






文章目录
五、实现“Character-Level Language Models”源代码(必做)
关于有激活函数的问题的解决办法(希望老师,各位大佬批评指正)
前言
这两天在统计一些网格化的信息,真的有点累,但是我也好好看了这些问题,虽然很累,但是感觉都是值得的(哈哈哈)。
最后,写的不太好,请老师和各位大佬批评指正。

一、使用Numpy实现SRN

# coding=gbk
import numpy as np
inputs = np.array([[1., 1.],
[1., 1.],
[2., 2.]]) # 初始化输入序列
print('inputs is ', inputs)
state_t = np.zeros(2, ) # 初始化存储器
print('state_t is ', state_t)
w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('--------------------------------------')
for input_t in inputs:
print('inputs is ', input_t)
print('state_t is ', state_t)
in_h1 = np.dot([w1, w3], input_t) + np.dot([U2, U4], state_t)
in_h2 = np.dot([w2, w4], input_t) + np.dot([U1, U3], state_t)
state_t = in_h1, in_h2
print('a',state_t,in_h1,in_h2)
output_y1 = np.dot([w5, w7], [in_h1, in_h2])
output_y2 = np.dot([w6, w8], [in_h1, in_h2])
print('output_y is ', output_y1, output_y2)
print('---------------')运行结果为:
inputs is [[1. 1.]
[1. 1.]
[2. 2.]]
state_t is [0. 0.]
--------------------------------------
inputs is [1. 1.]
state_t is [0. 0.]
a (2.0, 2.0) 2.0 2.0
output_y is 4.0 4.0
---------------
inputs is [1. 1.]
state_t is (2.0, 2.0)
a (6.0, 6.0) 6.0 6.0
output_y is 12.0 12.0
---------------
inputs is [2. 2.]
state_t is (6.0, 6.0)
a (16.0, 16.0) 16.0 16.0
output_y is 32.0 32.0
---------------
这里要说一下这个,首先dot,它的性质是一维数组的话,产生的是一个值,向量内积,然后就是按着公式计算,尤其注意隐藏层出来是一个线性层,这个下边会细说,并且注意这个隐藏层出来,并不会经过激活层,这个和下边的也稍微有点区别需要注意一下。
二、 在1的基础上,增加激活函数tanh
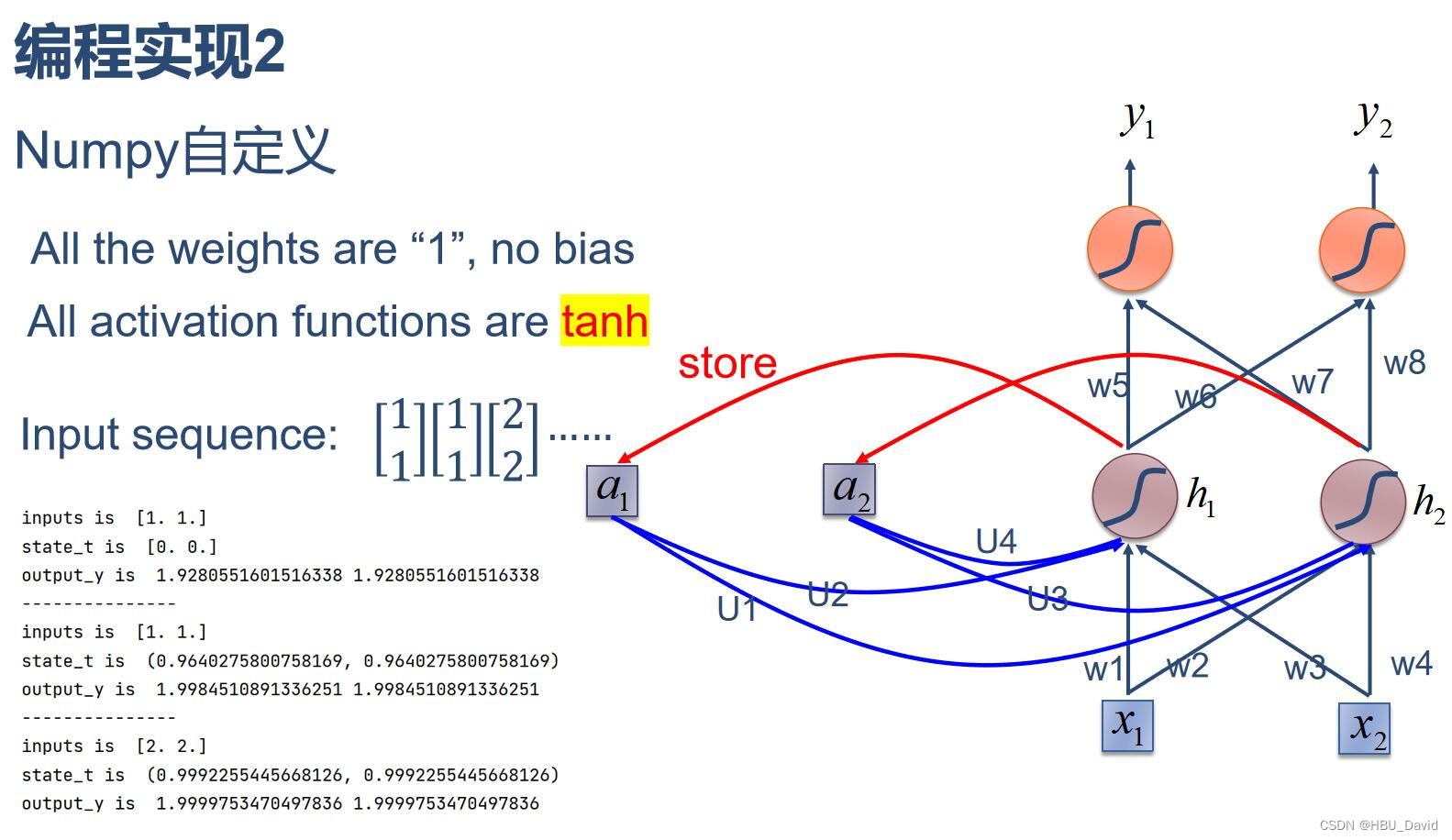
import numpy as np
inputs = np.array([[1., 1.],
[1., 1.],
[2., 2.]]) # 初始化输入序列
print('inputs is ', inputs)
state_t = np.zeros(2, ) # 初始化存储器
print('state_t is ', state_t)
w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('--------------------------------------')
for input_t in inputs:
print('inputs is ', input_t)
print('state_t is ', state_t)
in_h1 = np.tanh(np.dot([w1, w3], input_t) + np.dot([U2, U4], state_t))
in_h2 = np.tanh(np.dot([w2, w4], input_t) + np.dot([U1, U3], state_t))
state_t = in_h1, in_h2
output_y1 = np.dot([w5, w7], [in_h1, in_h2])
output_y2 = np.dot([w6, w8], [in_h1, in_h2])
print('output_y is ', output_y1, output_y2)
print('---------------')运行结果为:
inputs is [[1. 1.]
