






本文是我从别的文章中组合而成的,结合自己实际操作进行了修改。
Solr是什么
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据xml文档添加、删除、更新索引 。Solr搜索只需要发送HTTP GET请求,然后对Solr返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
Lucene是什么
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
为什么使用Solr
企业站内搜索技术选型
在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
单独使用Lucene实现
单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
使用Google或Baidu接口
通过第三方搜索引擎提供的接口实现站内搜索,这样和第三方引擎系统依赖紧密,不方便扩展,不建议采用。
使用Solr实现
基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
solr6.2入门
下载
从Solr官方网站(http://lucene.apache.org/solr/ )下载Solr6.2.0,根据Solr的运行环境,Linux下需要下载lucene-6.2.0.tgz,windows下需要下载lucene-6.2.0.zip。(使用Maven配置solr文件时,lucene是自动下载)
Solr下载地址:http://archive.apache.org/dist/lucene/solr/6.2.0/
部署需要的环境
JDK8 下载jdk1.8:jdk1.8【solr6.0是基于jdk8开发的】
tomcat8.0 下载:tomcat8
工程部署
1.
将【solr-6.2.0\server\solr-webapp】下的webapp文件拷贝到【apache-tomcat-8.0.33\webapps】目录下,并将webapp重命名为solr(可以重命名为取任意名称)。
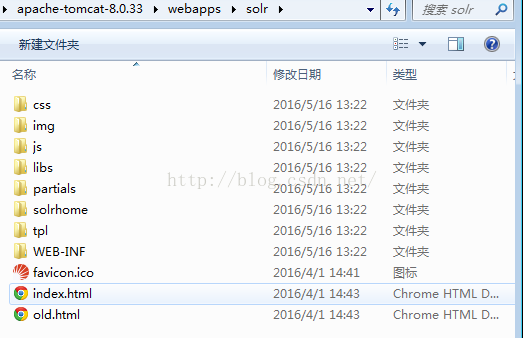
2、将【solr-6.0.0\server\lib\ext】下的所有jar包拷贝到【apache-tomcat-8.0.33\webapps\solr\WEB-INF\lib】
3、将【solr-6.0.0\server\resources】下的log4j.properties配置文件拷贝到【apache-tomcat-8.0.33\webapps\solr\WEB-INF\classes】,如果WEB-INF下没有classes文件那么 就创建一个classes文件夹。
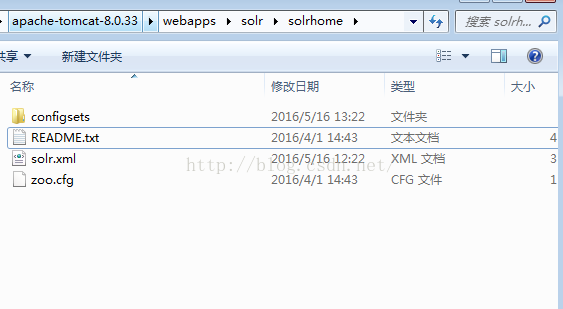
4、在【apache-tomcat-8.0.33\webapps\solr】下新建一个文件【solrhome(文件夹名称可以任意命名)】,将【solr-6.0.0\server\solr】下的所有文件拷贝到刚刚创建
的solrhome中。
文件中包含如下:
5、修改【apache-tomcat-8.0.33\webapps\solr\WEB-INF】下的web.xml,找到如下代码:
- <env-entry>
- <env-entry-name>solr/home</env-entry-name>
- <env-entry-value>/put/your/solr/home/here</env-entry-value>
- <env-entry-type>java.lang.String</env-entry-type>
- </env-entry>
默认是注解掉,放开注解,并将<env-entry-value>中的值修改为刚刚步骤7中的solrhome目录,如:E:\project\Search\apache-tomcat-8.0.33\webapps\solr\solrhome
