







一.Storm、Hadoop、Spark基本概念与对比
Hadoop是磁盘级计算,进行计算时,数据在磁盘上,需要读写磁盘;Storm是内存级计算,数据直接通过网络导入内存。读写内存比读写磁盘速度快n个数量级。根据Harvard CS61课件,磁盘访问延迟约为内存访问延迟的75000倍。所以Storm更快。
注释:
1. 延时 , 指数据从产生到运算产生结果的时间,“快”应该主要指这个。
2. 吞吐, 指系统单位时间处理的数据量。
storm的网络直传、内存计算,其时延必然比hadoop的通过hdfs传输低得多;当计算模型比较适合流式时,storm的流式处理,省去了批处理的收集数据的时间;因为storm是服务型的作业,也省去了作业调度的时延。所以从时延上来看,storm要快于hadoop。
从原理角度来讲:
Hadoop M/R基于HDFS,需要切分输入数据、产生中间数据文件、排序、数据压缩、多份复制等,效率较低。
Storm 基于ZeroMQ这个高性能的消息通讯库,不持久化数据。
Storm的主要特点如下:
1.简单的编程模型。类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性。
2.可以使用各种编程语言。你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
3.容错性。Storm会管理工作进程和节点的故障。
4.水平扩展。计算是在多个线程、进程和服务器之间并行进行的。
5.可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
6.快速。系统的设计保证了消息能得到快速的处理,使用MQ作为其底层消息队列。
7.本地模式。Storm有一个“本地模式”,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
高性能并行计算引擎Storm和Spark比较
Spark基于这样的理念,当数据庞大时,把计算过程传递给数据要比把数据传递给计算过程要更富效率。每个节点存储(或缓存)它的数据集,然后任务被提交给节点。
所以这是把过程传递给数据。这和Hadoop map/reduce非常相似,除了积极使用内存来避免I/O操作,以使得迭代算法(前一步计算输出是下一步计算的输入)性能更高。
Shark只是一个基于Spark的查询引擎(支持ad-hoc临时性的分析查询)
而Storm的架构和Spark截然相反。Storm是一个分布式流计算引擎。每个节点实现一个基本的计算过程,而数据项在互相连接的网络节点中流进流出。和Spark相反,这个是把数据传递给过程。
两个框架都用于处理大量数据的并行计算。
Storm在动态处理大量生成的“小数据块”上要更好(比如在Twitter数据流上实时计算一些汇聚功能或分析)。
Spark工作于现有的数据全集(如Hadoop数据)已经被导入Spark集群,Spark基于in-memory管理可以进行快讯扫描,并最小化迭代算法的全局I/O操作。
不过Spark流模块(Streaming Module)倒是和Storm相类似(都是流计算引擎),尽管并非完全一样。
Spark流模块先汇聚批量数据然后进行数据块分发(视作不可变数据进行处理),而Storm是只要接收到数据就实时处理并分发。
Storm架构设计
1.Storm Mode:Local Mode Remote Mode。Remote Mode不能显示debug信息,视为生产环境
2.流式大数据特征:用有向无环图(directed acyclic graph,简称DAG)描述了大数据流的计算过程。
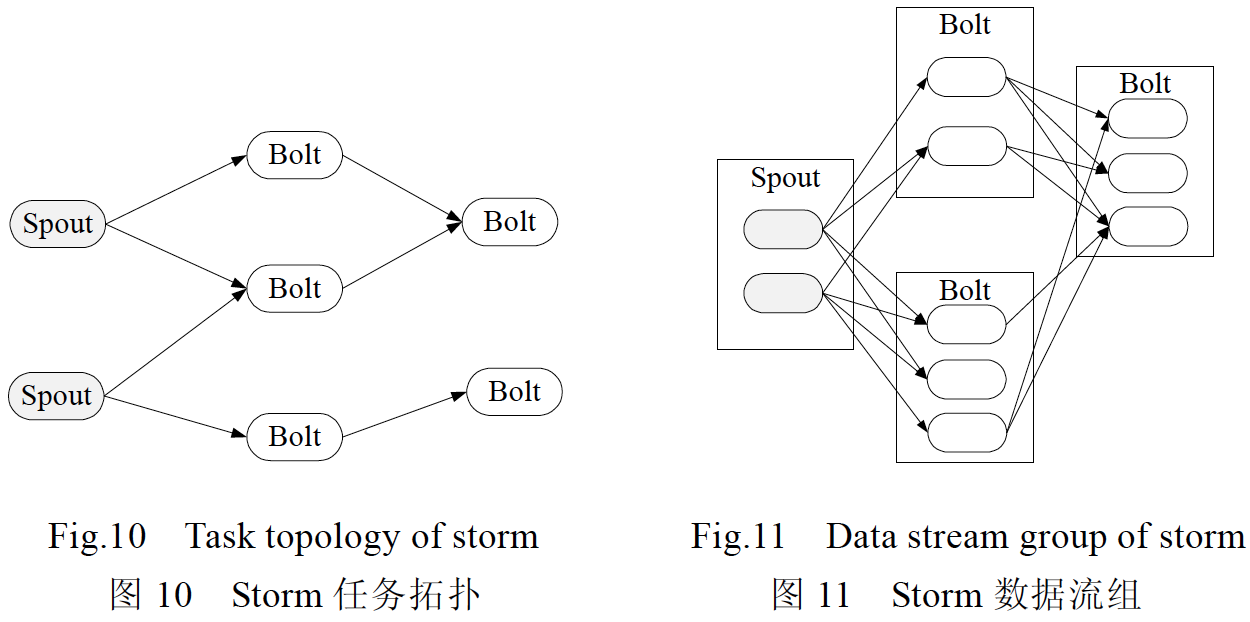
任务拓扑(topology)是Storm 的逻辑单元,一个实时应用的计算任务将被打包为任务拓扑后发布,任务拓扑一旦提交后将会一直运行着,除非显式地去中止.Spout 负责从外部数据源不间断地读取数据,并以Tuple 元组的形式发送给相应的Bolt;Bolt 负责对接收到的数据流进行计算,实现过滤、聚合、查询等具体功能,可以级联,也可以向外发送数据流.
