






美团大规模KV存储挑战与架构实践–图文分析
原作者:美团技术团队
原文链接:https://tech.meituan.com/2024/03/15/kv-squirrel-cellar.html
1 美团 KV 存储发展历程
第一代:使用Memcached
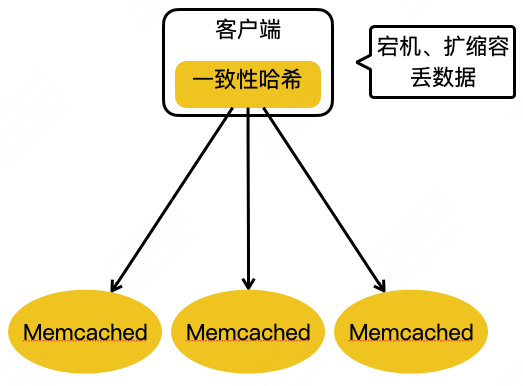
什么是一致性哈希?
哈希:hash,可以通过Key存储Value,也可以通过Key取得Value. 简单说就是Value存储的位置是通过Hash算法计算出来的
(实现,如HashMap)。
随着客户端发起的请求数量越来越高,为了加快响应速度,在客户端与数据库之间增加了缓存层,把数据库中的热点数据存入缓存,这样客户端可以直接从缓存取得热点数据,无需每次都访问数据库,即加快了响应时间,又降低了数据库层的压力。

hash取模运算
随着业务规模不断扩大,数据量也跟着增大,缓存数量飙增,这样就需要考据搭建缓存集群,把大量的缓存分散到多台缓存服务器中进行存储。
取模算法hash(key)%N,即:对缓存数据的key进行hash运算后取模,N是机器的数量;运算后的结果映射对应集群中的节点。具体如下图所示:

问题,如上图,三个node,所以N为3,此时key通过公式hash(key)%3存入指定节点,之后扩容成4个节点,N为4,公式也变成了hash(key)%4,之前n为3的值取不出来了。
一致性哈希
一致性哈希算法将整个哈希值空间映射成一个虚拟的圆环。整个哈希空间的取值范围为02^32-1,按顺时针方向开始从0232-1排列,最后的节点232-1在0开始位置重合,形成一个虚拟的圆环。