6、运行tomcat,运行成功后访问:http://localhost:8080/solr/index.html 即可得到如下界面:
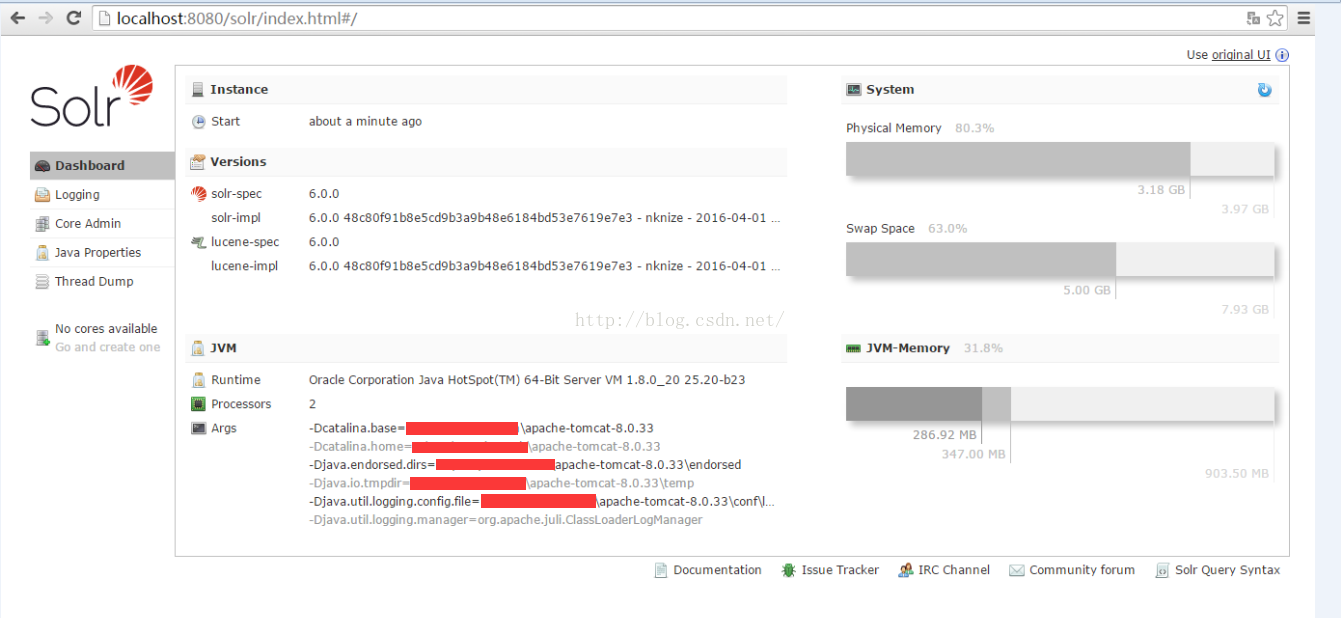
那么整个solr的环境搭建已经成功。
solr安装成功后,我们要建立新的core,下载的6.2不能直接创建。最后经过我的努力终于成功了
1、需要我们手动在solrhome 目录下面创建 new_core文件夹
2、直接创建会报错找不到solr.xml,solrconfig.xml
Error CREATEing SolrCore 'new_core': Unable to create core [new_core] Caused by: Can't find resource 'solrconfig.xml' in classpath or 'F:\tomcat8_extend\webapps\solr\solrhome\new_core'
Error CREATEing SolrCore 'new_core': Unable to create core [new_core] Caused by: Can't find resource 'solr.xml' in classpath or 'F:\tomcat8_extend\webapps\solr\solrhome\new_core'
解决办法将 这两个文件拷贝到 F:\tomcat8_extend\webapps\solr\solrhome下
solrconfig.xml文件从 F:\tomcat8_extend\webapps\solr\solrhome\configsets\basic_configs\conf 下找到的。
solr.xml 文件从 E:\solr\server 下找到的
3、这时候再创建报上面一样的错误,不过这时候是找不到schema.xml文件
在之前的Solr版本中(Solr5之前),在创建core的时候,Solr会自动创建好schema.xml,但是在之后的版本中,新加入了动态更新schema功能,这个 默认的schema.xml确找不到了.
原来,在Solr5以后,这个schema文件已经不是默认生成好的了,它被取了一个名字managed-schema,并且没有后缀。乍一看,以为是打不开的文件,当 然没有什么能难倒程序员的,用EditPlus++打开,发现了熟悉的文字,这不就是之前的schema.xml文件吗? (文件路径:E:\solr\example\example-DIH\solr\db\conf )

文档中还明确说明了,这个文档应该根据实际情况放到合适的位置,并把文件命名为schema.xml.这次我们就直接把文件名改成schema.xml就可以了,位置就是new_core下面
4 这次是 lang/contractions_it.txt 找不到
Error CREATEing SolrCore 'new_core': Unable to create core [new_core] Caused by: Can't find resource 'lang/contractions_it.txt' in classpath or 'F:\tomcat8_extend\webapps\solr\solrhome\new_core'
lang 文件夹 在 F:\tomcat8_extend\webapps\solr\solrhome\configsets\basic_configs\conf。我将整个conf 文件夹拷贝到了new_core下面
5、创建成功
目录结构
example\solr是一个solr home目录结构,如下:
.10.3.zip并解压:
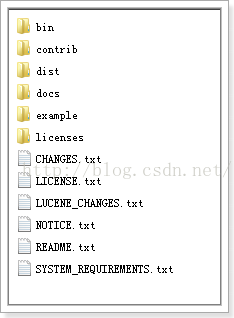
bin:solr的运行脚本
contrib:Solr的一些扩展包,包括分词器,聚类,语言识别,数据导入处理,非结构化内容分
析等.