数据流是Storm 对数据进行的抽象,它是时间上无穷的Tuple 元组序列,如图11 所示,数据流是通过流分组(stream grouping)所提供的不同策略实现在任务拓扑中流动.此外,为了满足确保消息能且仅能被计算1 次的需求,Storm 还提供了事务任务拓扑.
3.Storm作业级容错机制:用户可以为一个或多个数据流作业(以下简称数据流)进行编号,分配一个唯一的ID,Storm 可以保障每个编号的数据流在任务拓扑中被完全执行.所谓的完全执行,是指由该ID 绑定的源数据流以及由该源数据流后续生成的新数据流经过任务拓扑中每一个应该到达的Bolt,并被完全执行.
Storm 通过系统级组件Acker 实现对数据流的全局计算路径的跟踪,并保证该数据流被完全执行.其基本原理是为数据流中的每个分组进行编号,通过异或运算来实现对其计算路径的跟踪.
作业级容错的基本原理是:
A xor A=0.
A xor B … xor B xor A=0,当且仅当每个编号仅出现2 次.
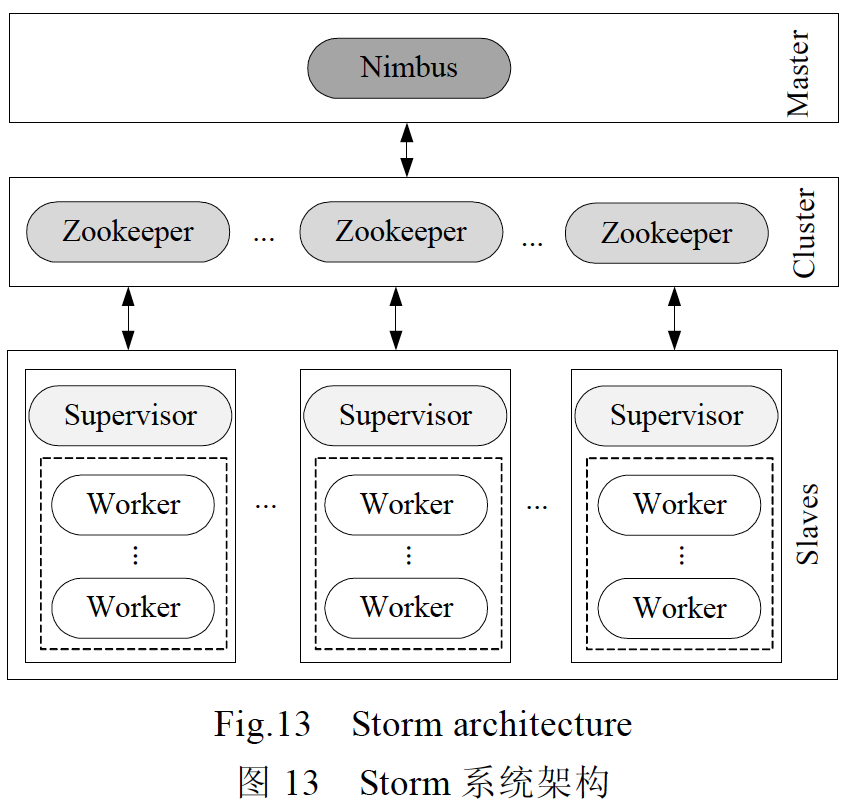
4.总体架构:Storm 采用主从系统架构,如图13 所示,在一个Storm 系统中有两类节点(即,一个主节点Nimbus、多个从节点Supervisor)及3 种运行环境(即,master,cluster 和slaves)构成.
主节点Nimbus 运行在master 环境中,是无状态的,负责全局的资源分配、任务调度、状态监控和故障检测.
从节点Supervisor 运行在slaves 环境中,也是无状态的,负责监听并接受来自于主节点Nimbus 所分配的任务,并启动或停止自己所管理的工作进程Worker,其中,工作进程Worker 负责具体任务的执行.















 2715
2715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