[1. 1.]
[2. 2.]]
state_t is [0. 0.]
--------------------------------------
inputs is [1. 1.]
state_t is [0. 0.]
output_y is 1.9280551601516338 1.9280551601516338
---------------
inputs is [1. 1.]
state_t is (0.9640275800758169, 0.9640275800758169)
output_y is 1.9984510891336251 1.9984510891336251
---------------
inputs is [2. 2.]
state_t is (0.9992255445668126, 0.9992255445668126)
output_y is 1.9999753470497836 1.9999753470497836
---------------
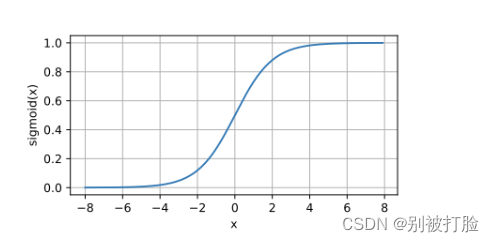
这个和上一个区别就是用了一下tanh这个激活函数,这个放一下tanh这个函数的图像。
三、分别使用nn.RNNCell、nn.RNN实现SRN
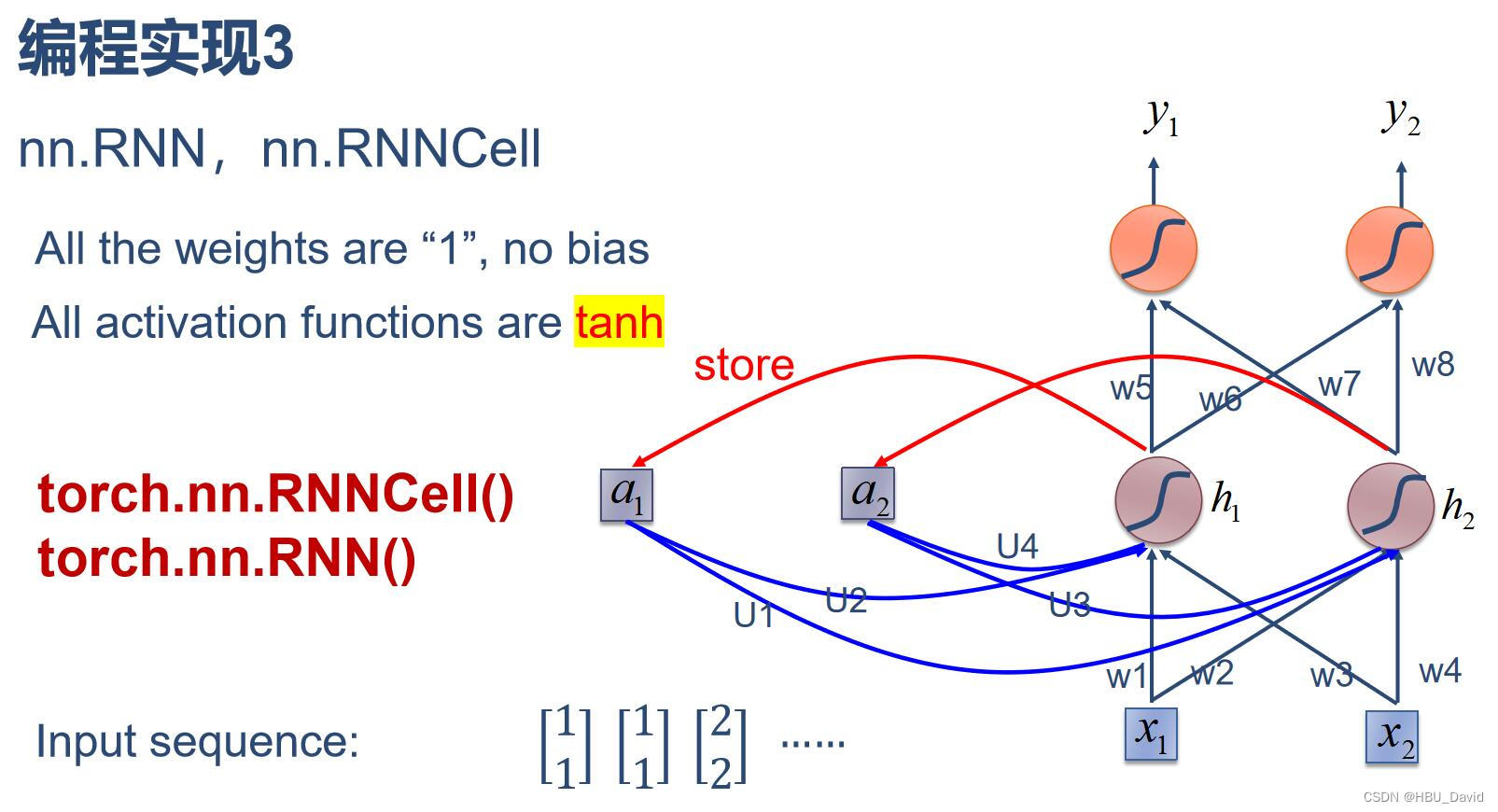
1、用torch.nn.RNNCell()
import numpy as np
inputs = np.array([[1., 1.],
[1., 1.],
[2., 2.]]) # 初始化输入序列
print('inputs is ', inputs)
state_t = np.zeros(2, ) # 初始化存储器
print('state_t is ', state_t)
w1, w2, w3, w4, w5, w6, w7, w8 = 1., 1., 1., 1., 1., 1., 1., 1.
U1, U2, U3, U4 = 1., 1., 1., 1.
print('--------------------------------------')
for input_t in inputs:
print('inputs is ', input_t)
print('state_t is ', state_t)
in_h1 = np.tanh(np.dot([w1, w3], input_t) + np.dot([U2, U4], state_t))
in_h2 = np.tanh(np.dot([w2, w4], input_t) + np.dot([U1, U3], state_t))
state_t = in_h1, in_h2
output_y1 = np.dot([w5, w7], [in_h1, in_h2])
output_y2 = np.dot([w6, w8], [in_h1, in_h2])
print('output_y is ', output_y1, output_y2)
print('---------------')运行结果为:
==================== 0 ====================
Input : tensor([[1., 1.]])
hidden : tensor([[0., 0.]])
output : tensor([[4., 4.]], grad_fn=<AddmmBackward0>)
==================== 1 ====================
Input : tensor([[1., 1.]])
hidden : tensor([[2., 2.]], grad_fn=<ReluBackward0>)
output : tensor([[12., 12.]], grad_fn=<AddmmBackward0>)
==================== 2 ====================
Input : tensor([[2., 2.]])