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。我们之
前使用的solr.war实际上就是这个文件夹下的solr-4.40.war
docs:solr的API文档
example:solr工程的例子目录:
l example/solr:
该目录是一个包含了默认配置信息的Solr的Core目录。
l example/multicore:
该目录包含了在Solr的multicore中设置的多个Core目录。
l example/webapps:
该目录中包括一个solr.war,该war可作为solr的运行实例工程。
licenses:solr相关的一些许可信息
solr服务器使用
使用jetty运行solr服务器
Solr的example里面默认提供了start.jar文件,这个jar文件默认集成jetty web服务器,所以我们可以直接使用jetty服务器运行这个jar文件。
运行
进入solr-6.2.0\example
通过 java -jar 运行start.jar
注意:start.jar 集成jetty web服务器 !

访问
通过jetty服务器 默认访问端口8983访问服务
http://localhost:8983/solr
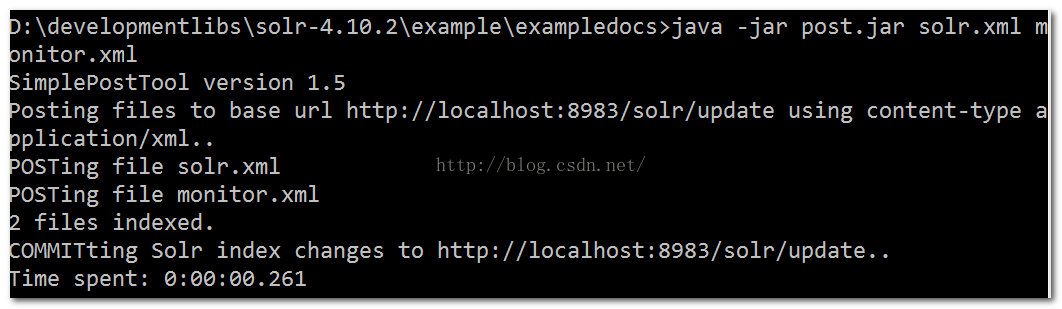
导入数据
通过example/ exampledocs/post.jar 工具包导入数据
进入:\solr\example\exampledocs shift+右键 选择在”此处打开命令窗口“
输入命令 java -jar post.jar solr.xml monitor.xml导入初始化数据(solr方便用户测试,自带的数据文件)
solr Admin控制台的使用
通过 coreAdmin 查看所有core(core就是索引库)
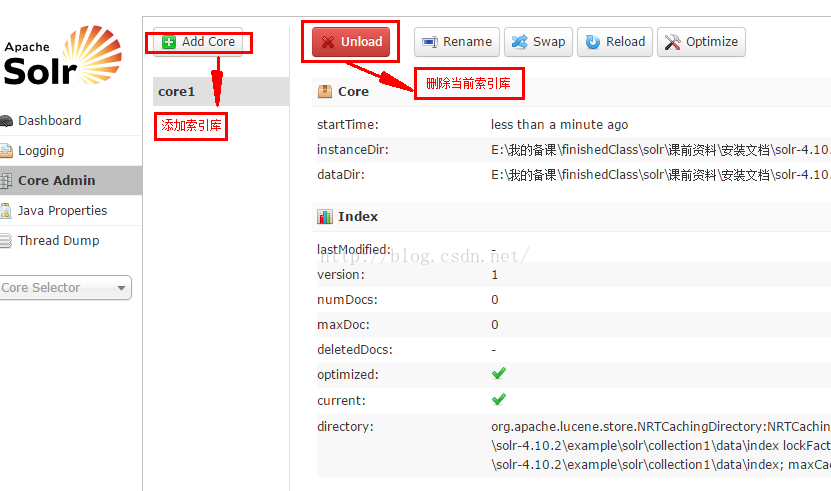

我们也可以自己创建一个collection2添加索引,也可以把collection1干掉,然后在导入collection1测试。下面是删除掉collection1,然后再导入。
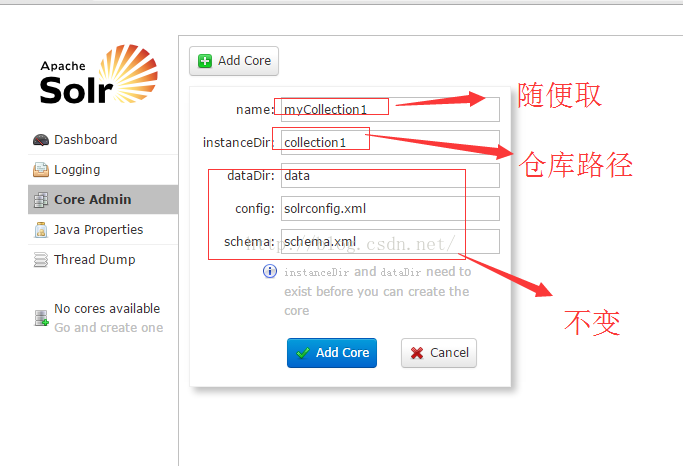
core操作菜单
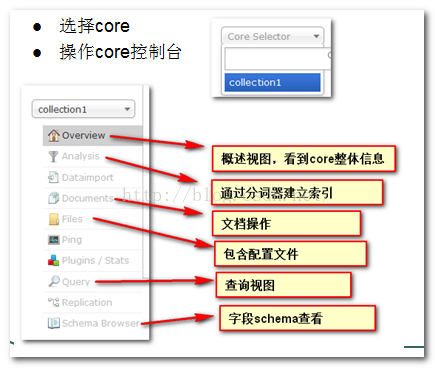
query
1、q:查询条件,*:*查询所有,title:lucene*查询title中以lucene开头的。

2、fq:在上面“q“的基础上进行过滤

3、按照名字倒叙显示,正序为asc

4、开始条数和结束条数
5、只查询id和name的field
6、df表示默认查询的字段
7、返回数据的格式
8、高亮显示
Solr和tomcat整合
Solr Home与SolrCore
创建一个Solr home目录,SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
目录结构
example\solr是一个solr home目录结构,如下:
上图中“collection1”是一个SolrCore(Solr实例)目录 ,目录内容如下所示:
说明:
collection1:叫做一个Solr运行实例SolrCore,SolrCore名称不固定,一个solr运行实例对外单独提供索引和搜索接口。
solrHome中可以创建多个solr运行实例SolrCore。
一个solr的运行实例对应一个索引目录。
conf是SolrCore的配置文件目录 。
data目录存放索引文件需要创建
Tomcat的三种配置方式
solr/home是solr实例化core核的依据和入口,是必不可少的配置。
在tomcat中有三种方式可以完成其配置。
在web.xml中设置
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>C:/example2/solr(path_to_solr_home_solr)</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
此中方式在部署时,不方便,需打包前给据部署环境修改。
上面这种配置方式就是这一中配置方式。
通过tomcat的JNDI方式设置变量
在你安装tomcat的根目录下,找到或者新建路径:conf\Catalina\localhost;
根据你部署的项目名称,新建一个XML文件,如果包名叫solr,就叫solr.xml。
内容为:
<Context docBase="E:/apache-tomcat6_1/webapps/solr(the_path_to solr.war)" debug="0" crossContext="true" >
<Environment name="solr/home" type="java.lang.String" value="C:/example2/solr(the_path_to_solr_home)" override="true" />
</Context>
第
启动Tomcat
访问http://localhost:8080/solr/index.html
管理界面
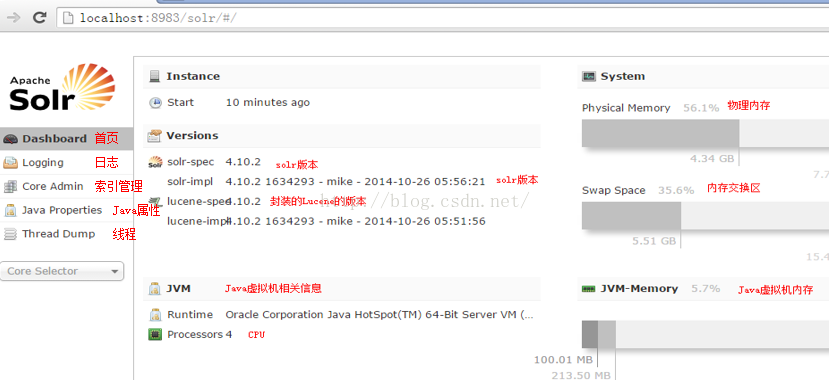
Dashboard:
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
Logging:
Solr运行日志信息
Cloud:
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单,如下图是Solr Cloud的管理界面:
Core Admin:
Solr Core的管理界面。Solr Core是Solr的一个独立运行实例单位,它可以对外提供索引和搜索服务,一个Solr工程可以运行多个SolrCore(Solr实例),一个Core对应一个索引目录。
java properties
Solr在JVM运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
Core selector
选择一个SolrCore进行详细操作,如下:
Analysis(重点)
通过此界面可以测试索引分析器和搜索分析器的执行情况。
dataimport
可以定义数据导入处理器,从关系数据库将数据导入 到Solr索引库中。
Document(重点)
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
query(重点)
通过/select执行搜索索引,必须指定“q”查询条件方可搜索。
多core配置
配置多core的好处:
1、将索引数据分core存储方便管理。
2、solrCloud集群需要使用多core。
复制原来的core目录为collection2,目录结构如下:
修改collection2下的core.properties,如下:
演示多core的使用,在collection1和collection2中分别创建索引、搜索索引。
