








在大数据和云计算普遍的今天,越来越多的应用使用了Apache下zookeeper这个利器,举几个家喻户小的,像HBase,Kafka,国内阿里巴巴开源的Dubbo等。
首先来了解下zookeeper,原型是Google的Chubby,数据结构是树,我个人理解其实zookeeper也是nosql的一种,是一个非关系型数据库,里面存储的是树结构的数据,包括结点与关系,还有结点上存储的数据。不过zookeeper的强大之处还不是nosql,他的强大之处在于内部的集群机制与事件机制,我说的集群机制是指zookeeper的集群中的选举算法,涉及FAST PAXOS和两段提交算法,相比我看过的hazelcast这个集群下内存共享的组件的选举算法要复杂。还的一点就是事件的监听与处理机制,我在工作中使用到的包括结点的变化事件和结点的子树变化事件等,前者适用与系统的配置的管理,后者则适用于故障监听和失效转移。
用我之前博客里的图为例:
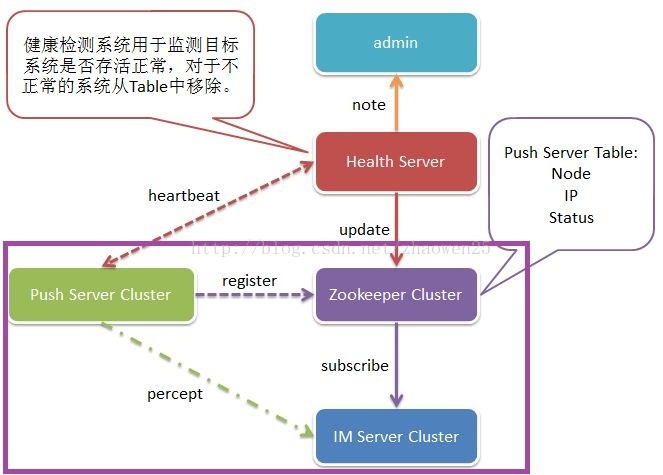
主要是紫色圈起来的部分,集群中的系统部件以TCP连接到zookeeper上,在一个结点下创建一个临时的子结点,当连接到zookeeper的部件发生故障与zookeeper之间的socket断开后,zookeeper中的父结点会产生一个子树发生变化的事件,这样对于订阅了这个父结点子树变化的系统会收会通知。这个功能特别适用于Service的消费方与提供方之间进行可靠的选择。
还以苹果消息通知推送系统为例,服务消息方先订阅事件,并做事件变化的处理:
zkClient.subscribeChildChanges(apnsnode, new IZkChildListener() {
@Override
public void handleChildChange(String parentPath,
List<String> currentChilds) throws Exception {
MQUtil.getInstance().setQueues(currentChilds);
for (String queue : currentChilds) {
amqpAdmin.declareQueue(new Queue(PRD_PRIX + queue, true,
false, false));
amqpAdmin.declareBinding(new Binding(PRD_PRIX + queue,
DestinationType.QUEUE, PRD_PRIX + exchange, queue,
null));
amqpAdmin.declareQueue(new Queue(DEV_PRIX + queue, true,
false, false));
amqpAdmin.declareBinding(new Binding(DEV_PRIX + queue,
DestinationType.QUEUE, DEV_PRIX + exchange, queue,
null));
}
}
});而服务的提供方要做的就是将自己注册到结点上:
public void init() {
// 创建连接
zkClient = new ZkClient(address);
// 如果根结点不存在则创建根结点
if (!zkClient.exists(apnsnode)) {
zkClient.createPersistent(apnsnode);
}
String prefix = "";
try {
// 以IP地址为前辍
prefix = Inet4Address.getLocalHost().getHostAddress();
} catch (UnknownHostException e) {
}
// 创建CPU核心个数队列
int number = Runtime.getRuntime().availableProcessors();
for (int i = 0; i < number; i++) {
// 队列名
String node = prefix + "." + i;
// 子结点名
String path = apnsnode + "/" + node;
if (!zkClient.exists(path)) {
// 创建临时结点
zkClient.createEphemeral(path);
}
queues.add(node);
}
}这个功能也是zookeeper被广泛应用的主要原理,当然,zookeeper还有很多值得研究和学习的地方,推荐大家好好的研究和使用一下zookeeper,我在工作中已经在很多场景中使用,有一个是用zookeeper做的一个系统功能的开关,也就是用他做配置管理。
相信在大数据和云计算下zookeeper一定会被应用越来越广,性能也会越来越好。















 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