hidden : tensor([[6., 6.]], grad_fn=<ReluBackward0>)
output : tensor([[32., 32.]], grad_fn=<AddmmBackward0>)
2、torch.nn.RNN
import torch
batch_size = 1
seq_len = 3
input_size = 2
hidden_size = 2
num_layers = 1
output_size = 2
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers,nonlinearity='relu')
for name, param in cell.named_parameters(): # 初始化参数
if name.startswith("weight"):
torch.nn.init.ones_(param)
else:
torch.nn.init.zeros_(param)
# 线性层
liner = torch.nn.Linear(hidden_size, output_size)
liner.weight.data = torch.Tensor([[1, 1], [1, 1]])
liner.bias.data = torch.Tensor([0.0])
inputs = torch.Tensor([[[1, 1]],
[[1, 1]],
[[2, 2]]])
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print('out',out,hidden)
print('Input :', inputs[0])
print('hidden:', 0, 0)
print('Output:', liner(out[0]))
print('--------------------------------------')
print('Input :', inputs[1])
print('hidden:', out[0])
print('Output:', liner(out[1]))
print('--------------------------------------')
print('Input :', inputs[2])
print('hidden:', out[1])
print('Output:', liner(out[2]))运行结果为:
out tensor([[[ 2., 2.]],
[[ 6., 6.]],
[[16., 16.]]], grad_fn=<StackBackward0>) tensor([[[16., 16.]]], grad_fn=<StackBackward0>)
Input : tensor([[1., 1.]])
hidden: 0 0
Output: tensor([[4., 4.]], grad_fn=<AddmmBackward0>)
--------------------------------------
Input : tensor([[1., 1.]])
hidden: tensor([[2., 2.]], grad_fn=<SelectBackward0>)
Output: tensor([[12., 12.]], grad_fn=<AddmmBackward0>)
--------------------------------------
Input : tensor([[2., 2.]])
hidden: tensor([[6., 6.]], grad_fn=<SelectBackward0>)
Output: tensor([[32., 32.]], grad_fn=<AddmmBackward0>)
这要先说一下RNN和RNNCell的用法
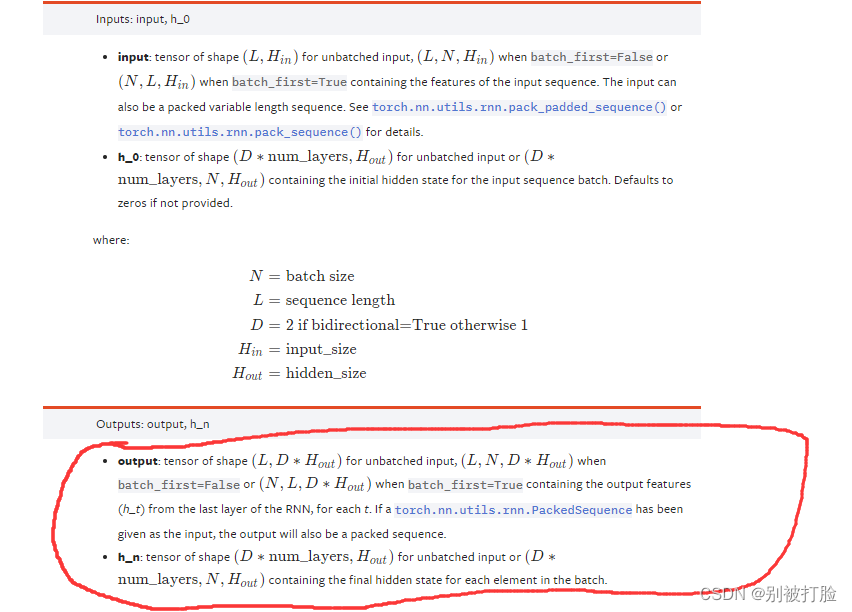
nn.RNN
使用nn.RNN方法有三个参数(input_size,hidden_size,num_layers)input_size是word_embedding的维度,比如用100维的向量来表示一个单词,那么input_size就是100;如果预测的是房价,房价就一个数字,那么input_size就是1
hidden_size是指memory size,我们用一个多长的向量来表达
h是最后一个时间戳上面的所有memory的状态
out是所有时间戳上面最后一个memory的状态nn.RNNCell
相比一步到位的nn.RNN,也可以使用nn.RNNCell,它将序列上的每个时刻分开来处理。
也就是说,如果要处理的是3个句子,每个句子10个单词,每个单词用长100的向量,那么送入nn.RNN的Tensor的shape就是[10,3,100]。
但如果使用nn.RNNCell,则将每个时刻分开处理,送入的Tensor的shape是[3,100],但要将此计算单元运行10次。显然这种方式比较麻烦,但使用起来也更灵活。
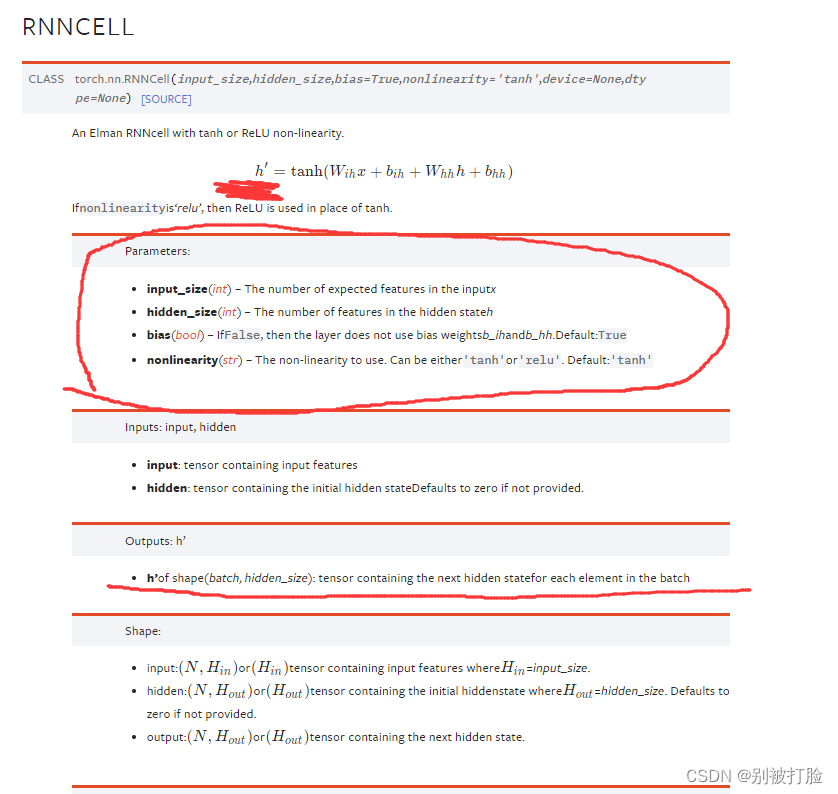

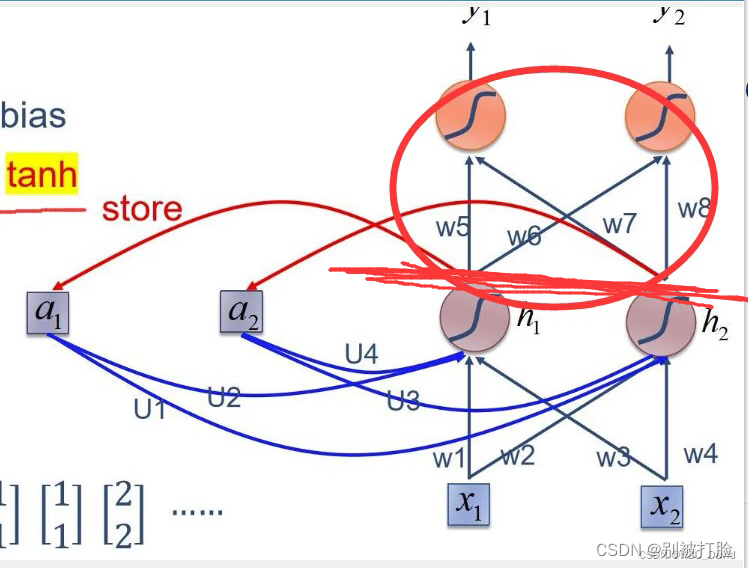
然后说一下,千万不要理解错了,网络的结构,RNN和RNNCell都只是到了隐藏层的输出,并没有最后那个线性层,也就是没有下边画圈的部分,就是到划线的那就结束了。
四、分析“二进制加法” 源代码(选做)

import copy, numpy as np
np.random.seed(0)
# compute sigmoid nonlinearity
def sigmoid(x):
output = 1 / (1 + np.exp(-x))
return output
# convert output of sigmoid function to its derivative
def sigmoid_output_to_derivative(output):
return output * (1 - output)
# training dataset generation
int2binary = {}
