







目录
1. pageRank算法简介

参考论文:http://ilpubs.stanford.edu:8090/422/1/1999-66.pdf
假设我们有4个网页——w1,w2,w3,w4。这些页面包含指向彼此的链接。有些页面可能没有链接,这些页面被称为悬空页面。
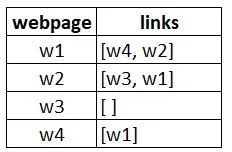
- w1有指向w2、w4的链接
- w2有指向w3和w1的链接
- w4仅指向w1
- w3没有指向的链接,因此为悬空页面
为了对这些页面进行排名,我们必须计算一个称为PageRank的分数。这个分数是用户访问该页面的概率。
如下是概率初始化的步骤:
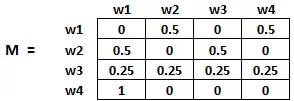
(1)从页面i连接到页面j的概率,也就是M[i][j],初始化为1/页面i的出链接总数wi
(2)如果页面i没有到页面j的链接,那么M[i][j]初始化为0
(3)如果一个页面是悬空页面,那么假设它链接到其他页面的概率为等可能的,因此M[i][j]初始化为1/页面总数
因此在本例中,矩阵M初始化后如下:
PageRank的计算充分利用了两个假设:数量假设和质量假设。步骤如下:
- 在初始阶段:网页通过链接关系构建起Web图,每个页面设置相同的PageRank值,通过若干轮的计算,会得到每个页面所获得的最终PageRank值。随着每一轮的计算进行,网页当前的PageRank值会不断得到更新。
- 在一轮中更新页面PageRank得分的计算方法:在一轮更新页面PageRank得分的计算中,每个页面将其当前的PageRank值平均分配到本页面包含的出链上,这样每个链接即获得了相应的权值。而每个页面将所有指向本页面的入链所传入的权值求和,即可得到新的PageRank得分。当每个页面都获得了更新后的PageRank值,就完成了一轮PageRank计算。
接下来我们根据概率矩阵M,针对每个节点计算对应的PageRank值(假设各个页面初始的PR值均为1):
页面w1的PR值:PR(w1) = 0.5+0.25+1 = 1.75
页面w2的PR值:PR(w2) = 0.5+0.25 = 0.75
页面w3的PR值:PR(w2) = 0.5+0.25 = 0.75
页面w4的PR值:PR(w2) = 0.5+0.25 = 0.75
迭代终止条件:上次迭代结果与本次迭代结果小于某个误差;或者设置最大循环次数。
2. TextRank算法

参考论文:http://web.eecs.umich.edu/~mihalcea/papers/mihalcea.emnlp04.pdf
Textrank是pagerank算法的推广,两种算法的相似之处为:
- 用句子代替网页
- 任意两个句子的相似性等价于网页转换概率
- 相似性得分存储在一个方形矩阵中,类似于PageRank的矩阵M
TextRank算法是一种抽取式的无监督的文本摘要方法。
(1)第一步是把所有文章整合成文本数据
(2)接下来把文本分割成单个句子
(3)然后,我们将为每个句子找到向量表示(词向量)。
(4)计算句子向量间的相似性并存放在矩阵中
(5)然后将相似矩阵转换为以句子为节点、相似性得分为边的图结构,用于句子TextRank计算。
(6)最后,一定数量的排名最高的句子构成最后的摘要。
3. 参考链接
https://ansvver.github.io/pagerank_and_textrank.html















 5575
5575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









