







如果做过dnn的实验,大家可能会发现在对数据进行预处理,例如白化或者zscore,甚至是简单的减均值操作都是可以加速收敛的,例如下图所示的一个简单的例子:
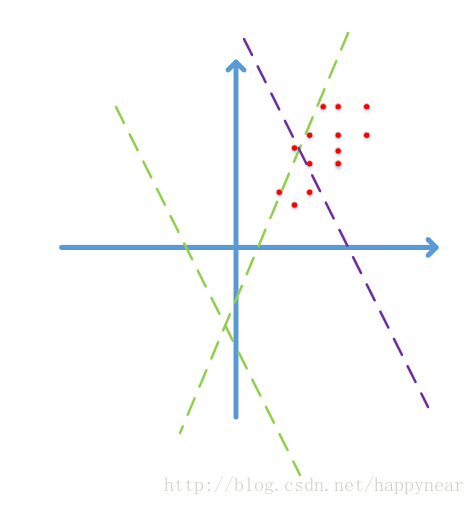
图中红点代表2维的数据点,由于图像数据的每一维一般都是0-255之间的数字,因此数据点只会落在第一象限,而且图像数据具有很强的相关性,比如第一个灰度值为30,比较黑,那它旁边的一个像素值一般不会超过100,否则给人的感觉就像噪声一样。由于强相关性,数据点仅会落在第一象限的很小的区域中,形成类似上图所示的狭长分布。
而神经网络模型在初始化的时候,权重W是随机采样生成的,一个常见的神经元表示为:ReLU(Wx+b) = max(Wx+b,0),即在Wx+b=0的两侧,对数据采用不同的操作方法。具体到ReLU就是一侧收缩,一侧保持不变。
随机的Wx+b=0表现为上图中的随机虚线,注意到,两条绿色虚线实际上并没有什么意义,在使用梯度下降时,可能需要很多次迭代才会使这些虚线对数据点进行有效的分割,就像紫色虚线那样,这势必会带来求解速率变慢的问题。更何况,我们这只是个二维的演示,数据占据四个象限中的一个,如果是几百、几千、上万维呢?而且数据在第一象限中也只是占了很小的一部分区域而已,可想而知不对数据进行预处理带来了多少运算资源的浪费,而且大量的数据外分割面在迭代时很可能会在刚进入数据中时就遇到了一个局部最优,导致overfit的问题。
这时,如果我们将数据减去其均值,数据点就不再只分布在第一象限,这时一个随机分界面落入数据分布的概率增加了多少呢?2^n倍!如果我们使用去除相关性的算法,例如PCA和ZCA白化,数据不再是一个狭长的分布,随机分界面有效的概率就又大大增加了。
不过计算协方差矩阵的特征值太耗时也太耗空间,我们一般最多只用到z-score处理,即每一维度减去自身均值,再除以自身标准差,这样能使数据点在每维上具有相似的宽度,可以起到一定的增大数据分布范围,进而使更多随机分界面有意义的作用。















 3510
3510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