binary_dim = 8
largest_number = pow(2, binary_dim)
binary = np.unpackbits(
np.array([range(largest_number)], dtype=np.uint8).T, axis=1)
for i in range(largest_number):
int2binary[i] = binary[i]
# input variables
alpha = 0.1
input_dim = 2
hidden_dim = 16
output_dim = 1
# initialize neural network weights
synapse_0 = 2 * np.random.random((input_dim, hidden_dim)) - 1
synapse_1 = 2 * np.random.random((hidden_dim, output_dim)) - 1
synapse_h = 2 * np.random.random((hidden_dim, hidden_dim)) - 1
synapse_0_update = np.zeros_like(synapse_0)
synapse_1_update = np.zeros_like(synapse_1)
synapse_h_update = np.zeros_like(synapse_h)
# training logic
for j in range(10000):
# generate a simple addition problem (a + b = c)
a_int = np.random.randint(largest_number / 2) # int version
a = int2binary[a_int] # binary encoding
b_int = np.random.randint(largest_number / 2) # int version
b = int2binary[b_int] # binary encoding
# true answer
c_int = a_int + b_int
c = int2binary[c_int]
# where we'll store our best guess (binary encoded)
d = np.zeros_like(c)
overallError = 0
layer_2_deltas = list()
layer_1_values = list()
layer_1_values.append(np.zeros(hidden_dim))
# moving along the positions in the binary encoding
for position in range(binary_dim):
# generate input and output
X = np.array([[a[binary_dim - position - 1], b[binary_dim - position - 1]]])
y = np.array([[c[binary_dim - position - 1]]]).T
# hidden layer (input ~+ prev_hidden)
layer_1 = sigmoid(np.dot(X, synapse_0) + np.dot(layer_1_values[-1], synapse_h))
# output layer (new binary representation)
layer_2 = sigmoid(np.dot(layer_1, synapse_1))
# did we miss?... if so, by how much?
layer_2_error = y - layer_2
layer_2_deltas.append((layer_2_error) * sigmoid_output_to_derivative(layer_2))
overallError += np.abs(layer_2_error)
# decode estimate so we can print it out
d[binary_dim - position - 1] = np.round(layer_2[0][0])
# store hidden layer so we can use it in the next timestep
layer_1_values.append(copy.deepcopy(layer_1))
future_layer_1_delta = np.zeros(hidden_dim)
for position in range(binary_dim):
X = np.array([[a[position], b[position]]])
layer_1 = layer_1_values[-position - 1]
prev_layer_1 = layer_1_values[-position - 2]
# error at output layer
layer_2_delta = layer_2_deltas[-position - 1]
# error at hidden layer
layer_1_delta = (future_layer_1_delta.dot(synapse_h.T) + layer_2_delta.dot(
synapse_1.T)) * sigmoid_output_to_derivative(layer_1)
# let's update all our weights so we can try again
synapse_1_update += np.atleast_2d(layer_1).T.dot(layer_2_delta)
synapse_h_update += np.atleast_2d(prev_layer_1).T.dot(layer_1_delta)
synapse_0_update += X.T.dot(layer_1_delta)
future_layer_1_delta = layer_1_delta