对服务器IP地址进行哈希计算,哈希计算后的结果对232取模,结果一定是一个0到232-1之间的整数。最后将这个整数映射在哈希环上,整数的值就代表了一个服务器节点的在哈希环上的位置。即:hash(服务器ip)% 2^32。
当服务器接收到数据请求时,首先需要计算请求Key的哈希值;然后将计算的哈希值映射到哈希环上的具体位置;接下来,从这个位置沿着哈希环顺时针查找,遇到的第一个节点就是key对应的节点
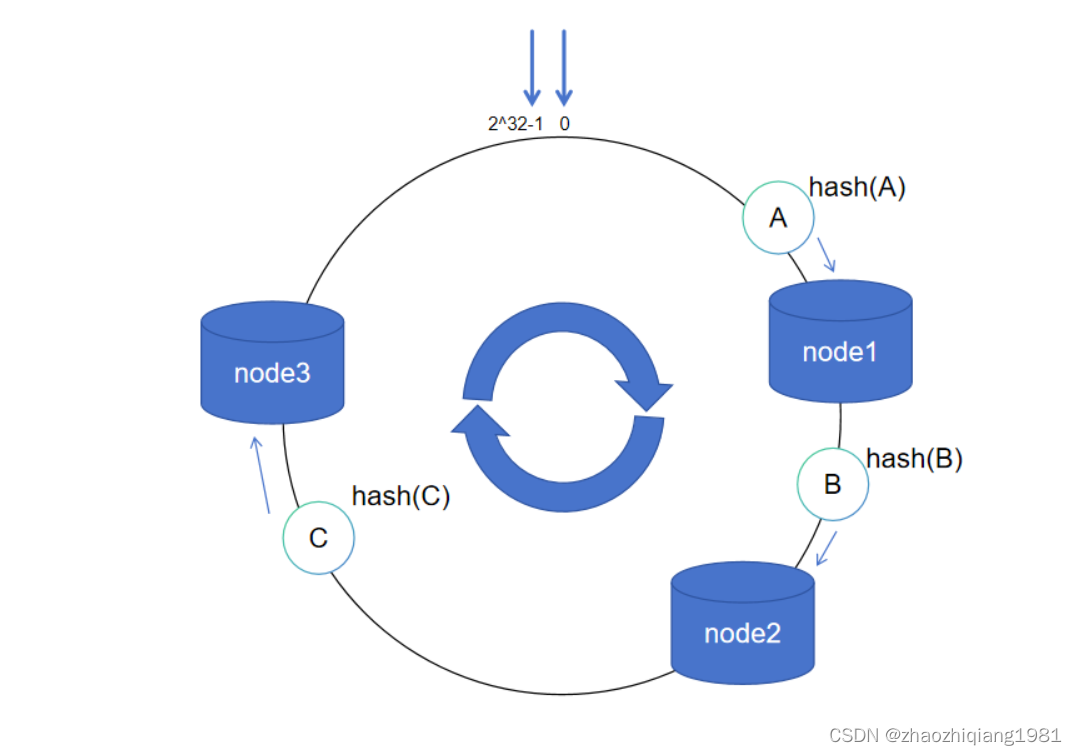
服务器扩容
D数据本来应该会落在node1中,由于扩容节点node4,D数据落在了node4中
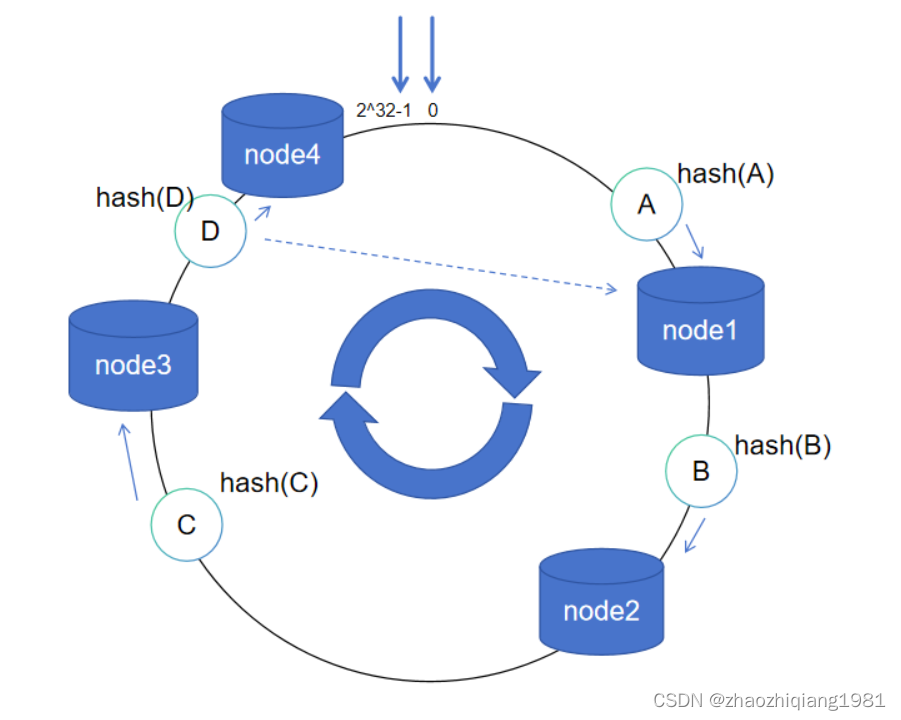
服务器缩容
node4节点宕机或者移除后,数据D继续顺时针找到node1节点存储。
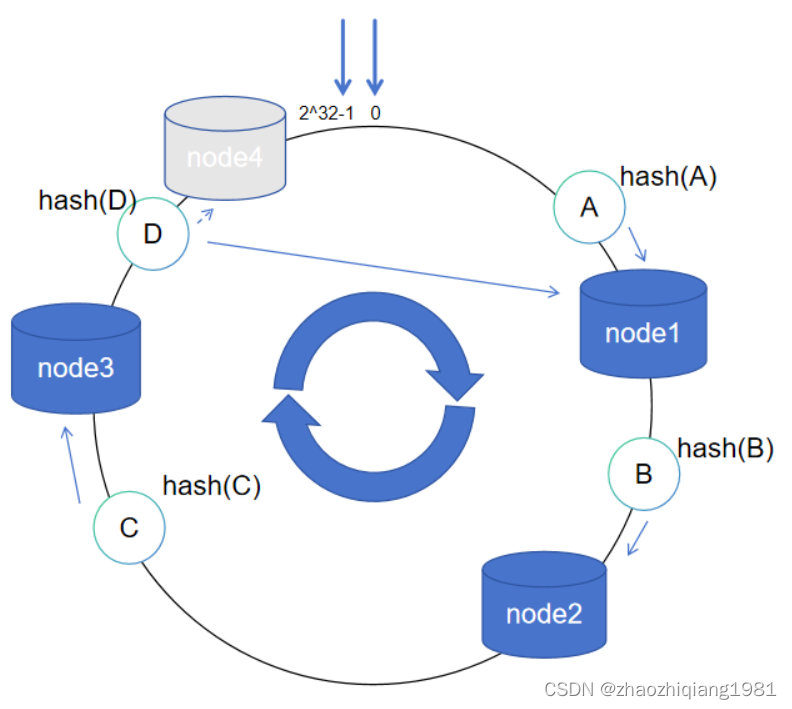
数据倾斜与虚拟节点
数据abcd都落在node1中,node2,node3没事干,node1压力山大。
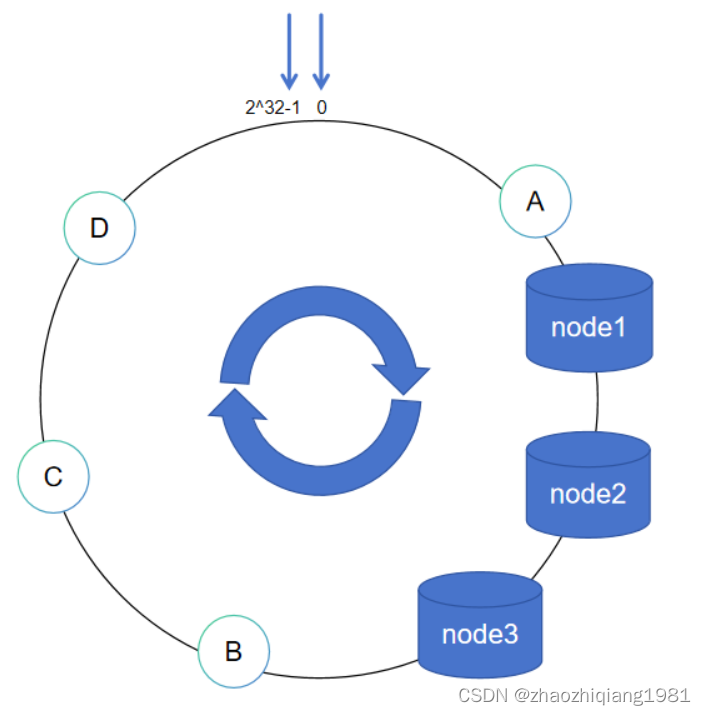
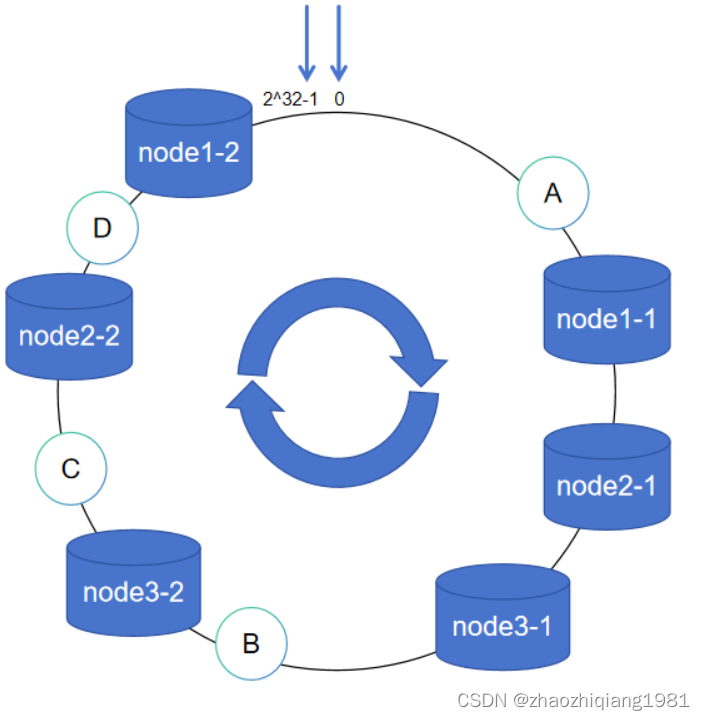
解决方案,使用虚拟节点
hash(服务器ip)% 2^32 变更为 hash(服务器ip+随机数)% 2^32
例如:Hash(“114.211.11.141”);
变更为:
Hash(“114.211.11.141#1”);
Hash(“114.211.11.141#2”);
