







平日没事喜欢了解一下与汽车相关的知识与讯息,经常逛汽车之家,一直觉得汽车之家的车型检索太过“简单”,只能满足一般大部分用户的检索需求,比如6缸车、非承载车身、非双离合、前后独立悬挂、带机械锁的.....等等这些搜索条件都是不支持的,于是就想写个爬虫把站上的数据都爬回来,数据有了,我自己想怎么处理,想怎么搜就都可以了
说干就干,使用比较流行的python编写,之前没接触过,借这个机会正好学习一下,多掌握一门语言
边做边学,看了几篇介绍python爬虫的入门博客及一些python基础语法后,便开始了我的爬虫之旅
爬虫目的:爬下汽车之家网站内所有车型的基本信息,并保存到数据库中,便于日后进行数据搜索
首先,利用chrome对汽车之家网站请求、返回进行分析:
要达到我的目标页面,需要经历以下几个请求
(1)http://www.autohome.com.cn/car/ 直奔车型库页面
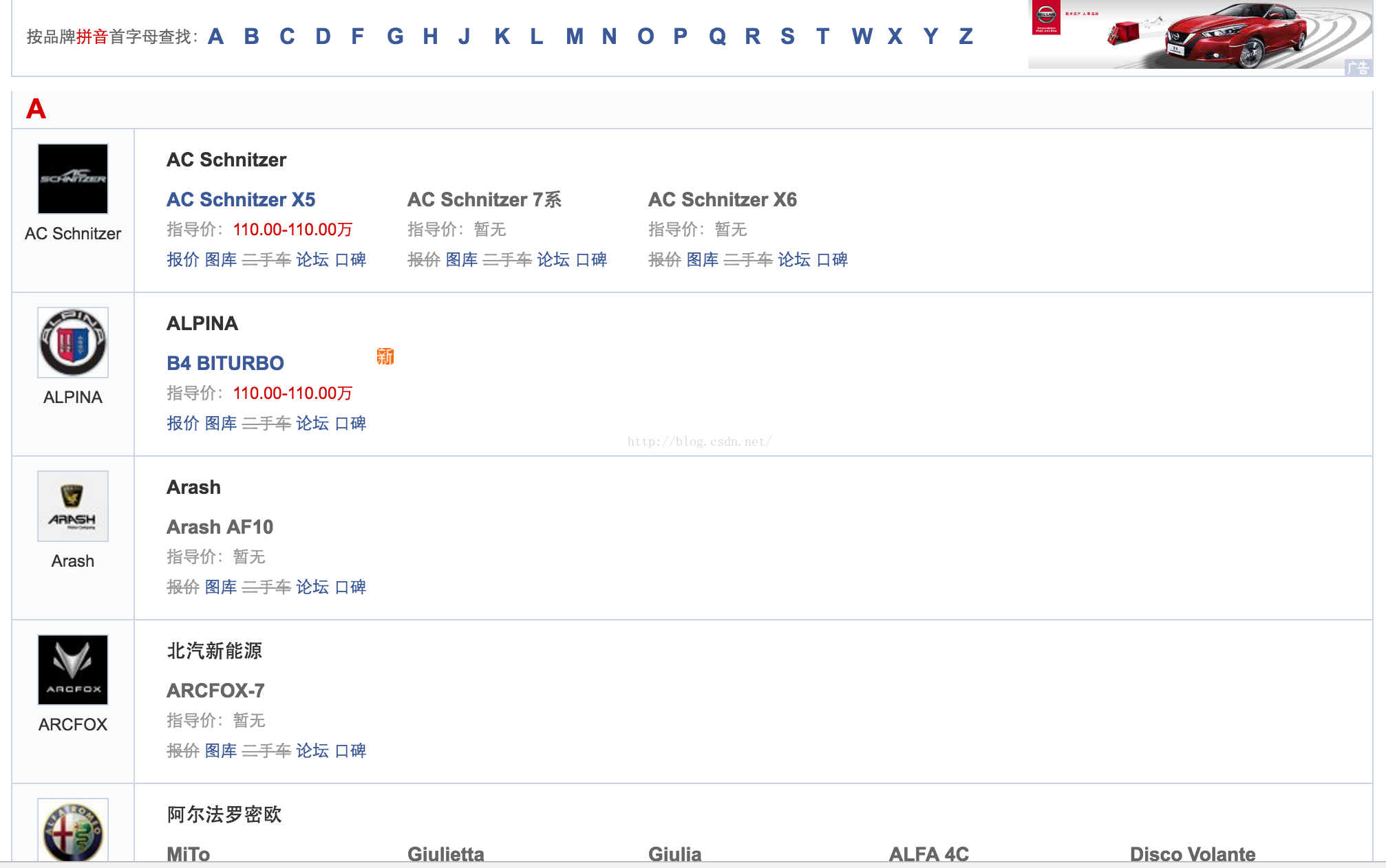
可以看到, 车系都已经按照了首字母进行了归类,随便点击一下N,H,B这些索引字母
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 61万+
61万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









