







决策树学习总结
机器学习的应用越来越广泛,特别是在数据分析领域。本文是我学习决策树算法的一些总结。
机器学习简介
机器学习 (Machine Learning) 是近 20 多年兴起的一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。简而言之,机器学习是通过学习老知识(训练样本),得出自己的认知(模型),去预测未知的结果。
- 学习方式
- 监督式学习
- 从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据此函数预测结果。训练数据集中的目标由人标注的。常见的算法有回归分析和统计分类
- 非监督式学习
- 与监督式学习相比,训练集没有人为标注的结果,常见的算法有聚类
- 半监督式学习
- 训练集部分被标识,部分没有被标识。常见的算法有SVM
- 强化学习
- 输入数据作为模型的反馈,模型对此作出调整。常见的算法有时间差学习
- 监督式学习
- 机器学习算法分类
- 决策树算法
- 根据数据属性,采用树状结构建立决策模型。常用来解决分类和回归问题。
- 常见算法:CART(Classification And Regression Tree),ID3,C4.5,随机森林等
- 回归算法
- 对连续值预测,如逻辑回归LR等
- 分类算法
- 对离散值预测,事前已经知道分类,如k-近邻算法
- 聚类算法
- 对离散值预测,事前对分类未知,如k-means算法
- 神经网络
- 模拟生物神经网络,可以用来解决分类和回归问题
- 感知器神经网络(Perceptron Neural Network) ,反向传递(Back Propagation)和深度学习(DL)
- 集成算法
- 集成几种学习模型进行学习,将最终预测结果进行汇总
- Boosting、Bagging、AdaBoost、随机森林 (Random Forest) 等
- 决策树算法
决策树算法
初识决策树
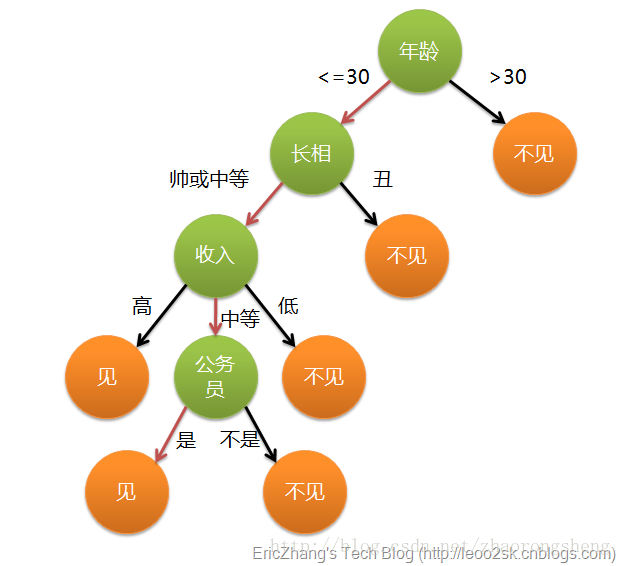
决策树算法是借助于树的分支结构实现分类。以相亲约会决策为例,下图是建立好的决策树模型,数据的属性有4个:年龄、长相、收入、是否公务员,根据此模型,可以得到最终是见或者不见。
这样,我们对决策树有个初步认识:- 叶子节点:存放决策结果
- 非叶子节点:特征属性,及其对应输出,按照输出选择分支
- 决策过程:从根节点出发,根据数据的各个属性,计算结果,选择对应的输出分支,直到到达叶子节点,得到结果
构建决策树
通过上述例子,构建过程的关键步骤是选择分裂属性,即年龄、长相、收入、公务员这4个属性的选择先后次序。分裂属性是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让各个分裂子集尽可能的“纯”,即每个子集尽量都属于同一分类项。分裂属性分3种情况:- 属性是离散值且不要求生成二叉树
- 属性的每个值作为一个分支
- 属性是离散值且要求生成二叉树
- 按照“属于”和“不属于”分成2个分支
- 属性是连续值
- 确定一个分裂点split_point,按照>split_point和<=split_point生成2个分支
注意,决策树使用自顶向下递归分治法,并采用不回溯的
贪心策略。分裂属性的选择算法很多,这里介绍3种常用的算法:信息增益(Information gain)、增益比率(gain ratio)、基尼指数(Gini index)- 属性是离散值且不要求生成二叉树
- 信息增益(Information Gain)
基于香浓的信息论,信息熵表示不确定度,均匀分布时,不确定度最大,此时熵就最大。当选择某个特征对数据集进行分类时,数据集分类后的信息熵会比分类前的小,其差值即为信息增益。信息增益可以衡量某个特征对分类结果的影响大小,越大越好。
- 典型算法:ID3
- 数据集D中,有m个类别,\( p_i \)表示D中属于类别i的概率,此数据集的信息熵定义为:
Info(D)=−∑_i=1mp_ilog_2(p_i)
- 以属性R作为分裂属性,R有k个不同的取值,将数据D划分成k组,按R分裂后的数据集的信息熵为:
Info_R(D)=∑_j=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1260
1260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