注意,虚拟节点只是帮助真实节点扩大获取数据的范围,并不会保存数据,所获取的数据最终还是要存储在真实节点中。
memcached的问题
传统的memcached是不支持内存数据的持久化操作,因为它将数据存储在内存当中的,当服务器宕机重启,数据会丢失。
不适合存储1M以上的数据。
适用场景:缓存一些很小但是被频繁访问的,即便你丢失也不会影响系统以及系统业务正常执行的数据。如:新闻热点缓存,即便日后数据丢失,热点已经降温,数据不重要。
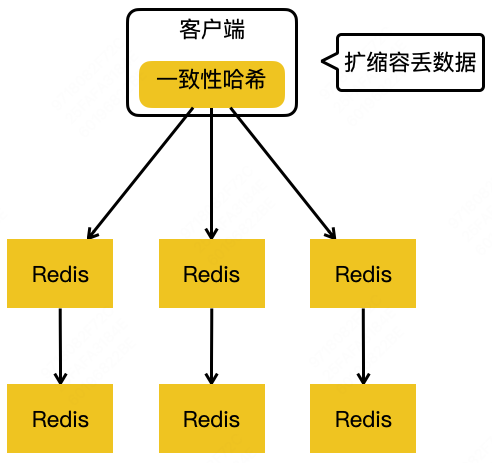
第二代:使用Redis
优点:支持持久化,服务宕机后数据不会丢失,可以通过哨兵机制进行故障恢复(failover)
宕机数据不丢失策略:
RDB每5分钟一次生成快照,AOF每秒通过一个后台的线程持久化操作,最多丢一秒的数据。单独用RDB会丢失很多数据,单独用AOF数据恢复没RDB快,所以解决方案是第一时间用RDB恢复,然后AOF做数据补全
缺点:扩缩容丢失数据。
一致性hash只是用来减少扩缩容时数据迁移量,无法对整个集群进行统一管理(缺乏类似提供心跳检测等服务的中心管理层,数据迁徙的时候,节点无法感知整个集群的状态,数据从A节点中迁徙出去了,但接收的B节点处于网络卡顿状态导致无法接受全部迁徙数据等问题)
第三代:阿里巴巴的 Tair
Tair 开源版本的架构主要是三部分:最下边的是存储节点,存储节点会上报心跳到它的中心节点,中心节点内部设有两个配置管理节点,会监控所有的存储节点。如果有任何存储节点宕机或者扩容之类的行为,它会做集群拓扑的重新构建,拥有数据迁移机制来保证数据的完整性。