synapse_0 += synapse_0_update * alpha
synapse_1 += synapse_1_update * alpha
synapse_h += synapse_h_update * alpha
synapse_0_update *= 0
synapse_1_update *= 0
synapse_h_update *= 0
# print out progress
if (j % 1000 == 0):
print("Error:" + str(overallError))
print("Pred:" + str(d))
print("True:" + str(c))
out = 0
for index, x in enumerate(reversed(d)):
out += x * pow(2, index)
print(str(a_int) + " + " + str(b_int) + " = " + str(out))
print("------------")运行结果为:
Error:[[3.45638663]]
Pred:[0 0 0 0 0 0 0 1]
True:[0 1 0 0 0 1 0 1]
9 + 60 = 1
------------
Error:[[3.63389116]]
Pred:[1 1 1 1 1 1 1 1]
True:[0 0 1 1 1 1 1 1]
28 + 35 = 255
------------
Error:[[3.91366595]]
Pred:[0 1 0 0 1 0 0 0]
True:[1 0 1 0 0 0 0 0]
116 + 44 = 72
------------
Error:[[3.72191702]]
Pred:[1 1 0 1 1 1 1 1]
True:[0 1 0 0 1 1 0 1]
4 + 73 = 223
------------
Error:[[3.5852713]]
Pred:[0 0 0 0 1 0 0 0]
True:[0 1 0 1 0 0 1 0]
71 + 11 = 8
------------
Error:[[2.53352328]]
Pred:[1 0 1 0 0 0 1 0]
True:[1 1 0 0 0 0 1 0]
81 + 113 = 162
------------
Error:[[0.57691441]]
Pred:[0 1 0 1 0 0 0 1]
True:[0 1 0 1 0 0 0 1]
81 + 0 = 81
------------
Error:[[1.42589952]]
Pred:[1 0 0 0 0 0 0 1]
True:[1 0 0 0 0 0 0 1]
4 + 125 = 129
------------
Error:[[0.47477457]]
Pred:[0 0 1 1 1 0 0 0]
True:[0 0 1 1 1 0 0 0]
39 + 17 = 56
------------
Error:[[0.21595037]]
Pred:[0 0 0 0 1 1 1 0]
True:[0 0 0 0 1 1 1 0]
11 + 3 = 14
------------
这个要说一下那难理解的点,我就直接发作者的解释了。
第99行:这将计算当前隐藏层的错误,给定将来隐藏层的错误和当前输出层的错误。
102-104号线:现在我们已经在当前的时间步反向传播了导数,我们可以构造权重更新(但实际上还没有更新权重)。在我们完全反向传播所有内容之前,我们实际上不会更新权重矩阵。为什么?我们用权矩阵来进行反向传播。因此,我们不想改变他们,直到真正的反支撑完成。见 backprop博客文章更多细节
109-115号线现在我们已经支持了一切,并创建了我们的体重更新。是时候更新权重了(清空更新变量)。
这是关键,并且计算方式也是下边的这个。
看懂了这一步,反向传播就能看懂了,我也是查了好久的书才看明白。

五、实现“Character-Level Language Models”源代码(必做)
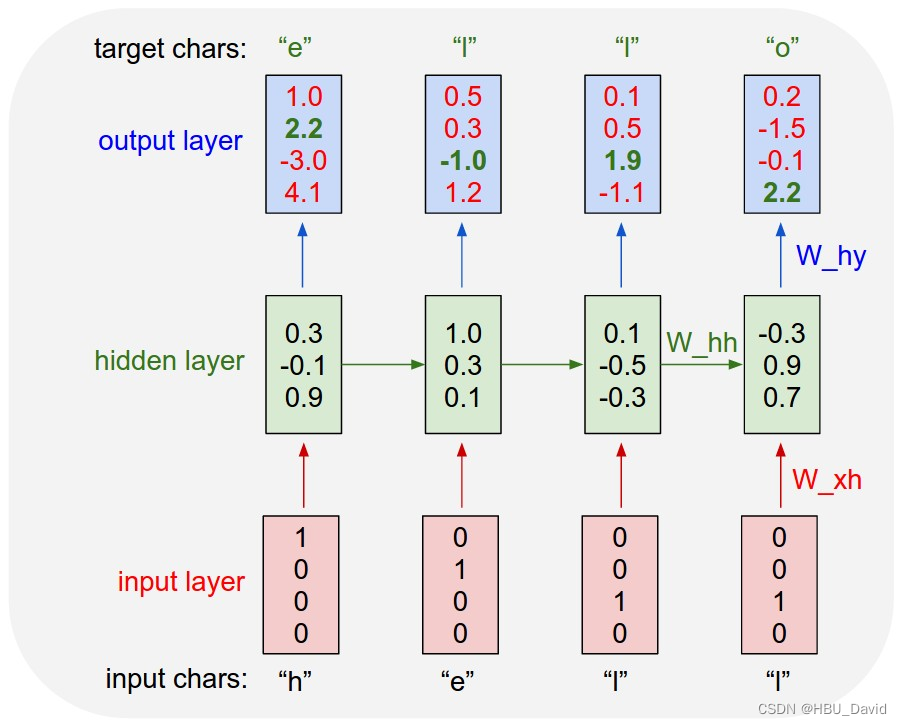
这个必须要好好说一下,弄出这个来的大佬是真厉害,先说一下这个是The Unreasonable Effectiveness of Recurrent Neural Networks中的代码,作者说了这个原本就是教学用的,说一下上边的例子是啥意思(这是我结合自己的理解,以及大佬给的例子综合说说)。
假设我们只有四个可能的字母“helo”的词汇表,并希望在训练序列“hello”上训练RNN。这个训练序列实际上是4个独立训练例子的来源:1.e的概率应该很可能是在“h”的上下文中,2.“l”应该很可能出现在“he”的上下文中,3.“l”也应该有可能给出“hel”的上下文,最后4.“o”应该很可能给出“hel”的上下文。
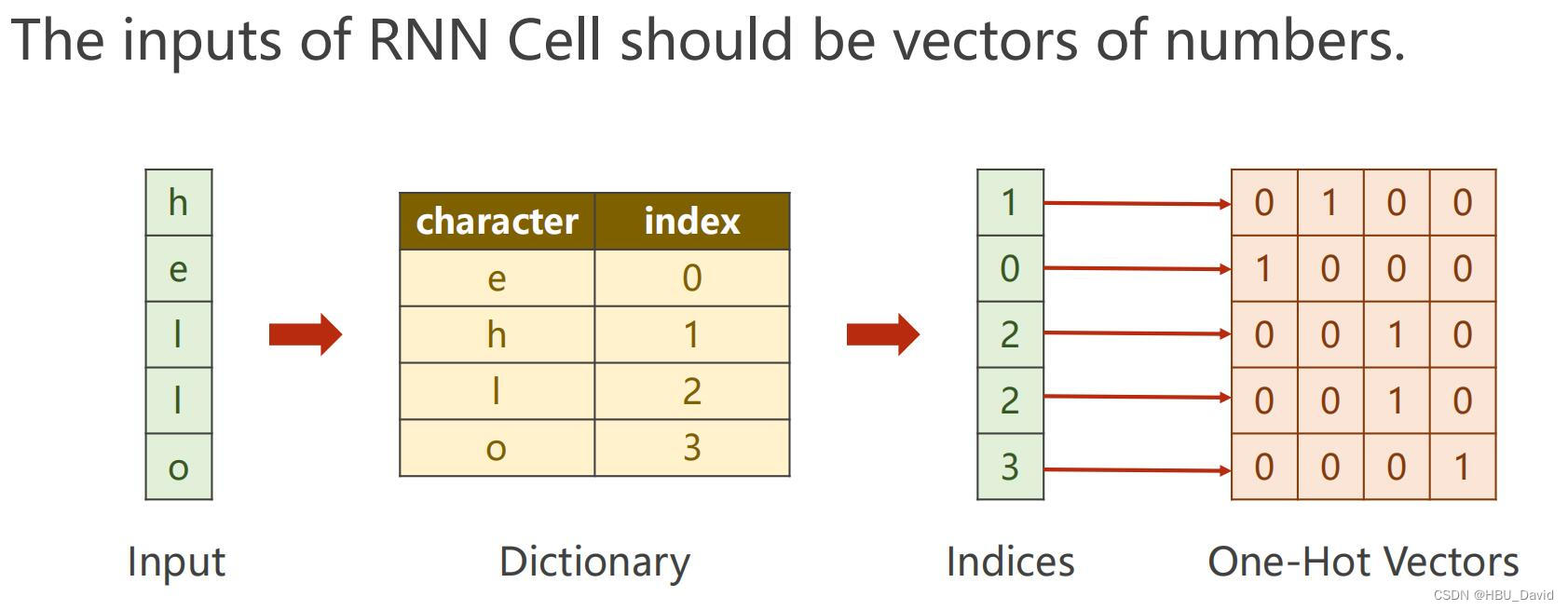
具体地说,我们将使用1/k编码将每个字符编码成一个向量(即除了词汇表中字符索引处的单个字符外,所有字符都为零),并使用step功能。然后我们将观察一个四维输出向量序列(每个字符一维),我们将其解释为RNN当前分配给序列中下一个字符的置信度。
我们看到,在第一个时间步中,当RNN看到字符“h”时,它为下一个字母“h”指定了1.0的置信度,对字母“e”的置信度为2.2,对字母“l”的置信度为-3.0,对“o”的置信度为4.1。因为在我们的训练数据(字符串“hello”)中,下一个正确的字符是“e”,我们希望增加它的置信度(绿色),并降低所有其他字母的置信度(红色)。类似地,我们在4个时间步中的每一个都有一个期望的目标角色,我们希望网络为其分配更大的置信度。由于RNN完全由可微操作组成,我们可以运行反向传播算法(这只是微积分中链式规则的递归应用),以确定我们应该在哪个方向调整其权重,以增加正确目标(绿色粗体数字)的得分。然后我们可以执行参数更新,它会在这个渐变方向上推动每个权重。如果我们在参数更新后将相同的输入输入输入到RNN,我们会发现正确字符的分数(例如第一个时间步中的“e”)将略高(例如,2.3而不是2.2),错误字符的分数将略低。然后我们重复这个过程多次,直到网络收敛,它的预测最终与训练数据一致,因为接下来总是预测正确的字符。