Solr索引
solrConfig.xml
System property替换
Solr 支持系统属性替换,允许启动JVM在任一Solr的配置文件指定字符串替换。
语法: ${property[:default value]}
替换是有效的在任何元素或属性的文本。
这里是允许运行时决定数据目录的一个例子:
<dataDir>${solr.data.dir:./solr/data}</dataDir> 使用示例应用程序中
solr可以以这种方式启动:
java -Dsolr.data.dir=/data/dir -jar start.jar 如果没有指定
solr启动时读取 conf/solrcore.properties文件
#solrcore.properties data.dir=/data/solrindex
解析:运行时替换目录意思
注意:在solrConfig配置文件里面使用${},这是solr语法格式。
简单解释一下:
Solr.就代表solrcore索引库目录:collection1这一层目录。
顾名思义:solr.data.dir表示的意思就是collection1下面的data目录。
这是solr的一种约定,不必深究,知道solr.就是我们的索引库目录就ok。
luceneMatchVersion 使用lucene版本
其它配置
df:当使用客户端api进行查询时,默认查询的字段在df里设置
scheam.xml
schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
FieldType域类型定义
下边“text_general”是Solr默认提供的FieldType,通过它说明FieldType定义的内容:
FieldType子结点包括:name,class,positionIncrementGap等一些参数:
name:是这个FieldType的名称
class:是Solr提供的包solr.TextField,solr.TextField允许用户通过分析器来定制索引和查询,分析器包括一个分词器(tokenizer)和多个过滤器(filter)
positionIncrementGap:可选属性,定义在同一个文档中此类型数据的空白间隔,避免短语匹配错误,此值相当于Lucene的短语查询设置slop值,根据经验设置为100。
在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤
索引分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,solr.LowerCaseFilterFactory小写过滤器。
搜索分析器中:使用solr.StandardTokenizerFactory标准分词器,solr.StopFilterFactory停用词过滤器,这里还用到了solr.SynonymFilterFactory同义词过滤器。
Field定义
在fields结点内定义具体的Field,filed定义包括name,type(为之前定义过的各种FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否存储多个值)等属性。
如下:
<field name="name" type="text_general" indexed="true" stored="true"/>
<field name="features" type="text_general" indexed="true" stored="true" multiValued="true"/>
multiValued:该Field如果要存储多个值时设置为true,solr允许一个Field存储多个值,比如存储一个用户的好友id(多个),商品的图片(多个,大图和小图),通过使用solr查询要看出返回给客户端是数组:
<fields>
<!-- fields各
Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束。
copyField复制域
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:
比如,输入关键字搜索title标题内容content,
定义title、content、text的域:
个属性说明:name:必须属性-字段名
type:必须属性- <types>中定义的字段类型
indexed:如果字段需要被索引(用于搜索或排序),属性值设置为true
stored:如果字段内容需要被返回,值设置为true
docValues:如果这个字段应该有文档值(doc values),设置为true。文档值在门
面搜索,分组,排序和函数查询中会非常有用。虽然不是必须的,而且会导致生成
索引变大变慢,但这样设置会使索引加载更快,更加NRT友好,更高的内存使用效率。
然而也有一些使用限制:目前仅支持StrField, UUIDField和所有Trie*Fields,
并且依赖字段类型,可能要求字段为单值(single-valued)的,必须的或者有默认值。
multiValued:如果这个字段在每个文档中可能包含多个值,设置为true
termVectors: [false]设置为true后,会保存所给字段的相关向量(vector)
当使用MoreLikeThis时,用于相似度判断的字段需要设置为stored来达到最佳性能.
termPositions:保存和向量相关的位置信息,会增加存储开销
termOffsets:保存offset和向量相关的信息,会增加存储开销
required:字段必须有值,否则会抛异常
default:在增加文档时,可以根据需要为字段设置一个默认值,防止为空
uniqueKey
Solr中默认定义唯一主键key为id域,如下:
Solr在删除、更新索引时使用id域进行判断,也可以自定义唯一主键。
注意在创建索引时必须指定唯一约束。
copyField复制域
copyField复制域,可以将多个Field复制到一个Field中,以便进行统一的检索:
比如,输入关键字搜索title标题内容content,
定义title、content、text的域:
根据关键字只搜索text域的内容就相当于搜索title和content,将title和content复制到text中,如下:
例如:
<!--拷贝字段-->
< field name = "all" type = "text" indexed = "true" stored = "false" multiValued = "true"/>
</ fields >
建议建立一个拷贝字段,将所有的 全文本 字段复制到一个字段中,以便进行统一的检索:
以下是拷贝设置:
< copyField source = "name" dest = "all" />
< copyField source = "summary" dest = "all" />
dynamicField(动态字段)