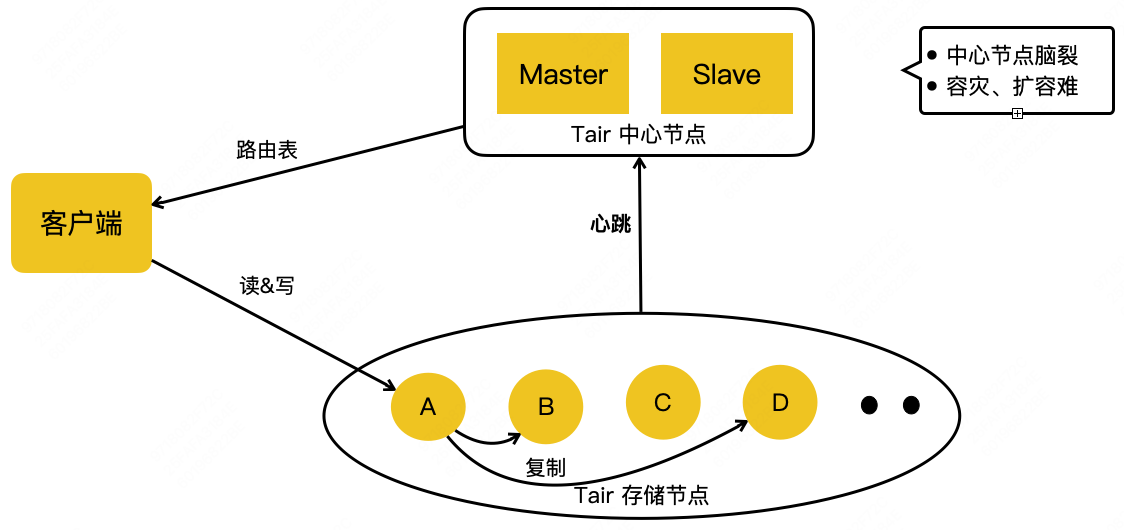
缺点:
1.中心节点是高可用的,但是会发生脑裂。
脑裂:选举bug,多个leader,多个从节点被选举成了主节点,不干从节点的活了导致数据丢失。
2.和redis的数据类型不兼容
第四代:
基于Tair的Cellar ,基于Redis Cluster的Squirrel
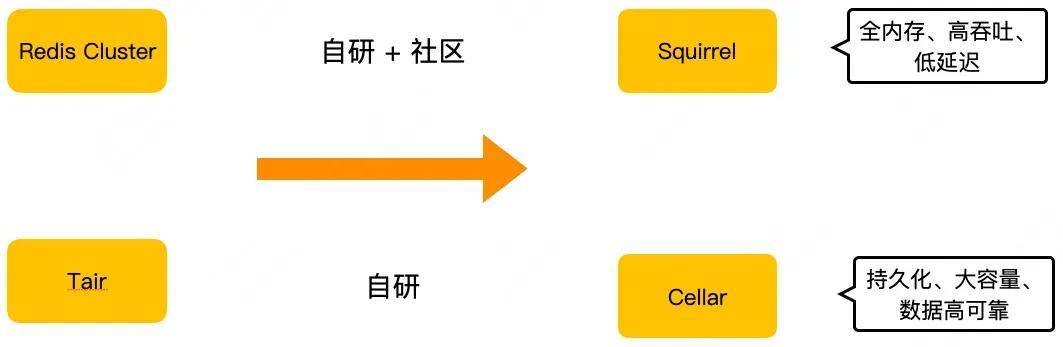
这两个存储其实都是 KV 存储领域的解决方案。实际应用上,如果业务的数据量小,对延迟敏感,建议用 Squirrel ;如果数据量大,对延迟不是特别敏感,我们建议用成本更低的 Cellar 。
2 大规模 KV 存储的挑战
1.集群的规模越来越大,节点增加困难(比如带宽饱和)
2.部分业务场景带来的木桶效应以及长尾延迟(例如:mget)
3.如何保证集群可用性不会随着规模的变大而有所降低
名词解释:
mget:
可以一次性读取redis中多个值:
redis 127.0.0.1:6379> SET key1 "hello"
OK
redis 127.0.0.1:6379> SET key2 "world"
OK
redis 127.0.0.1:6379> MGET key1 key2 someOtherKey
1) "Hello"
2) "World"
3) (nil)
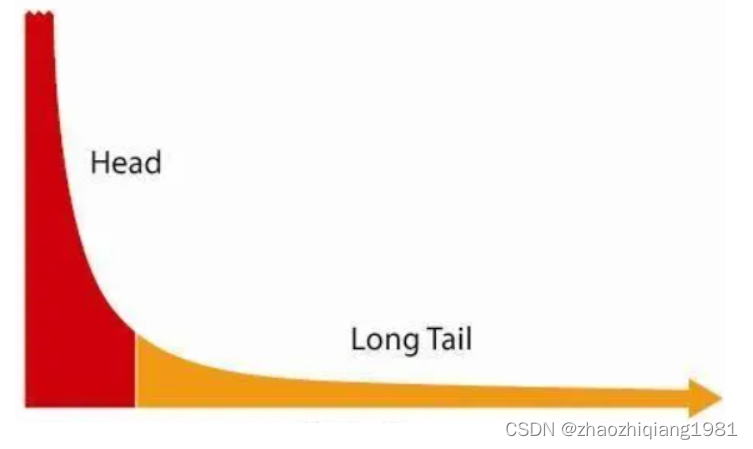
长尾效应:
红色区域量大响应时间短,黄色区域量小耗时长。比如使用了上面的mget批量读取就有大概率造成此类问题。
3 内存 KV Squirrel 挑战和架构实践