好了解释完上边的例子了,我们来看看代码
# coding=gbk
"""
Minimal character-level Vanilla RNN model. Written by Andrej Karpathy (@karpathy)
BSD License
"""
import numpy as np
import jieba
# data I/O
data = open('input.txt', 'rb').read() # should be simple plain text file
data = data.decode('gbk')
data = list(jieba.cut(data, cut_all=False))
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print('data has %d characters, %d unique.' % (data_size, vocab_size))
char_to_ix = {ch: i for i, ch in enumerate(chars)}
ix_to_char = {i: ch for i, ch in enumerate(chars)}
# hyperparameters
hidden_size = 200 # size of hidden layer of neurons
seq_length = 25 # number of steps to unroll the RNN for
learning_rate = 1e-1
# model parameters
Wxh = np.random.randn(hidden_size, vocab_size) * 0.01 # input to hidden
Whh = np.random.randn(hidden_size, hidden_size) * 0.01 # hidden to hidden
Why = np.random.randn(vocab_size, hidden_size) * 0.01 # hidden to output
bh = np.zeros((hidden_size, 1)) # hidden bias
by = np.zeros((vocab_size, 1)) # output bias
def lossFun(inputs, targets, hprev):
"""
inputs,targets are both list of integers.
hprev is Hx1 array of initial hidden state
returns the loss, gradients on model parameters, and last hidden state
"""
xs, hs, ys, ps = {}, {}, {}, {}
hs[-1] = np.copy(hprev) # hprev 中间层的值, 存作-1,为第一个做准备
loss = 0
# forward pass
for t in range(len(inputs)):
xs[t] = np.zeros((vocab_size, 1)) # encode in 1-of-k representation
xs[t][inputs[t]] = 1 # x[t] 是一个第t个输入单词的向量
# 双曲正切, 激活函数, 作用跟sigmoid类似
# h(t) = tanh(Wxh*X + Whh*h(t-1) + bh) 生成新的中间层
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t - 1]) + bh) # hidden state tanh
# y(t) = Why*h(t) + by
ys[t] = np.dot(Why, hs[t]) + by # unnormalized log probabilities for next chars
# softmax regularization
# p(t) = softmax(y(t))
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars, 对输出作softmax
# loss += -log(value) 预期输出是1,因此这里的value值就是此次的代价函数,使用 -log(*) 使得离正确输出越远,代价函数就越高
loss += -np.log(ps[t][targets[t], 0]) # softmax (cross-entropy loss) 代价函数是交叉熵
# 将输入循环一遍以后,得到各个时间段的h, y 和 p
# 得到此时累积的loss, 准备进行更新矩阵
# backward pass: compute gradients going backwards
dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why) # 各矩阵的参数进行
dbh, dby = np.zeros_like(bh), np.zeros_like(by)
dhnext = np.zeros_like(hs[0]) # 下一个时间段的潜在层,初始化为零向量
for t in reversed(range(len(inputs))): # 把时间作为维度,则梯度的计算应该沿着时间回溯
dy = np.copy(ps[t]) # 设dy为实际输出,而期望输出(单位向量)为y, 代价函数为交叉熵函数
dy[targets[t]] -= 1 # backprop into y. see http://cs231n.github.io/neural-networks-case-study/#grad if confused here
dWhy += np.dot(dy, hs[t].T) # dy * h(t).T h层值越大的项,如果错误,则惩罚越严重。反之,奖励越多(这边似乎没有考虑softmax的求导?)
