









目录
1.3 精准率(precision)和召回率(recall)
1.4编程实现 confusion_matrix, precision and recall
3.1 通过threshold调整 precision 和recall
3.2 编程计算 在不同threshold 下的precision_score 和 recall_score,更直观的感受一下precision 和 recall的大小也为负相关关系。
3.3 编程,绘制在不同precision_recall_curve
5.多分类问题(Multi-classification problem)
1.混淆矩阵,精准率和召回率
1.1 为什么要引入混淆矩阵,精准率和召回率
在前面KNN,LogisticRegression等分类算法中,我们都是以分类准确度(预测正确的/总的样本数)来评判算法的好坏,但是对于有偏的数据,分类准确度就不是那么有效了。
比如案例1:
一个癌症预测系统,输入体检信息,可以判断是否有癌症
实际癌症产生的概率为0.1%
我们的系统预测所有的人都不患癌症,即可达到99.9%的准确率。
准确率很高,但是我们这个系统什么也没做,一点价值都没有。
再次说明了对于极度偏斜(Skewed Data)的数据,只使用分类准确度是远远不够的
下面,引入混淆矩阵(confusion_matrix)来做进一步的分析。
1.2混淆矩阵(confusion_matrix)

通常在Skewed Data中, 将分类1作为我们真正关注的对象。(比如在癌症预测系统中,1表示患癌症; 在信用系统中,1表示有某人信用不好,有风险)
1.3 精准率(precision)和召回率(recall)
1.3.1 精准率(Precision):
是预测数据为1的正确的概率(即预测数据为1,且预测对了的概率)
Precision = TP/(FP+TP)
TP:预测数据为1,且真实数据也为1
FP+TP:预测数据为1
1.3.2 召回率(recall):
是指我们关注的事件,真实的发生时,我们能成功预测到的概率(即真实数据为1,预测也为1所占的概率)。
Recall = TP/(FN+TP)
TP: 真实数据为1,预测为1
FN+TP: 真实数据为1
案例2:癌症预测系统
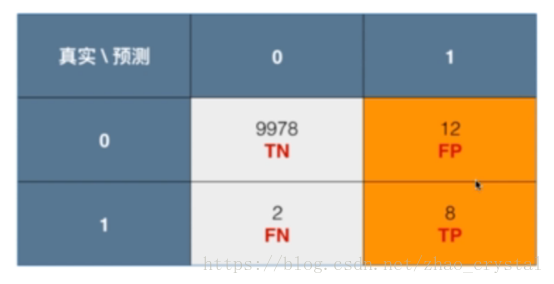
0:negative 不患癌症;1:positive 患癌症
Precision = 8/(8+12) = 40%
Recall = 8/(8+2) = 80%
准确率=(9978+8)/(9978+12+2+8) = 99.86% (显然,如果直接用准确率,“美化”了我们的模型)
案例3:癌症预测系统(对应案例1中的极端情况)的precision and recall
我们预测所有的人都不患癌症(0:negative 不患癌症;1:positive 患癌症;)

对于这个“什么都不干”的预测系统,逃过了准确率的关卡,但确逃不过precision & recall的火眼金睛。
1.4编程实现 confusion_matrix, precision and recall
见github文件confusionMatrix_precisionScore_recallScore.ipynb
2. f1_score
2.1 为什么要引入f1_score
对confusion_matrix, precision and recall 进一步分析