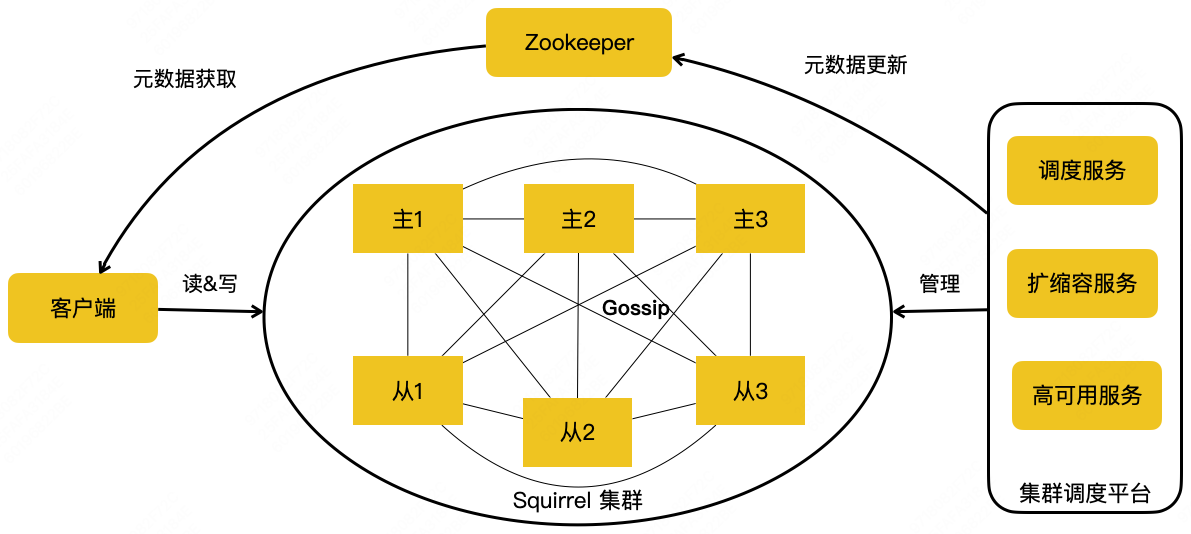
上图是美团的 Squirrel 架构。中间部分跟 Redis 社区集群是一致的。它有主从的结构,Redis 实例之间通过 Gossip 协议去通信。右边添加了一个集群调度平台管理整个集群,把管理结果作为元数据更新到 ZooKeeper。我们的客户端会订阅 ZooKeeper 上的元数据变更,实时获取到集群的拓扑状态,直接对 Redis 集群节点进行读写操作。
难点补充:
Gossip 原理:
节点1更新数据,告知了相邻节点2,4,7;相邻节点再去告诉自己的相邻节点。
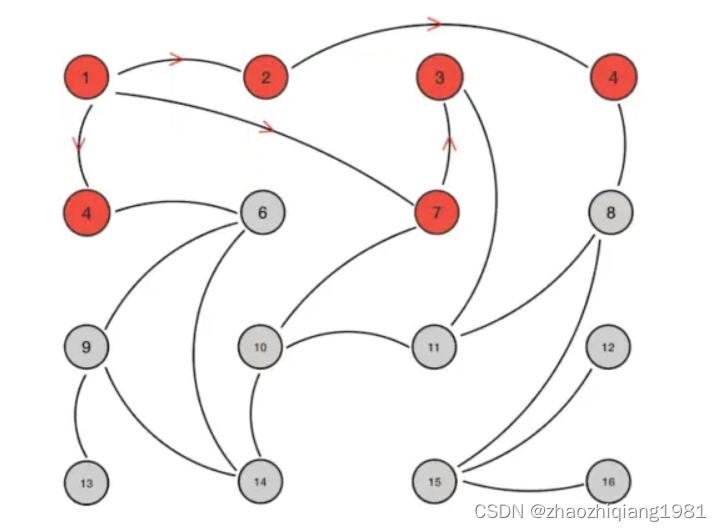
优点:去中心化(多个缓存中间件采用,区块链采用)
缺点:当节点特别多的时候消耗性能,节点更新后相邻节点可能会重复更新,非常损耗性能。
3.2 Gossip优化
为了解决上述的扩展性问题,我们对社区的 Gossip 方案进行了优化。首先针对 Gossip 传输的消息,我们通过 Merkle Tree 对其做了一个摘要,把集群 Gossip 通信的数据量减少了90%以上。服务端节点仅需要对比 Hash 值即可判断元数据是否有更新,对于存在更新的情况也能快速判断出更新的部分,并仅对此部分元数据进行获取、更新,大幅降低了 Gossip 消息处理的资源消耗。
原文中的默克尔树(Merkle Tree)
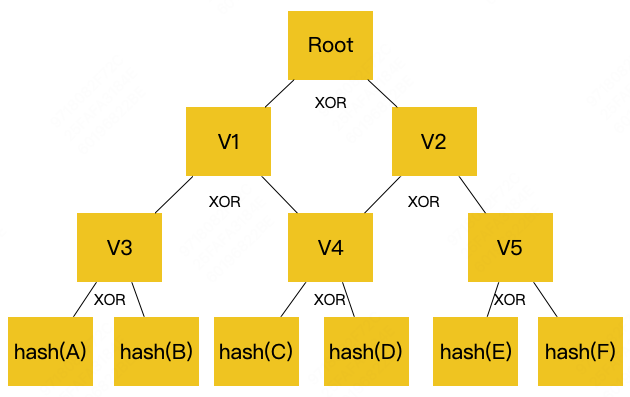
补全图:
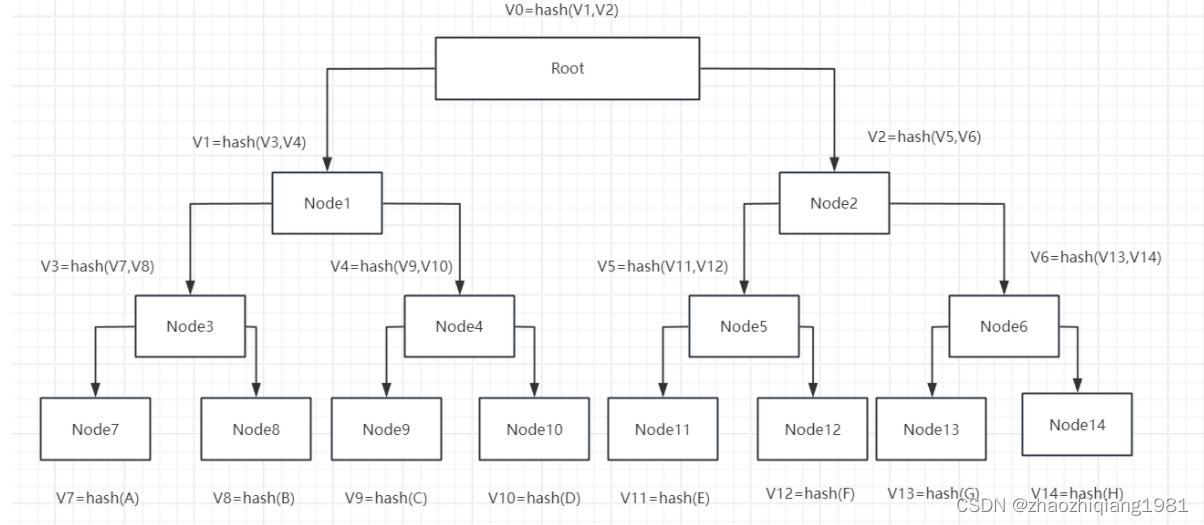
