







一、基石RDD( resilient distributed dataset)
spark的核心就是RDD(弹性分布式数据集),一种通用的数据抽象。封装了基础的数据操作,如map,filter,reduce等。RDD提供数据共享的抽象,相对比其他大数据处理框架,如MapReduce,Pege1,DryadLINQ和HIVE等均缺乏此特性,所以RDD更为通用。
简单的来概括RDD:RDD是一个不可修改的,分布的对象集合。每个RDD由多个分区组成,每个分区可以同时在集群中的不同节点上计算。RDD可以包含Python,Java和Scala的任意对象。
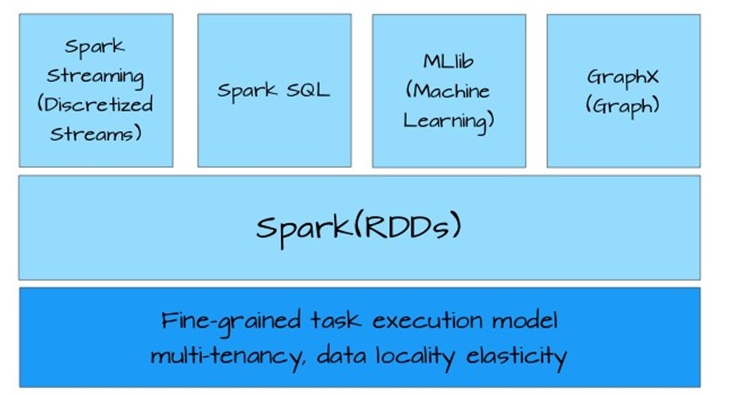
Spark的生态圈中应用都是基于RDD构建(下图),这一点充分说明RDD的抽象足够通用,可以描述大多数应用场景。
RDD创建:
(1)基于hadoop的文件系统中的文件:val rdd=sc.textFile(hdfs文件系统中文件路径)
(2) 一个集合:val listRdd=sc.parallelize(List(“hadoop”,”spark”,”yarn”));或者Array数组
RDD的五大特性:
(1) a list of partitions :一系列的分片,比如说64M一片,类似于Hadoop中的split;
(2)a function for computing each split:在每个分片上都有一个函数去迭代/执行/计算他;
(3)a list of dependencies on others RDDs:一系列的依赖,RDDa转换为RDDb,RDDb转换为RDDc,那么RDDc就依赖于RDDb,RDDb就依赖于RDDa
(4)optionally,a Partitioner for key-value RDDs:对于key-value的RDD可指定一个partitioner,告诉它如何分片,常用的有hash,range
(5) optionally,a list of preferred location(s) to compute each split on : 要运行的计算/执行最好在哪几个机器上运行,数据本地性。
为什么会有那几个呢?比如:hadoop默认有三个位置,或者spark cache到内存是可通过storageLevel设置了多个副本,所以一个partition可能返回多个最佳位置。
二、RDD操作类型——转换与动作
RDD的操作主要分两类:转换(transformation)和动作(action)。两类函数的主要区别是,转换接受RDD并返回RDD,而动作接受RDD但是返回非RDD。转换采用惰性调用机制,每个RDD记录父RDD转换的方法,这种调用链表称之为血缘(lineage);而动作调用会直接计算。
采用惰性调用,通过血缘连接的RDD操作可以管道化(pipeline),管道化的操作可以直接在单节点完成,避免多次转换操作之间数据同步的等待。
使用血缘串联的操作可以保持每次计算相对简单,而不用担心有过多的中间数据,因为这些血缘操作都管道化了,这样也保证了逻辑的单一性,而不用像MapReduce那样,为了竟可能的减少map reduce过程,在单个map reduce中写入过多复杂的逻辑。
三、RDD使用模式
RDD使用具有一般的模式,可以抽象为下面的几步
1. 加载外部数据,创建RDD对象
2. 使用转换(如filter),创建新的RDD对象
3. 缓存需要重用的RDD
4. 使用动作(如count),启动并行计算















 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