在统计学中,也有类似的矩阵(0:表示假;1:表示真),FP:取伪(放走坏人);FN为弃真(错杀好人),放走坏人的人数比较多(概率比较大),说明“法律”不严格,这样错杀好人的人数肯定就少了(概率就小了)。(想一下,在“法律”评判下,坏人都被放走了,好人肯定也都被放走了,不会被错杀了)。同理,FN比较小,放走的坏人少(概率小),”法律比较严格”,则错杀好人的人数就多(概率就大),FP就比较大。
总而言之,FP 和FN是负相关的,即FP增大,FN减小;FP减小,FN增大。
Precision = TP/(FP+TP)
Recall = TP/(FN+TP)
可以看到,precision and recall 的分子是相同的,precision的分母为(FP+TP),recall的分母为(FN+TP),两者分母中均含有TP,故precision 和 recall 的大小关系就由 FP和FN决定,而FP和FN 是负相关,所以precision 和 recall的大小也为负相关,即precision增大,recall减小;precision减小,recall增大。
当precision 和 recall 这两个指标产生差异时,应该以谁为准呢?
根据具体的场景而定
(1)如案例2中的病人预测系统,我们期望把所有真实患病的人都能预测出来他们患病(即召回率),所以我们更看重recall(召回率)。
而精准率,预测的所有患病的人数中,真实也患病的概率比较小也没关系,此时只是把更多没患病的人预测为患病,最多只是让那些未患病的人多做一点检查罢了。
(2)案例4:股票预测系统
在股票预测系统中,一般我们关注的事情是哪只股票明天涨,今天就买哪只股票。故1:表示某只股价涨 0:表示某只股价跌
我们期望预测的股价涨的股票,实际中也都是上涨的(要不然,实际中他们是跌的,那今天买了,明天跌,岂不是很惨)(即精准率),故在这种情况下,我们更看重precision(精准率)
而召回率(recall),某些股票的股价实际涨了,预测这些股票的股价也涨的概率比较小时(即很多实际上涨的股票,被我们预测为跌,我们没有买,但这并不会对我们造成什么重大的损失),并不会对我们的收益造成影响,只要precision高,买的股票都涨了,一切万事大吉。
(3)还有一些情境中,precision 和 recall同等重要,此时就需要引入两者都兼顾的f1_score
2.2 f1_score
2.2.1 f1_score 的计算
f1_score 是 precision和recall的调和平均
f1_score = 2 / [(1/precision) + (1/recall)],
只要precision 和 recall 有一个比较低,f1_score就很低;只有precision和recall都很高时,f1_score才很高。
eg:precision = 0.5, recall = 0.5时,f1_score = 0.5; (即 当precision=recall时,f1_score =precision=recall)
precision = 0.9, recall = 0.1时,f1_score = 0.18(而如果用算术平均的话,为0.5,不能很好的反应recall比较低的事实)
precision = 1.0,recall = 0时,f1_score无意义,程序中令其为0(而而如果用算术平均的话,为0.5,不能很好的反应recall为0的事实)
2.2.2 f1_score 的程序实现
详见程序 f1_score.ipynb
3. precision_recall_curve
3.1 通过threshold调整 precision 和recall
在某些场景下,我们需要precision_score 大一些,在某些时候,需要recall_score 大一些,又有些时候,需要兼顾两者。通过什么来调整precision_score和recall_score呢?


减小threshold,精准率下降,召回率上升;增大threshold,精准率上升,召回率下降。
3.2 编程计算 在不同threshold 下的precision_score 和 recall_score,更直观的感受一下precision 和 recall的大小也为负相关关系。
逻辑回归中,使用的threshold=0,可通过改变threshold来调整精准率和召回率。其中可用
sklearn.linear_model.LogisticRegression.decision_function(Predict confidence scores for samples)自己定义合适的threshold,得到预测结果。
详见:precision_score_VS_recall_score.ipynb
3.3 编程,绘制在不同precision_recall_curve
(1)首先 通过 LogisticRegression中的方法 decision_function得到scores,从而得到基于不同的threshold 的分类结果,confusion_matrix, precision_score, recall_score.
(2)绘制precision_recall_curve1

(3) 绘制 precision_recall_curve2(也称为PR_curve)
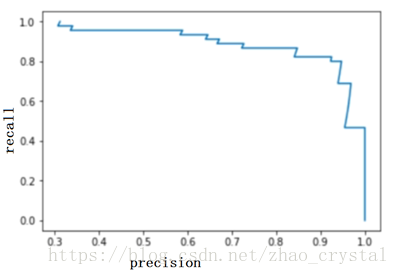
详见代码:precision_recall_curve.ipynb
3.3 PR_curve 分析:
如下图所示,B任意一点的precision 和 recall 都比A的要大,可见B模型比A模型更好。也可以用A 和B包围的面积来评判模型的好坏,包围的面积越大,则表示模型越好。(但一般用ROC曲线包围的面积来评判模型的好坏(具体原因详见4. ROC AUC))

4. ROC AUC
Receiver Operating Characterisitc Area Under Curve
. 

ROC是以特异度(FPR)为纵坐标和灵敏度(TPR)为横纵坐标构成的曲线(实际是折线)。
AUC是ROC “曲线”与y = 0 和x = 1直线所构成的面积。
4.1 ROC_curve,TPR,FPR 的简单介绍
ROC_curve(Receiver Operation Characteristic Curve):描述TPR(True positive rate)和FPR(Flase positive rate)之间的关系。