类似平衡二叉树,通过对比上层节点的hash是否一致即可得知是否已经更新,可双向判断:判断更新以及找到更新位置。难度:之前为O(N)现在为O Log(N)
3.3 Squirrel 垂直扩展的挑战
节点过大,Fork生成RDB影响性能。(执行RDB的主要三种场景:save,bgsave,主从复制)
Redis备份数据做持久化操作有AOF和RDB两种,为了不影响主线程,会通过内置的Fork系统启动一个子线程执行,但Fork子进程过程中如果节点过大,依然会占用大量资源导致阻塞。可以简单理解为,Redis会在数据增长到一定程度或者执行主从复制的时候,备份自己的数据,生成一个RDB文件(快照),保存当时Redis中的所有数据用于以后的数据恢复,但这个RDB文件尽管通过子线程生成,但每次生成一个大文件在保存还是耗费资源。
3.4 forkless RDB
解决方案就是采用复制队列的方式,由原来的一次拷贝一个大的(越大越慢,会造成阻塞),改成一个key一个key的往队列拷贝生成的方式。
拷贝期间数据变化怎么办:把变化过程也拷贝到队列里。
拷贝期间发生rehash导致里面的key顺序重排怎么办:暂停rehash.
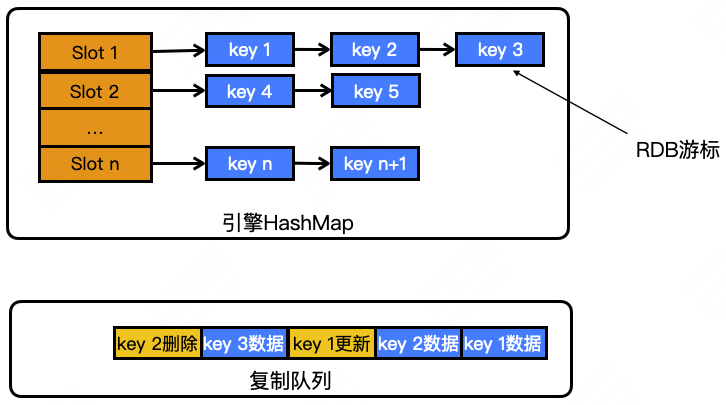
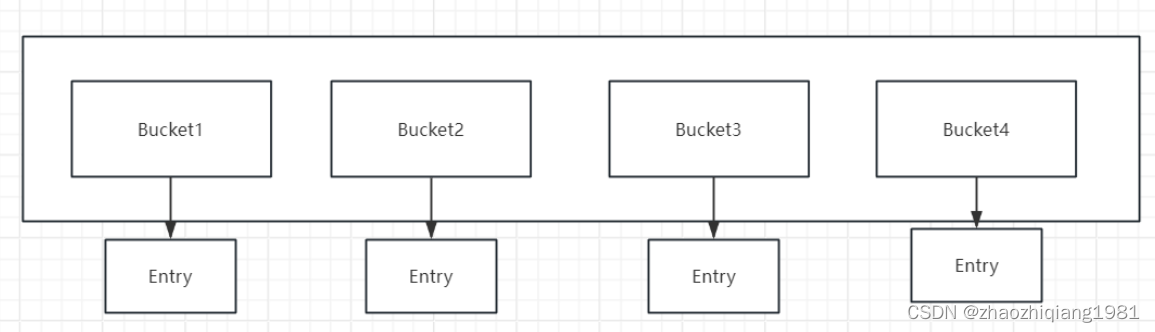
这里的rehash 又是什么意思呢?
redis中有一个全局Hash表(HashTable),表里有一个一个的哈希桶(Bucket),桶里装着Entry(存放key,value的指针),数据量特别大的时候会发生Hash冲突行成链表,如下图的Bucket2.