动态字段就是不用指定具体的名称,只要定义字段名称的规则,例如定义一个 dynamicField,name为*_i,定义它的type为text,那么在使用这个字段的时候,任何以_i结尾的字段都被认为是符合这个定义的,例如:name_i,gender_i,school_i等。
自定义Field名为:product_title_t,“product_title_t”和scheam.xml中的dynamicField规则匹配成功,如下:
“product_title_t”是以“_t”结尾。
创建索引:
搜索索引:
Analyzer
安装中文分词器
IKAnalyzer部署
拷贝IKAnalyzer的文件到Tomcat下Solr目录 中
将IKAnalyzer2012FF_u1.jar拷贝到Tomcat的webapps/solr/WEB-INF/lib下。
在Tomcat的webapps/solr/WEB-INF/下创建classes目录
将IKAnalyzer.cfg.xml、ext_stopword.dic mydict.dic copy到Tomcat的
webapps/solr/WEB-INF/classes
注意:ext_stopword.dic 和mydict.dic必须保存成无BOM的utf-8类型。
修改schema.xml文件
FieldType
首先需要在types结点内定义一个FieldType子结点,包括name,class,等参数,name就是这个FieldType的名称,class指向org.apache.solr.analysis包里面对应的class名称,用来定义这个类型的行为。在FieldType定义的时候最重要的就是定义这个类型的数据在建立索引和进行查询的时候要使用的分析器analyzer,包括分词和过滤
修改Solr的schema.xml文件,添加FieldType:
<!-- IKAnalyzer-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
Field:
FieldType定义好后就可以在fields结点内定义具体的field,filed定义包括name,type(即FieldType),indexed(是否被索引),stored(是否被储存),multiValued(是否有多个值)等
<!--IKAnalyzer Field-->
<field name="title_ik" type="text_ik" indexed="true" stored="true" />
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
测试
设置业务系统Field
如果不使用Solr提供的Field可以针对具体的业务需要自定义一套Field,如下是商品信息Field:
<!--product-->
<field name="product_name" type="text_ik" indexed="true" stored="true"/>
<field name="product_price" type="float" indexed="true" stored="true"/>
<field name="product_description" type="text_ik" indexed="true" stored="false" />
<field name="product_picture" type="string" indexed="false" stored="true" />
<field name="product_catalog_name" type="string" indexed="true" stored="true" />
<field name="product_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>
索引维护
使用/update进行索引维护,进入Solr管理界面SolrCore下的Document下:
overwrite="true" : solr在做索引的时候,如果文档已经存在,就用xml中的文档进行替换
commitWithin="10000" : solr在做索引的时候,每个10000(10秒)毫秒,做一次文档提交。
为了方便测试也可以在Document中立即提交,在</add>后边添加“<commit/>”,如下:
<add>
<doc>
<field name="id">change.me</field>
<field name="title">change.me</field>
</doc>
</add>
<commit/>
添加/更新索引
solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
请求xml格式如下:
<add>
<doc>
<field name="id">change.me</field>
<field name="??" >??</field>
。。。
</doc>
</add>
说明:唯一标识 Field必须有,这里使用Solr默认的id。
删除索引
删除索引格式如下:
1) 删除制定ID的索引
<delete>
<id>8</id>
。。。
</delete>
2) 删除查询到的索引数据
<delete>
<query>product_catalog_name:幽默杂货</query>
</delete>
3) 删除所有索引数据
<delete>
<query>*:*</query>
</delete>
dataimport-handler
安装dataimport-Handler从关系数据库将数据导入到索引库。
第一步:向SolrCore中加入jar包
在SolrCore目录中创建lib目录,将dataimportHandler和MySQL数据库驱动的jar拷贝至lib下:
dataimportHandler在solr安装目录的dist下:
在lib下的包会被自动加载。
第二步:修改solrconfig.xml,添加requestHandler:
<requestHandler name="/dataimport"
class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
第三步:编辑data-config.xml文件,存放在SolrCore的conf目录
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/lucene"
user="root"
password="mysql"/>
<document>
<entity name="product" query="SELECT pid,name,catalog_name,price,description,picture FROM products ">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
</entity>
</document>
</dataConfig>
说明:
<field column="pid" name="id"/>必须有一个id域,这里使用Solr默认的id域,域值是从关系数据库查询的pid列值。
下边以“product_”开头的Field都是在schema.xml中自定义的商品信息Field。
第四步:重启Tomcat,进入管理界面--》SolrCore--》dataimport下执行导入
可以看见:导入成功,一共导入3803个文档。
Solr搜索
requestHandler
<requestHandler name="/select" class="solr.SearchHandler">
<!-- 设置默认的参数值,可以在请求地址中修改这些参数-->
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int><!--显示数量-->
<str name="wt">json</str><!--显示格式-->
<str name="df">text</str><!--默认搜索字段-->
</lst>
</requestHandler>
查询语法
通过/select搜索索引,Solr制定一些参数完成不同需求的搜索:
1. q - 查询字符串,必须的,如果查询所有使用*:*。
2. fq - (filter query)过虑查询,作用:在q查询符合结果中同时是fq查询符合的,例如::
过滤查询价格从1到20的记录。
也可以在“q”查询条件中使用product_price:[1 TO 20],如下:
也可以使用“*”表示无限,例如:
20以上:product_price:[20 TO *]
20以下:product_price:[* TO 20]
3. sort - 排序,格式:sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]… 。示例:
4. start - 分页显示使用,开始记录下标,从0开始
5. rows - 指定返回结果最多有多少条记录,配合start来实现分页。
显示前10条。
6. fl - 指定返回那些字段内容,用逗号或空格分隔多个。
显示商品图片、商品名称、商品价格
7. df-指定一个搜索Field
也可以在SolrCore目录 中conf/solrconfig.xml文件中指定默认搜索Field,指定后就可以直接在“q”查询条件中输入关键字。
8. wt - (writer type)指定输出格式,可以有 xml, json, PHP, phps,后面solr 1.3增加的,要用通知我们,因为默认没有打开。
9. hl 是否高亮 ,设置高亮Field,设置格式前缀和后缀。
solrJ
solrj 客户端操作
solr的客户端代码和solr服务器之间的增删改查索引操作是通过类似WebService接口API,所以在操作时,只要遵循一定的接口规范即可。
客户端代码solrj
solrj是solr提供的java语言支持,可以使用客户端语言通过访问webservice接口,实现对solr服务器的增删改查。
准备环境
第一步: 导入solrj jar包 到项目
第二步: 运行solr服务器
SolrJ完成索引维护
什么是SolrJ
solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务
创建索引(2种方式)
使用SolrJ创建索引,通过调用SolrJ提供的API请求Solr服务
第一种方式:
Document通过SolrInputDocument进行构建。
说明:根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
第二种方式
对实体数据Bean 添加@Field注解,直接传递Bean
| package com.itcast.solr.bean; import org.apache.solr.client.solrj.beans.Field; public class Article { @Field private String id; @Field private String title; @Field private String content;
public String getId() { return id; }
public void setId(String id) { this.id = id; }
public String getTitle() { return title; }
public void setTitle(String title) { this.title = title; }
public String getContent() { return content; }
public void setContent(String content) { this.content = content; } } |
注意:下面的保存必须满足scama里面字段和javabean字段一致。
| @Test public void createIndex2() throws SolrServerException, IOException { HttpSolrServer solrServer = new HttpSolrServer("http://127.0.0.1:8080/solr/itcast1"); Article article = new Article(); article.setId("4"); article.setTitle("这是基于bean的方式建立"); article.setContent("这是使用bean建立的content"); solrServer.addBean(article); solrServer.commit(); } |
删除索引
根据ID进行删除
根据查询条件删除
上边介绍的删除方法,使用SolrJ也可以完成,代码如下:
、
修改索引
对存在的索引进行添加即可
| @Test public void createIndex2() throws SolrServerException, IOException { HttpSolrServer solrServer = new HttpSolrServer("http://192.168.0.250:8080/solr-6.2.0/itcast1"); Article article = new Article(); article.setId("2"); article.setTitle("这是基于bean的方式建立"); article.setContent("这是使用bean建立的content"); solrServer.addBean(article); solrServer.commit(); } |
SolrJ完成搜索
搜索索引
查询所有
条件查询
// 搜索
@Test
public void testSearch()throws SolrServerException {
SolrServer solr = new HttpSolrServer(urlString);
// 查询对象