(1)TPR
TPR(真阳率):即真实是positive,预测的也为positive的概率。
TPR = TP/(TP+FN) = recall
(2)FPR
FPR(假阳率): 即真实是negative,但却预测为positive的概率
FPR = FP/(FP+TN)
(3) TPR 与 FPR 之间的关系

4.2程序实现TPR,FPR 和ROC_curve
TPR_FPR_ROC.ipynb
4.3 ROC_curve 的分析
ROC_curve如下所示:

ROC_curve描述TPR(True positive rate)和FPR(Flase positive rate)之间的关系,由于TPR,FPR对有偏数据不是很敏感,故ROC_curve对有偏数据也不是很敏感。通常我们用ROC_curve 包围的面积来判断模型的好坏。
很显然,模型A要比模型B好。
PR曲线和ROC曲线,他们的核心区别在TN。可以看出来,PR曲线其实不反应TN。所以,如果你的应用场景中,如果TN并不重要,那么PR曲线是一个很好的指标(事实上,Precision和Recall就是通过抹去TN,来去除极度的偏斜数据带来的影响,进而放大FP, FN和TP三者的关系的)。
而ROC曲线则综合了TN, FP, FN和TP。虽然它对TN极度多的情况下,FP,FN和TP的变化不敏感。所以在TN没有那么多(数据没有那么偏斜),或者TN是一种很重要的需要考虑的情况下,ROC能反映出PR不能反映的问题(当我们对正确的预测“0”的出现也很在意的时候,TN是一种很重要的需要考虑的情况,比如对于股票预测,我们不仅需要正确的预测上升期,也需要正确的预测衰退期)。
4.4 AUC总结
负样本排在正样本前面的概率
ps:
在机器学习领域,对于指标,很多时候不是选择谁的问题,而是在可能的情况下,所有的指标都应该看一看,以确定训练的模型是否有问题。这就好比在医院检查身体,不是先确定要看哪个指标,然后就只看这个指标;而是尽可能去看所有指标。因为任何一个指标存在问题,都可能意味着你的身体的某个机能存在问题。
所以,我们的目的不是“找到”单一的“最好”的指标;而是了解所有的指标背后在反映什么,在看到这个指标出现问题的时候,能够判断问题可能出现在哪里,进而改进我们的模型。虽然我们的改进方向可能是单一的。这就好比在医院看病,我们主要症状可能是发烧,此时,我们的主要异常指标是“温度”,所以我们主要尝试使用可以“降温”的治疗手段,但这不代表我们在治疗的过程中对其他指标不管不顾,只要把温度降到正常水平就可以了。在尝试“降温”的过程中,如果我们发现血压,心跳,白血球,红血球,任何一个指标出现异常,我们都需要马上做出相应的反应。
5.多分类问题(Multi-classification problem)
5.1 注意事项
sklearn中的LogisticRegression() 天生能解决多分类问题(使用OVR)
precision_score中的参数average = ‘micro’
recall_score中的参数average = ‘micro’
confusion_matrix 天生能解决多分类问题
5.2 绘制confusion_matrix
为什么要绘制confusion_matrix?
通过绘制confusion_matrix, 可根据颜色,来判断哪些类别比较容易混淆,可以相应的在那个分类中调节threshold来改善模型.当然有时出现混淆可能是因为数据本身的问题。
直接绘制的混淆矩阵如下所示:
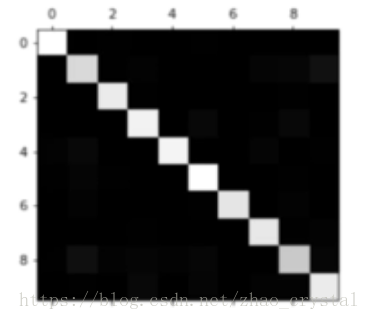
颜色越亮,说明该位置的数值越大。可以看到,对角线的位置(分类正确的)数值较大,初步确定,该分类模型还算不错. 然而,还有一些隐约的亮点不是很确定,这时,可以处理一下confusion_matrix 来使我们想要的信息表现出来。
调整后的confusion_matrix 如下所示:

从图中可以看出,我们很容易混淆(1,8)(3,8),解决办法:
(1) 相应地微调在(1,8)(3,8)分类时的threshold,来提高分类的precision or recall
(2) 分类不准有可能不是在算法层面,而是在数据层面,可以将1,3,8等这些图片拿出来看一下,感性的分析一下为什么会出现分类错误的现象。














 4713
4713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