解决方案:rehash,扩容。
创建一个比原来还大的HashTable,向其中传递原来HashTable的数据,并对存在Hash冲突的地方进行哈希桶的重新分配。
这就是为什么美团的forkless RDB执行的时候需要停止rehash了,因为要一个一个的拷贝key,并且有游标指向key的位置,但rehash发生后,key的位置就会发生变化。
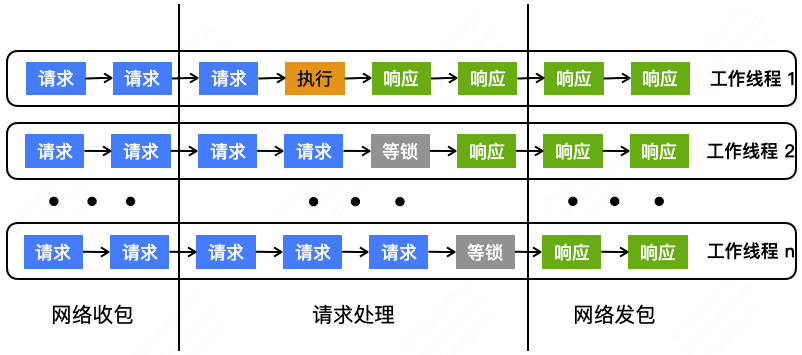
3.5 工作多线程
原生Redis:IO多线程,工作线程为单线程。
修改为:IO多线程,工作线程也是多线程,通过加锁解决线程安全问题。
3.6 Squirrel可用性的挑战
只有两个机房,A选B,B选A,选不出主或者造成脑裂,必须部署3机房,但通常两个副本足够用了,没必要部署3个副本。
3.7 两机房容灾
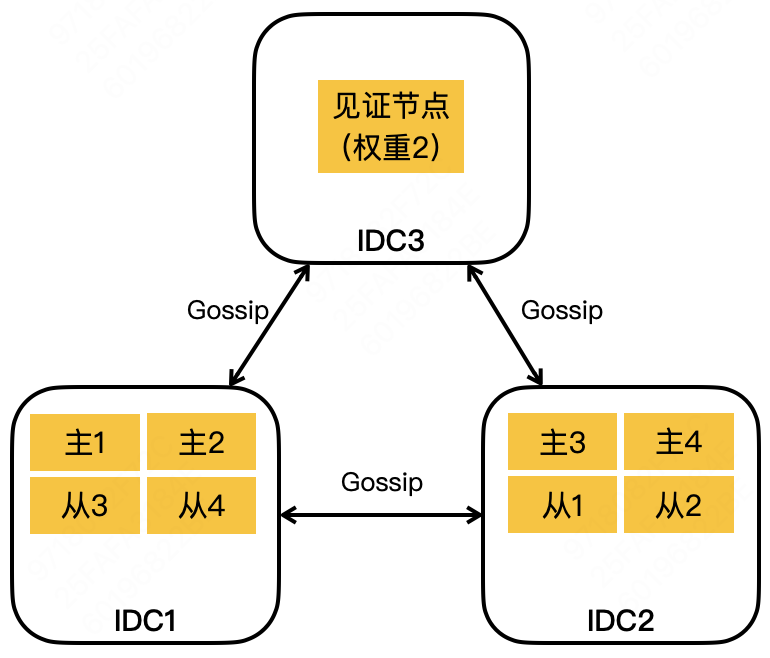
参考 Google Spanner(可伸缩分布式数据库)的见证者投票方式。
简单说就是:
还是三个机房,但保存两个副本就行了,另外一个只投票,不保存副本。
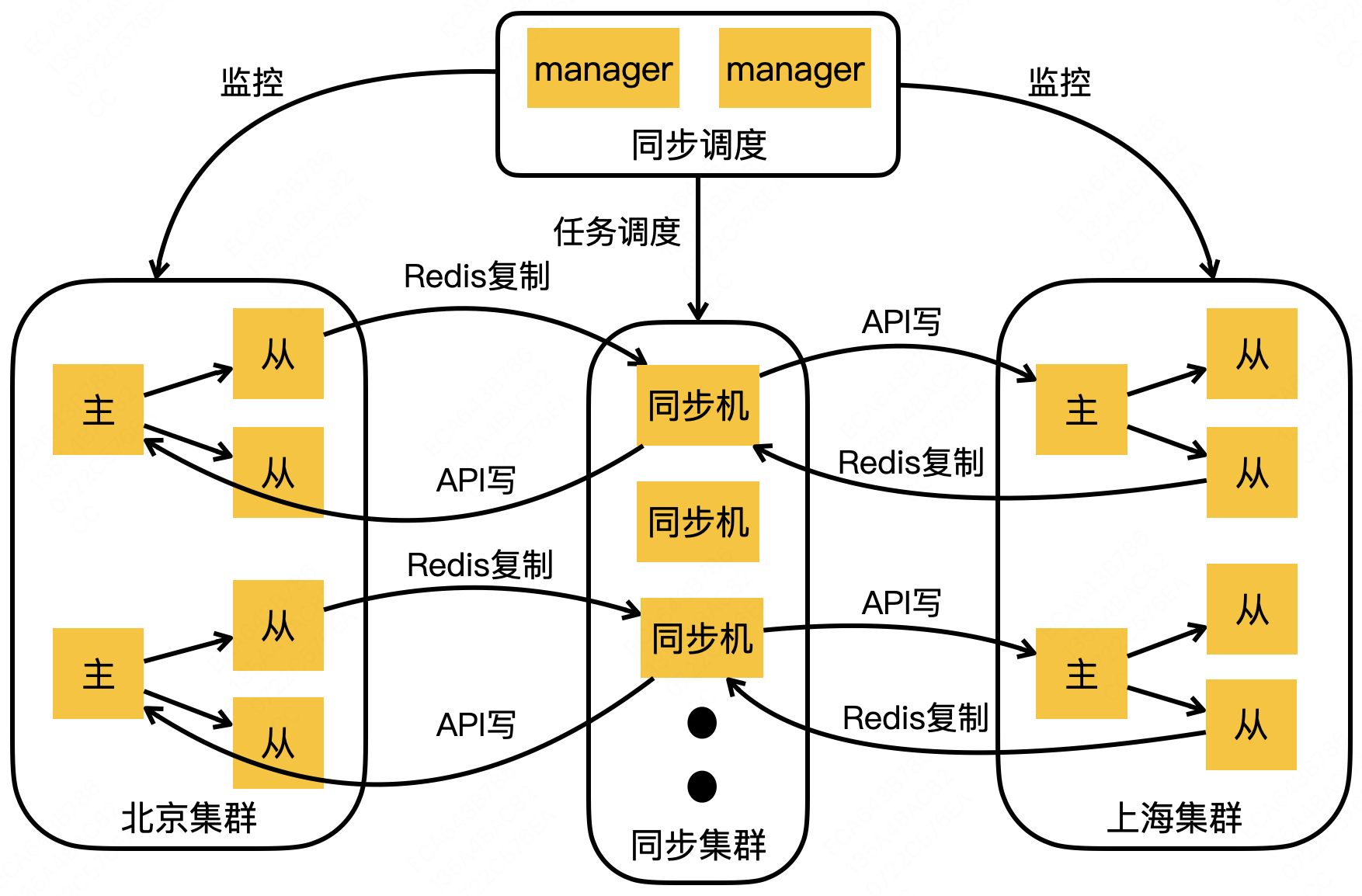
3.8 跨地域容灾
3.9 双向同步冲突自动解决
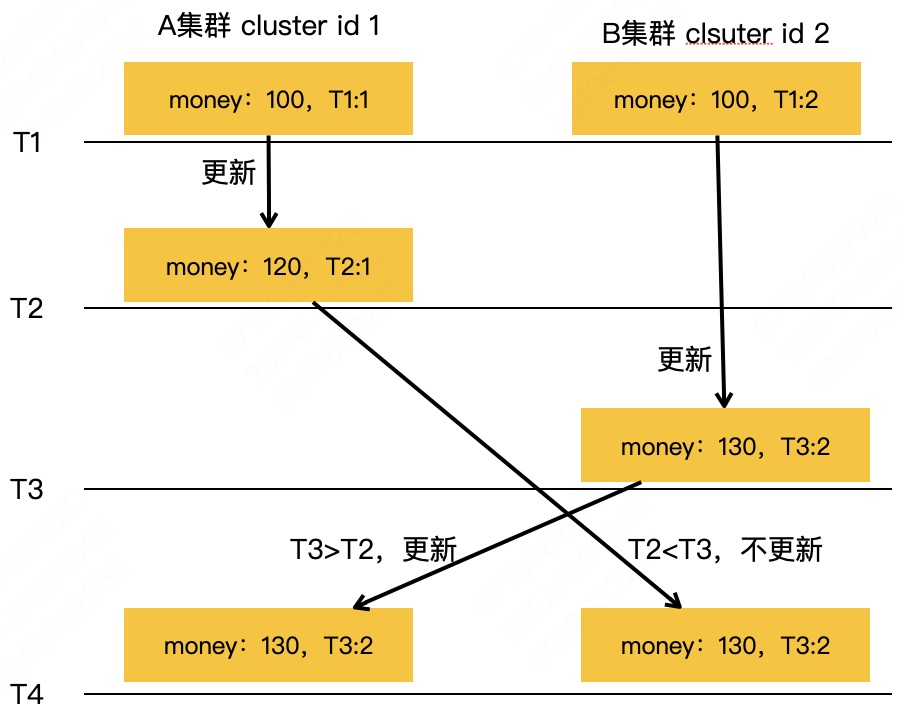
