







HBase 是一个分布式[集群]、可扩展[动态上下线]、支持海量存储的 NoSQL 数据库。相当于 BigTable,负责海量数据的存储。如果数据量小的时候不适合使用 HBase,因为生产上需要不断的切分和合并比较消耗资源。如果数据量比较大,可以做到几十亿条数据秒级查询。支持数据的增删改查,实现了 HDFS 的随机写操作。
一、数据模型
逻辑上,HBase 的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map。下图的整个内容成为一张表。

【1】行键 RowKey: 是一张表中自动生成的唯一的、且有序的,按照“字典序”进行排序的主键;
【2】列族: 不同的列族放在不同的文件夹中,列族中的列可以有多个或者一个,列可以动态增加;
【3】Region切片: 按照 RowKey 进行切分,如上是按照3个 rowkey 进行划分的。一般是按照数据量进行划分,这样访问时能够提高效率;
【4】store: 实际存储数据的文件,存放在 HDSF。如上表中的数据是放在 6个 store 中;
二、HBase 物理存储结构

根据每一个列进行存储,例如张三:包含RowKey、ColumnFamily列族、ColumnQualifier列名、TimeStamp时间戳[实现HD 的随机写操作,完全由次属性决定,它优化最大的地方就是时间戳,该属性非常重要,window与Linux 一个用来操作一个用来存放时,需要两个操作系统的时间一定要相同,否则会出现很多问题]、Type类型[Put表示插入]、Value存放的值。当修改一条数据时,其实会添加一条数据与旧数据不同的是时间戳和value,此时,在获取数据的时候,它只会获取时间戳最大的那条数据。当删除一条数据时,也是添加一条数据与旧数据不同的是时间戳和Type,Type类型是 Delete。在获取的时候发现Delete类型的时间戳比 PUT的时间戳大,那就不返回数据。那么旧的数据对用户而言就是垃圾数据了,此时HBase还会存储着,但是最终它还是会从内存中将垃圾干掉的。是在后期表的分合操作的时候删除的。
三、数据模型
【1】Name Space: 命名空间,类似于关系型数据库的 database概念,每个命名空间下有多张表。HBase 有两个自带的命名空间,分别是 hbase 和 default。hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间。
【2】Region: 类似于关系型数据库的表的概念。不同的是,HBase定义表时只需要声明列族即可,不需要声明具体的列。意味着,往 HBase中写入数据时,字段可以动态、按需指定。因此和关系型数据库相比,HBase能够轻松应对字段变更的场景。
【3】ROW: HBase 表中的每行数据由一个 RowKey和多个 Column(列)组成,数据是按照 RowKey的字典顺序存储,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey的设计十分重要。
【4】Column: HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如:info: name,info: age。建表时,只需要声明列族,而列限定名无需预先定义。
【5】TimeStamp: 用于表示数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为期加上该字段,表示数据写入HBase 的时间。
【6】Cell: 由{RowKey,Column Family,Column Qualifier,TimeStamp}唯一确定的单元,cell中的数据是没有类型的,全部是字节码形式存储的。
四、HBase 基本架构
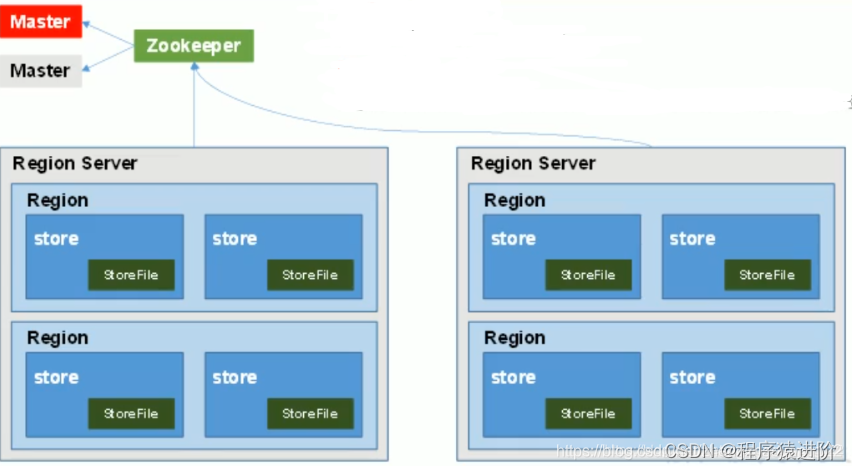
【1】Region切片需要分在 Region Server[多个,分布式的]上,Region 中包含多个 store[存储实际的数据],刚开始操作的store是在内存中的,最终会在一定数量或时间时会flush到磁盘 storefile;
【2】Region Server 的作用: Data:Get、Put、Delete[Update操作底层是新PUT了一条数据,时间戳和 value 会发生变化,Delete 也是 Put了一条数据,Type是Delete];Region:SplitRegion、CompactRegion。作为 Region 的管理者;
【3】Master: 作为 HBase操作的入口,依赖于ZK来管理集群,HBase 中的操作非常多,因此会将一些任务分配给ZK,当 Master挂掉之后,对数据的增删改查时没有问题的,但是对表级别的增删改查是不能完成的。Master类似于DDL。ZK类似于DML。作用:Table 的 Create,Delete,Alter;RegionServer:分配 Region 到每个 RegionServer,监控每个 RegionServer 的状态,负载均衡和故障转移;
【4】ZK: HBase 通过 ZK来做master的高可用,RegionServer的监控、元数据的入口以及集群配置的维护等工作;
【5】HDFS: HDFS 为 HBase提供最终的底层数据存储服务,同时为 HBase提供高可用的支持;
















 1143
1143











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











