







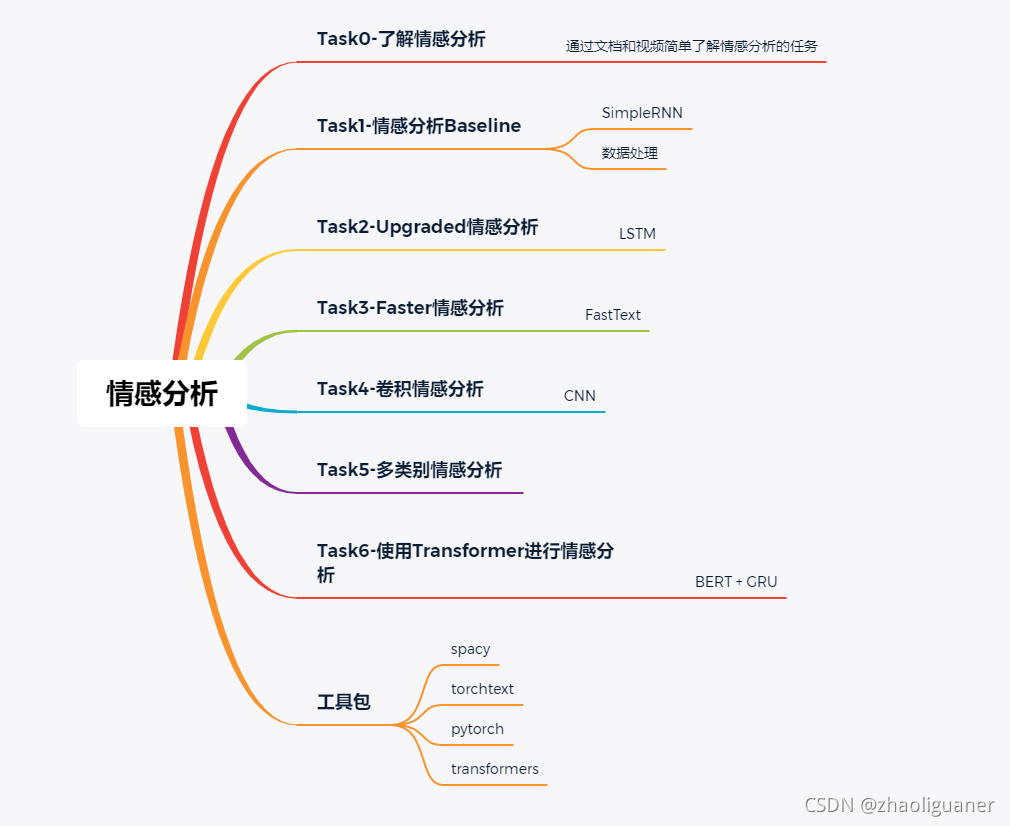
文章目录
总览
**学习方法:**看完文档后自己总结一遍,用笔记的方式记录下来,然后跑通代码,弄明白每行代码调用的模型、参数的含义,记录过程中遇到的问题和解决方法,类比不同的情况。
工具包介绍
TorchText
- 主要概念之一是Field,定义了应如何处理数据,可调用Spacy进行数据处理。
- 终于找到满意的pytorch文字版教程了,感动。
- 关于torchtext的讲解
Spacy
用于分割字符串,可将一句话分割为各个单词;针对不同的语言可调用不同的分割模型。
数据集介绍
电影评论数据集:IMDb数据集。标签分为两类:pos和neg。训练集和测试集各25000条~
TREC数据集:6个类,只有约 3800 个训练样本,词汇量约 7500 个不同单词。

RNN模型
- 在这个模型中,每个单词使用的是相同的RNN,即每个隐层的参数相同。初始隐层的状态 h0 是一个初始化为全0的张量。
构建词汇表vocal
- 使用Spacy分词完毕后,为每个词构建one-hot向量。可选取前n个次数最多的词作为one-hot的基;也可忽略次数小于m的单词。
- 有些单词在数据集中出现了,但却无法直接进行one-hot编码。这里我们使用一个特别的来编码它们。举个例子,如果我们的句子是"This film is great and I love it",但是单词"love"不在词汇表中,那么我们将这句话转换成:“This film is great and I it”。
#构建词汇表,将词汇构建为独热编码
MAX_VOCAB_SIZE = 25000
TEXT.build_vocab(train_data, max_size = MAX_VOCAB_SIZE)
LABEL.build_vocab(train_data)
创建迭代器
使用一个“BucketIterator”,它是一种特殊类型的迭代器,它将返回一批示例,其中每个样本的长度差不多,从而最小化每个样本的padding数。在该步才进行padding补充。
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, valid_iterator, test_iterator = data.BucketIterator 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2782
2782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