dby += dy # 这个没什么可说的,与dWhy一样,只不过h项=1, 所以直接等于dy
dh = np.dot(Why.T, dy) + dhnext # backprop into h z_t = Why*H_t + b_y H_t = tanh(Whh*H_t-1 + Whx*X_t), 第一阶段求导
dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity 第二阶段求导,注意tanh的求导
dbh += dhraw # dbh表示传递 到h层的误差
dWxh += np.dot(dhraw, xs[t].T) # 对Wxh的修正,同Why
dWhh += np.dot(dhraw, hs[t - 1].T) # 对Whh的修正
dhnext = np.dot(Whh.T, dhraw) # h层的误差通过Whh不停地累积
for dparam in [dWxh, dWhh, dWhy, dbh, dby]:
np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients
return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs) - 1]
def sample(h, seed_ix, n):
"""
sample a sequence of integers from the model
h is memory state, seed_ix is seed letter for first time step
"""
x = np.zeros((vocab_size, 1))
x[seed_ix] = 1
ixes = []
for t in range(n):
h = np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh) # 更新中间层
y = np.dot(Why, h) + by # 得到输出
p = np.exp(y) / np.sum(np.exp(y)) # softmax
ix = np.random.choice(range(vocab_size), p=p.ravel()) # 根据softmax得到的结果,按概率产生下一个字符
x = np.zeros((vocab_size, 1)) # 产生下一轮的输入
x[ix] = 1
ixes.append(ix)
return ixes
n, p = 0, 0
mWxh, mWhh, mWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)
mbh, mby = np.zeros_like(bh), np.zeros_like(by) # memory variables for Adagrad
smooth_loss = -np.log(1.0 / vocab_size) * seq_length # loss at iteration 0
while True:
# prepare inputs (we're sweeping from left to right in steps seq_length long)
if p + seq_length + 1 >= len(data) or n == 0: # 如果 n=0 或者 p过大
hprev = np.zeros((hidden_size, 1)) # reset RNN memory 中间层内容初始化,零初始化
p = 0 # go from start of data # p 重置
inputs = [char_to_ix[ch] for ch in data[p:p + seq_length]] # 一批输入seq_length个字符
targets = [char_to_ix[ch] for ch in data[p + 1:p + seq_length + 1]] # targets是对应的inputs的期望输出。
# sample from the model now and then
if n % 100 == 0: # 每循环100词, sample一次,显示结果
sample_ix = sample(hprev, inputs[0], 200)
txt = ''.join(ix_to_char[ix] for ix in sample_ix)
print('----\n %s \n----' % (txt,))
# forward seq_length characters through the net and fetch gradient
loss, dWxh, dWhh, dWhy, dbh, dby, hprev = lossFun(inputs, targets, hprev)
smooth_loss = smooth_loss * 0.999 + loss * 0.001 # 将原有的Loss与新loss结合起来
if n % 100 == 0: print('iter %d, loss: %f' % (n, smooth_loss)) # print progress
# perform parameter update with Adagrad
for param, dparam, mem in zip([Wxh, Whh, Why, bh, by],
[dWxh, dWhh, dWhy, dbh, dby],
[mWxh, mWhh, mWhy, mbh, mby]):
mem += dparam * dparam # 梯度的累加
param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update 随着迭代次数增加,参数的变更量会越来越小
p += seq_length # move data pointer
n += 1 # iteration counter, 循环次数运行结果为:
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\LENOVO\AppData\Local\Temp\jieba.cache
Loading model cost 0.599 seconds.
Prefix dict has been built successfully.
data has 472364 characters, 13335 unique.
----
CitybarrostentationEverboildreamersdubbspeakscollectedevidencewaddlednourishlovespertainEncouragecureswasfromstabbedalightedwishingsteppdeformityhellishDestiniesoblivionsuesknowsForbiddenfargratulategoingabhorrEnvironviewappliedWidowLendmeanretirementdistanceembossnicelychidejogthrillingweepingdislodgedintegritybondSubjectsmustyretreatcurfewvenutoProceedcoolingpresentsdisobedientsolemnitywhatsoededicateunpossesspiednessunfeignedlyclamorousinheritedSpiritssnatchlarumsacrificesleatherpilgrimhorsemanmisgivesKentishmenTarquincoastcallventedguidergrovetemporarysportiveheathlevenreduceNeedssirsSaintmountsignetcontendedvaliantnessthemestaperCARLISLEWeaponsafeardPrefixmisgivesravisherunconstantshowinglampsweaklyscruplefistinghostNorfolkvouchedconceptionworsemisgivefitsrefrainpinnHitherbudprobationsilkenDespitefulCALIBANcoursesEdespairingsonClaremermaidsendsDryraimentspoonsestablishedexquisiterequitesFlutterenvyingEarthsubtlesuccessesatomiesmercifulDirectsayestembroidercontinencyabundantshamefullimberminstrelBessStandAmazonianunactiveJudaseswherewithalkeepingThyDukesDishonourableLaurenceWestmorelandWhoseborndwellssnatchinferrAttendRaininterruptabroachWorcesterhandledapishheadingtestamentjayfollowerpigUnaptcavilmeacockLieutenantfangalleryeasterncostardtogebaleShedTalkclutchheavierprosperityboottoricherfallenwing
----
iter 0, loss: 237.453687
----
ifseat: seat brain seat ,seatIbrain ,seat brain seat cranks ,seat brain seat, ,brain ,seat brain , brain seat brain ,seat brain seat Whatbrain participate brain
,seat brain seat,brain ,seat brain ,seat seat brain , brain ,seat brain seat:good seatbut seat brain them brain ,seat brain seat seat,brain .seat brain ,seat brain brain , ,brain seat,brain seatt seat brain seat brain
,seat brain
,seat
----
iter 100, loss: 243.846102
----
wonder
Hisbrookinsolencewonder His insolencewonder Hisbrookcommandedwonder
Hisbrookcommandedwonder Hisbrookinsolencewonder brookcommandedwonder brookinsolencewonder
Hisbrookinsolencewonder
Hisbrookinsolencewonder. brookinsolencewonder Hisbrookcommandedwonder.Hisbrookinsolencewonder
brookinsolencewonder
Hisbrookcommandedwonder
thebrookcommandedwonder brookcommandedwonderbrookcommandedwonder
:brookcommandedwonder hisbrookcommandedwonder Hisbrookinsolencewonder brookinsolencewonder Hisbrookcommandedwonder Hisbrookinsolencewonder
Hisbrookinsolencewonder thebrookinsolencewonder Hisbrookcommandedwonder Hisbrookinsolencewonder brookinsolencewonder
Hisbrookcommandedwonder Hisbrookcommandedwonder
Hisbrookinsolencewonder Hisbrookinsolencewonder Hisbrookinsolencewonder Hisbrookinsolencewonder
brookinsolencewonder Hisbrookinsolencewonder Hisbrookinsolencewonder Hisbrookinsolencewonder
Hisbrookinsolencewonder
brookcommanded
----
iter 200, loss: 243.948236
----
shall.
She shall.
She
I
the She shall,
She shall
'She : Shehershall, She.: She shall ,you
She
, She shall IndeedShe
,
She .
She ,.
She shall
SecondShe : She.
,VIRGILIAShe
She,shall,;She :,
:IVIRGILIASheAndshall VIRGILIAShe She shall: She
:
SheVALERIA:
,She shall
She shall VIRGILIASheShe :
She ,:Oshall
iftoShe , She .