SolrQuery query = new SolrQuery();
//设置查询条件,名称“q”是固定的且必须 的
//搜索product_keywords域,product_keywords是复制域包括product_name和product_description
query.set("q","product_keywords:java教程");
// 请求查询
QueryResponse response = solr.query(query);
// 查询结果
SolrDocumentList docs = response.getResults();
// 查询文档总数
System.out.println("查询文档总数" + docs.getNumFound());
for (SolrDocument doc : docs) {
//商品主键
String id = (String) doc.getFieldValue("id");
//商品名称
String product_name = (String) doc.getFieldValue("product_name");
//商品价格
Float product_price = (Float) doc.getFieldValue("product_price");
//商品图片
String product_picture = (String) doc.getFieldValue("product_picture");
//商品分类
String product_catalog_name = (String) doc.getFieldValue("product_catalog_name");
System.out.println("=============================");
System.out.println(id);
System.out.println(product_name);
System.out.println(product_price);
System.out.println(product_picture);
System.out.println(product_catalog_name);
}
}
组合查询
// 根据商品分类、价格范围、关键字查询,查询结果按照价格降序排序
@Test
public void testSearch2()throws SolrServerException {
SolrServer solr = new HttpSolrServer(urlString);
// 查询对象
SolrQuery query = new SolrQuery();
// 搜索product_keywords域,product_keywords是复制域包括product_name和product_description
// 设置商品分类、关键字查询
// query.set("q", "product_keywords:挂钩 AND product_catalog_name:幽默杂货");
query.setQuery("product_keywords:挂钩 AND product_catalog_name:幽默杂货");
// 设置价格范围
query.set("fq","product_price:[1 TO 20]");
// 查询结果按照价格降序排序
// query.set("sort", "product_pricedesc");
query.addSort("product_price", ORDER.desc);
// 请求查询
QueryResponse response = solr.query(query);
// 查询结果
SolrDocumentList docs = response.getResults();
// 查询文档总数
System.out.println("查询文档总数" + docs.getNumFound());
for (SolrDocument doc : docs) {
// 商品主键
String id = (String) doc.getFieldValue("id");
// 商品名称
String product_name = (String) doc.getFieldValue("product_name");
// 商品价格
Float product_price = (Float) doc.getFieldValue("product_price");
// 商品图片
String product_picture = (String) doc
.getFieldValue("product_picture");
// 商品分类
String product_catalog_name = (String) doc
.getFieldValue("product_catalog_name");
System.out.println("=============================");
System.out.println("id=" + id);
System.out.println("product_name=" + product_name);
System.out.println("product_price=" + product_price);
System.out.println("product_picture=" + product_picture);
System.out.println("product_catalog_name=" + product_catalog_name);
}
}
分页、高亮
通过SolrQuery 设置高亮相关方法就可以了
// 分页和高亮
@Test
public void testSearch3()throws SolrServerException {
SolrServer solr = new HttpSolrServer(urlString);
// 查询对象
SolrQuery query = new SolrQuery();
// 设置商品分类、关键字查询
query.setQuery("product_keywords:透明挂钩");
// 分页参数
// 每页显示记录数
int pageSize = 2;
// 当前页码
int curPage = 2;
// 开始记录下标
int begin = pageSize * (curPage - 1);
// 起始下标
query.setStart(begin);
// 结束下标
query.setRows(pageSize);
// 设置高亮参数
query.setHighlight(true);//开启高亮组件
query.addHighlightField("product_name");//高亮字段
query.setHighlightSimplePre("<span color='red'>");//前缀标记
query.setHighlightSimplePost("</span>");//后缀标记
// 请求查询
