random_shuffle(value,seed=None,name=None)
沿着value的第一维进行随机重新排列。
tf.argmax | tf.argmin
tf.argmax(input=tensor,dimention=axis)
找到给定的张量tensor中在指定轴axis上的最大值/最小值的位置。
tf.equal
tf.equal(x, y, name=None):
判断两个tensor是否每个元素都相等。返回一个格式为bool的tensor
tf.cast
cast(x, dtype, name=None)
将x的数据格式转化成dtype.例如,原来x的数据格式是bool,那么将其转化成float以后,就能够将其转化成0和1的序列。反之也可以。
tf.matmul
用来做矩阵乘法。若a为lm的矩阵,b为mn的矩阵,那么通过tf.matmul(a,b)
结果就会得到一个l*n的矩阵
不过这个函数还提供了很多额外的功能。我们来看下函数的定义:
matmul(a, b, transpose_a=False, transpose_b=False, a_is_sparse=False, b_is_sparse=False, name=None):
可以看到还提供了transpose和is_sparse的选项。
如果对应的transpose项为True,例如transpose_a=True,那么a在参与运算之前就会先转置一下。
而如果a_is_sparse=True,那么a会被当做稀疏矩阵来参与运算。
tf.reshape
reshape(tensor, shape, name=None)
顾名思义,就是将tensor按照新的shape重新排列。一般来说,shape有三种用法:
如果 shape=[-1], 表示要将tensor展开成一个list
如果 shape=[a,b,c,…] 其中每个a,b,c,…均>0,那么就是常规用法
如果 shape=[a,-1,c,…] 此时b=-1,a,c,…依然>0。这表示tf会根据tensor的原尺寸,自动计算b的值。
其他常用操作
tf.linspace | tf.range
tf.linspace(start,stop,num,name=None)
tf.range(start,limit=None,delta=1,name=’range’)
这两个放到一起说,是因为他们都用于产生等差数列,不过具体用法不太一样。
tf.linspace在[start,stop]范围内产生num个数的等差数列。不过注意,start和stop要用浮点数表示,不然会报错
tf.range在[start,limit)范围内以步进值delta产生等差数列。注意是不包括limit在内的。
tf.assign
tf.assign(ref, value, validate_shape=None, use_locking=None, Name=None)
tf.assign是用来更新模型中变量的值的。ref是待赋值的变量,value是要更新的值。即效果等同于 ref = value 。
简单实例
通过几个例子了解了基本的用法。
生成三维数据后使用平面拟合
import tensorflow as tf
import numpy as np
# 用NumPy 随机生成 100 个数据
x_data = np.float32(np.random.rand(2, 100))
y_data = np.dot([0.100, 0.200], x_data) + 0.300
# 构造一个线性模型
b = tf.Variable(tf.zeros([1]))
W = tf.Variable(tf.random_uniform([1, 2], -1.0, 1.0))
y = tf.matmul(W, x_data) + b
# 最小化方差
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
# 初始化变量
init = tf.initialize_all_variables()
# 启动图 (graph)
sess = tf.Session()
sess.run(init)
# 拟合平面
for step in xrange(0, 201):
sess.run(train)
if step % 20 == 0:
print step, sess.run(W), sess.run(b)
# 输出结果为:
0 [[-0.14751725 0.75113136]] [ 0.2857058]
20 [[ 0.06342752 0.32736415]] [ 0.24482927]
40 [[ 0.10146417 0.23744738]] [ 0.27712563]
60 [[ 0.10354312 0.21220125]] [ 0.290878]
80 [[ 0.10193551 0.20427427]] [ 0.2964265]
100 [[ 0.10085492 0.201565 ]] [ 0.298612]
120 [[ 0.10035028 0.20058727]] [ 0.29946309]
140 [[ 0.10013894 0.20022322]] [ 0.29979277]
160 [[ 0.1000543 0.20008542]] [ 0.29992008]
180 [[ 0.10002106 0.20003279]] [ 0.29996923]
200 [[ 0.10000814 0.20001261]] [ 0.29998815]
计算矩阵相乘
import tensorflow as tf
# 创建一个 常量op, 返回值 'matrix1' 代表这个1x2 矩阵.
matrix1 = tf.constant([[3.,3.]])
# 创建另外一个 常量op, 返回值 'matrix2' 代表这个2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
# 返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)
计算 ‘x’ 减去 ‘a’
# 进入一个交互式 TensorFlow 会话.
import tensorflow as tf
sess = tf.InteractiveSession()
x = tf.Variable([1.0, 2.0])
a = tf.constant([3.0, 3.0])
# 使用初始化器 initializer op 的 run() 方法初始化'x'
x.initializer.run()
# 增加一个减法 sub op, 从 'x' 减去'a'. 运行减法 op, 输出结果
sub = tf.sub(x, a)
print sub.eval()
# ==> [-2. -1.]
使用变量实现一个简单的计数器
# -创建一个变量,初始化为标量 0. 初始化定义初值
state = tf.Variable(0, name="counter")
# 创建一个op, 其作用是使 state 增加1
one = tf.constant(1)
new_value = tf.add(state,one)
update = tf.assign(state,new_value)
# 启动图后,变量必须先经过`初始化`(init) op 初始化, 才真正通过Tensorflow的#initialize_all_variables对这些变量赋初值
init_op = tf.initialize_all_variables()
# 启动默认图,运行 op
with tf.Session() as sess:
# 运行'init' op
sess.run(init_op)
# 打印 'state' 的初始值
# 取回操作的输出内容,可以在使用 Session 对象的run() 调用 执行图时, 传入一些 #tensor, 这些 tensor 会帮助你取回结果.此处只取回了单个节点state,也可以在运行一次 op 时一起取回多个 tensor: result =sess.run([mul, intermed])
print sess.run(state)
# 运行 op, 更新 'state', 并打印 'state'
for_in range(3):
sess.run(update)
print sess.run(state)
# 输出:
# 0
# 1
# 2
# 3














 1008
1008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