简单说就是谁的时间新就保存谁的。
服务器发生了时间回退怎么办:保存数据时使用时间戳,发生回退了依然使用时间戳来防止数据跟着回退。
两个值的更新时间一样怎么办:比较集群ID,保存集群ID大的那一个。(个人理解类似足球比赛积分净胜球等都相同,靠抽签决定谁进入下一轮)
由复制操作改为复制变更后的数据:只考虑操作后的数据,而不是复制操作。
链图片转存中…(img-qMRzytbP-1717929022879)]
3.9 双向同步冲突自动解决
[外链图片转存中…(img-CDljEhDy-1717929022880)]
简单说就是谁的时间新就保存谁的。
服务器发生了时间回退怎么办:保存数据时使用时间戳,发生回退了依然使用时间戳来防止数据跟着回退。
两个值的更新时间一样怎么办:比较集群ID,保存集群ID大的那一个。(个人理解类似足球比赛积分净胜球等都相同,靠抽签决定谁进入下一轮)
由复制操作改为复制变更后的数据:只考虑操作后的数据,而不是复制操作。
保存最近删除的 Key:简单说就是B集群同步复制A集群数据的时候,对于复制过来一个已经不存在的数据,先不要创建,而是到删除库中看一看这个数据是不是已经被删除了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