QueryResponse response = solr.query(query);
// 查询结果
SolrDocumentList docs = response.getResults();
// 查询文档总数
System.out.println("查询文档总数" + docs.getNumFound());
for (SolrDocument doc : docs) {
// 商品主键
String id = (String) doc.getFieldValue("id");
// 商品名称
String product_name = (String) doc.getFieldValue("product_name");
// 商品价格
Float product_price = (Float) doc.getFieldValue("product_price");
// 商品图片
String product_picture = (String) doc
.getFieldValue("product_picture");
// 商品分类
String product_catalog_name = (String) doc
.getFieldValue("product_catalog_name");
System.out.println("=============================");
System.out.println("id=" + id);
System.out.println("product_name=" + product_name);
System.out.println("product_price=" + product_price);
System.out.println("product_picture=" + product_picture);
System.out.println("product_catalog_name=" + product_catalog_name);
// 高亮信息
if (response.getHighlighting() !=null) {
if (response.getHighlighting().get(id) !=null) {
Map<String, List<String>> map = response.getHighlighting().get(id);//取出高亮片段
if (map.get("product_name") !=null) {
for (String s : map.get("product_name")) {
System.out.println(s);
}
}
}
}
}
}
solrj查询结果高亮处理(二)
| @Test public void selectHighlighter() throws SolrServerException, IOException { HttpSolrServer solrServer = new HttpSolrServer("http://192.168.0.250:8080/solr-6.2.0/itcast1"); SolrQuery solrQuery = new SolrQuery("跟风"); solrQuery.setHighlight(true);//开启高亮 solrQuery.addHighlightField("title");//设置高亮字段 solrQuery.addHighlightField("content");//设置高亮字段 solrQuery.setHighlightFragsize(200);//设置摘要长度 solrQuery.setHighlightSimplePre("<font color='red'>");//设置前缀 solrQuery.setHighlightSimplePost("</font>");//设置后缀 QueryResponse queryResponse = solrServer.query(solrQuery);//查询 Map<String, Map<String, List<String>>> highlighting = queryResponse.getHighlighting();//获取高亮内容 System.out.println(highlighting); Set<String> ids = highlighting.keySet();//获取所有的id for (String string : ids) {//循环id Map<String, List<String>> map = highlighting.get(string);//通过id获取document内容 Set<String> keySet = map.keySet();//获取field的名称们 for (String string2 : keySet) {//循环 System.out.println(string2);//title or content List<String> list = map.get(string2);//获取field下的值 for (String string3 : list) { System.out.println(string3);//内容 } } } } |
solrj 提供获取高亮摘要内容 单独方法 ,返回是Map
map的key是id
map的value是Map<String,List<String>>(key是field的名称,value是高亮摘要内容 )
SolrQuery详细用法
返回值格式
通过分析抓包,SolrQuery 默认传递wt=javabin参数,通信数据格式是javabin
问题: 能否改变solrj 通信数据格式 ?
通过solrj 解析器设置。完成修改
| HttpSolrServer solrServer = new HttpSolrServer("http://192.168.0.250:8080/solr-6.2.0/itcast1"); solrServer.setParser(new XMLResponseParser()); |
返回的field和返回行数
1、设置修改fl参数 (fl参数,需要查询哪些field)
| SolrQuery solrQuery = new SolrQuery("方式"); solrQuery.setRows(7); solrQuery.set("fl", "id,title"); |
1、 通过设置fields
| solrQuery.setFields("id","title"); |
2、 通过添加field
| query.addField("id"); query.addField("title"); |
自定义排序
按照字段排序输出
| query.setSort("id", ORDER.asc); |

















 4311
4311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









