







一、动机
Spark为包含键值对类型的RDD提供了一些专有的操作。这些RDD被称为pairRDD。提供并行操作各个节点或跨界点重新进行数据分组的操作接口。
二、创建Pair RDD
1、在sprk中,很多存储键值对的数据在读取时直接返回由其键值对数据组成的pair RDD。
2、可以调用map()函数,将一个普通的RDD转换为pair RDD。
在Scala中,为了提取键之后的数据能够在函数中使用,同样需要返回二元数组。隐式转换可以让二元数组RDD支持附加的键值对函数。
val pairs=lines.map(x=>(x.split(" ")[0],x))在java中没有自带的二元数组,因此spark的java API让用户使用scala.Tuple2类来创建二元组。可以通过new Tuple2(elem1,emel2)来创建一个新的二元数组,并且可以通过._1()和._2()方法访问其中的元素。java中可以通过调用mapToPair()函数创建pair RDD。
public class CreatePairRDD implements Serializable {
private static final long serialVersionUID = 1L;
private final static SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount" );
private final static JavaSparkContext sc = new JavaSparkContext( sparkConf);
public void createPairRDD(){
JavaRDD<String> rdd= sc.parallelize(Arrays.asList( "1","2" ,"3" ,"4" ,"5" ));
PairFunction<String, String, String> keyData= new PairFunction<String, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String x) throws Exception {
return new Tuple2<String, String>(x.split(" ")[0], x);
}
};
JavaPairRDD<String, String> pairs= rdd.mapToPair( keyData);
System. err.println(pairs );
}
}scala和python从一个内存中的数据集创建pair RDD时,只需要对这个二元数组组成的集合调用SparkContext.parallelize()方法。
而java从内存数据集创建pair RDD的话,则需要使用SparkContext.parallelizePairs()方法。
三、Pair RDD的转化操作
表:对Pair RDD的转化操作(以键值对集合{(1,2),(3,4),(3,6)}为例)

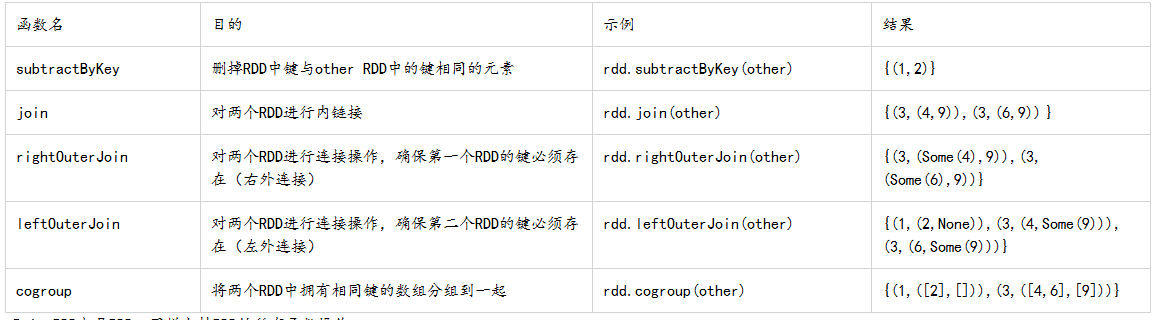
表:针对两个pair RDD的转化操作(rdd={(1,2),(3,4),(3,6)} other ={(3,9)})
Pair RDD也是RDD,同样支持RDD的所有函数操作。
用scala对第二个元素进行筛选
pairs.filter(case(key,value)=>value.length<20)用java对第二个元素进行筛选
Function<Tuple2<String, String>, Boolean> longWordFilter=new Function<Tuple2<String,String>, Boolean>() {
@Override
public Boolean call(Tuple2<String, String> keyValue) throws Exception {
return (keyValue._2().length()<20);
}
};
JavaPairRDD<String, String> result=rdd.filter(longWordFilter);1、聚合操作
pair RDD上择优相应的针对键的转化操作。
Scala中使用mapValues()和reduceByKey()计算每个键对应的平均值:
rdd.mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
用Scala实现单词计数:
val input=sc.textFile(path)
val word=input.flatMap(x=>x.split(" "))
val result=word.map(s=>(x,1)).reduceByKey((x,y)=>(x+y))用Java实现单词计数:
public class WordCount implements Serializable {
private static final long serialVersionUID = 1L;
private final static SparkConf sparkConf = new SparkConf().setAppName("JavaWordCount" );
private final static JavaSparkContext sc = new JavaSparkContext( sparkConf);
public void wordCount(){
JavaRDD<String> input= sc.textFile("hdfs://hadoop:8020/words.txt" );
JavaRDD<String> words= input.flatMap( new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(String x ) throws Exception {
return Arrays.asList( x.split( " ")).iterator();
}
});
JavaPairRDD<String, Integer> result=words .mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String x) throws Exception {
return new Tuple2<String, Integer>(x, 1);
}
}).reduceByKey( new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer x , Integer y ) throws Exception {
return x +y ;
}
});
}
}combineByKey()是最为常用的基于键进行聚合的函数。可以让用户返回与输入数据的类型不同的返回值。对于一个新的元素,combineByKey()会使用一个叫做createCombiner()的函数来创建那个键对应的累加器的初始值。这个过程在每个分区第一次出现各个键时发生,而不是在整个RDD中第一次出现一个键时发生。如果这个键在处理当前分区之前已经遇到的键,他会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并。
由于每个分区是独立处理的,因此对于一个键可以用多个累加器。如果有两个或者多的分区都有对应同一个键的累加器,就需要使用mergeCombiners()方法将各个分区的结果进行合并。
2、并行度调优
Spark提供了repartion()函数。他会把数据通过网络进行混洗。并创建出新的分区集合。对数据分区是代价比较大。
优化版的repartion()函数叫做coalesce()。java或者Scala可以使用rdd.partitions.size查看RDD的分区数。并确保调用coalesce()时将RDD合并到比现在的分区更少的分区中。
3、数据分组
groupByKey()使用RDD中的键对数据进行分组。对于一个由类型k的键和类型v的值组成的RDD,所得到的结果RDD类型会是[K,Iterable[V]];groupByKey可以用于未成对的数据上,也可以根据除键相同以外的条件进行分组。它可以接受一个函数,对源RDD中的每个元素使用该函数,将返回结果作为键在进行分组。
cogroup()函数对多个共享同一个键的RDD进行分组。对两个键类型均为K而值的类型分别为V和W的RDD进行cogroup()时,得到的结果RDD类型为[(K,(Iterable[V],Iterable[W]))].
4、连接
普通的join连接是内链接,只有在两个Pair RDD中都存在的键菜叫输出。当一个输入对应的某个键有多个值时生成的Pair RDD会包括来自两个输入RDD的每一组相对应的记录。
leftOuterJoin()源RDD的每一个键都有对应的记录。每个键相对应的值是由一个源RDD的值与一个包含第二个RDD的值的option对象组成的二元数组。而rightOuterJoin()的结果与其相反。
5、数据排序
使用sortByKey()函数接受一个参数,表示是否让结果按升序排列(默认是true)
四、Pair RDD的行动操作
pair RDD的行动操作 (以键值对集合{(1,2),(3,4),(3,6)})为例:
















 281
281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