She shall
She shall :She
----
iter 300, loss: 242.148066
----
tdangerousphysical
dangerousphysical
, physicalto todangerousphysical
,dangerousphysical
' physical:,:dangerousphysical
dangerousphysical, dangerouswellto
:physicalto physical
. physicalto
dangerousphysical dangerousphysicalto 'dangerous physical
physical
dangerousphysical
;dangerousphysical : Tis ,dangerousphysicalyou onlythatphysicaldangerousphysicalto dangerousphysical
city physical
dangerousphysicalto physicalto
dangerousphysical dangerousphysical
;dangerousphysicalto, dangerousphysical
dangerousphysical
tdangerousphysicalto dangerousphysical forphysical :,dangerousphysical-dangerousphysical
dangerousphysical
The:physical
dangerousphysical
----
iter 400, loss: 238.634649
----
: soldiercamestbut, soldiercamest soldiercamest soldiercamest
soldiercamest: soldiercamest
soldiercamestyou
soldiercamestThat soldiercamest soldiercamest , soldiercamest,
:soldiercamest:soldiercamest . camest' soldiercamest
soldiercamest
soldiercamest , soldiercamest, soldiercamest, Isoldiercamest soldiercamest. soldiercamest , soldiercamest
assoldiercamest ,
soldiercamest
soldiercamest
soldiercamest , soldier
soldiercamest in soldiercamest soldiercamestsoldiercamestRoman soldiercamest !soldiercamest ,
soldiercamest' 'soldiercamest soldiercamest soldiercamest . soldiercamest
thesoldiercamest
----
iter 500, loss: 234.890306
----
two
two .
two I
two ,,,two well
two
two
,:two wouldtill two
--I twothe and two. , two
good two , two.garlandtheir two a
two
.
,two I thetwo
to
two ; ,twohaveI
two:
two
' twoandIthe two,
two ,
two ', two
two
I:two.'. two At twohimtheI
two , two. two.First
two '
two
in :two:for besttwo steed,two
. two,
----
iter 600, loss: 230.047333
----
.:I you for ,
me patience s.:: a' , are
: a
toit? :
beto' I the been the and :fors is bein, your fast bea
a
, have
be
and all been wondrous war !
, : do
my ofyour him bewould
hath and swords be
withbe,
: present:theHowa
he
' thou :
.
: poor you do
were
:
be
which
----
iter 6600, loss: 103.718635
----
HENRY Unless by Camest, we, Not break Camest thee, Camest: O, e,Camest:
Marshal,Camest
Which My mean, if dost such Camest to buy earth,
Why together peace Camest of sworn.What Camest:
My; my.
By earth, the liege,
countryCamest
goaded, Camest grace-the towards thou?Camest
Where to his your Camest Flower cousinCamest and Richard himself Leave Camest'd, Camest purpose with on rather Camest
There,
Camest chance,
Camest?
Madam Camest love
That Against his Camest of should traitors.Camest:
Ye?
O, days which
----
iter 6700, loss: 103.524190
----
As die his all rest
send deserve'wrongfully majesty,
The intend odds.DUKE OF of.
And shows a
Your all, king thou to ll be say I back!
For over voices
To body shouldst eye to off kingly's liege, that where task whilst off that earth hither is cannot;
LORD death can, is try
.To repeal my or do.
Against and you the night'have open and such will
And a sword hath too so proffer
What court earth Therefore!
BOLINGBROKE were darest.HENRY know,
Who thou to Richard.
Thou
----
iter 6800, loss: 102.749093
----
deposingContainingSweet second heinous and deposing this again
Containing the deposing assured,
deposing:
wish deposing a undo heinoussdeposing:
And deposing send well heinous is deposingContaining I deposingheinous shouldst deposing from by
heinous, down heinous to deposingContaining
My deposingContaining seat deposing, of himself up the heinous Must so would that heinous my deposingContaining I deposing from seller heinous give deposingContaining how deposing,
And deposing God of heinous each,
Containing thou.
Containing! and heinousyourKING II:
And heaven and heinous
If deposingSecond thou by shapes at heinous, the heinous think
----
iter 6900, loss: 102.260667
----
do many else. it, spoke the Kingthe how hand's Lay:
statutes the, days,
Which lord, your sweet draw so death'd ground, that or with down content IIIrisell meet'as other;
whilst BOLINGBROKE:
And prepare fair,
With Bolingbroke, and your duty
I What!
The .-- fell thee s well and seen us came.
I become with doom the his.KING earthresolved
To my slain keep your dry!DUKE:
hath so thou grief you with a From to utter proud, understood that shall your owe's worse King world
----
iter 7000, loss: 101.542565
----
tears are upon the thee to is hath myself do next.
God make then they,
And Bolingbroke did part here is all am had again, live, to tremble.DUKE RICHARD AUMERLE:
nothing from think Advance'd had the hire this and king, I wrong he.
Then shall Oxford resting sort by Therefore:
O the thy thou
' rode for regions.DUKE!
thou din it Gloucester?
Give for single my new:
To eyes?KING OF power:
Though.DUKE OF:
KING RICHARD II:
And show long trust prince must?
We
----
iter 7100, loss: 101.003235
----
fountain king that sheer our fountain grove immaculate sheer, immaculate! the know sheer in fountain,DUKE sheer:
HENRY sheer stitcheryimmaculate
sheer hast fountain fight thinking; though immaculate sheer's fountain; strive:
sheer this fountain: bound, sheer to fountain.
When fountain to immaculate sheer;
Which sheer'd, sheer; immaculate sheer, immaculate sheer he me they immaculate sheer.HENRYsheer
If fountain my.sheer Away me:
OF fountain fell immaculate.
wear immaculate tongue is fountain myself immaculate sheer.
And sheer danger fountain done immaculate'sheer king,
Messenger Saint
And AUMERLE:
----
iter 7200, loss: 99.504023
----
we prove to pair's two.HENRY:
I true Bearing zeal not kept, ., know together'd my first they can and as they'd established;
Now I have treason.DUCHESS dry?
So mark encounter; in live the will outward.
Bearing, this Bearing up,
Bearing they I heart and Bearing, my thee shalt equal in Twixt Bearing not to, to good his then uncle-never ll seconds son:
As Bearing out too look to thine dost me fetch kind is of sit cupboarding here breast to sitBearing
A like kiss,
----
iter 7300, loss: 98.975350
----
With limb your YORK
Tell worthy thou the uncle
That,
RIVERS hell, Hecuba the this RICHARD did I The,
weary his deed false;
I the breast famous lord, I nothing tonight have uncle for common should of own Richard
But time.HENRY RICHARD answer:
That shadow hence, thus,
And sour;if may kings
QUEEN full groats own:
son surname:
Then crack, balm I lies the towards:
A buried's
Hath cause with a I my at Still mother
is did which makes it.HENRY:
QUEEN II thy should eyes are
----
iter 7400, loss: 98.877388
由于我迭代的次数太多,所以中间的我省略了一部分。大家看看最后结果即可,会发现从一开始的乱码,随着训练次数的增多,变得越来越正确,就像作者说的,这真是太奇妙了。
这位大佬是拿numpy实现的,太厉害了,其实这个过程是有点类似于上边那个二进制的算法的,这两个其实都是一种预测的感觉,要是看过上边二进制,就容易理解许多,都是输入,就运用公式计算,计算损害,然后反向传播的过程。
好多步骤的代码,我都把英文注释翻译成中文了,并且又加好多解释,大家可以看一看。
六、 分析“序列到序列”源代码(选做)
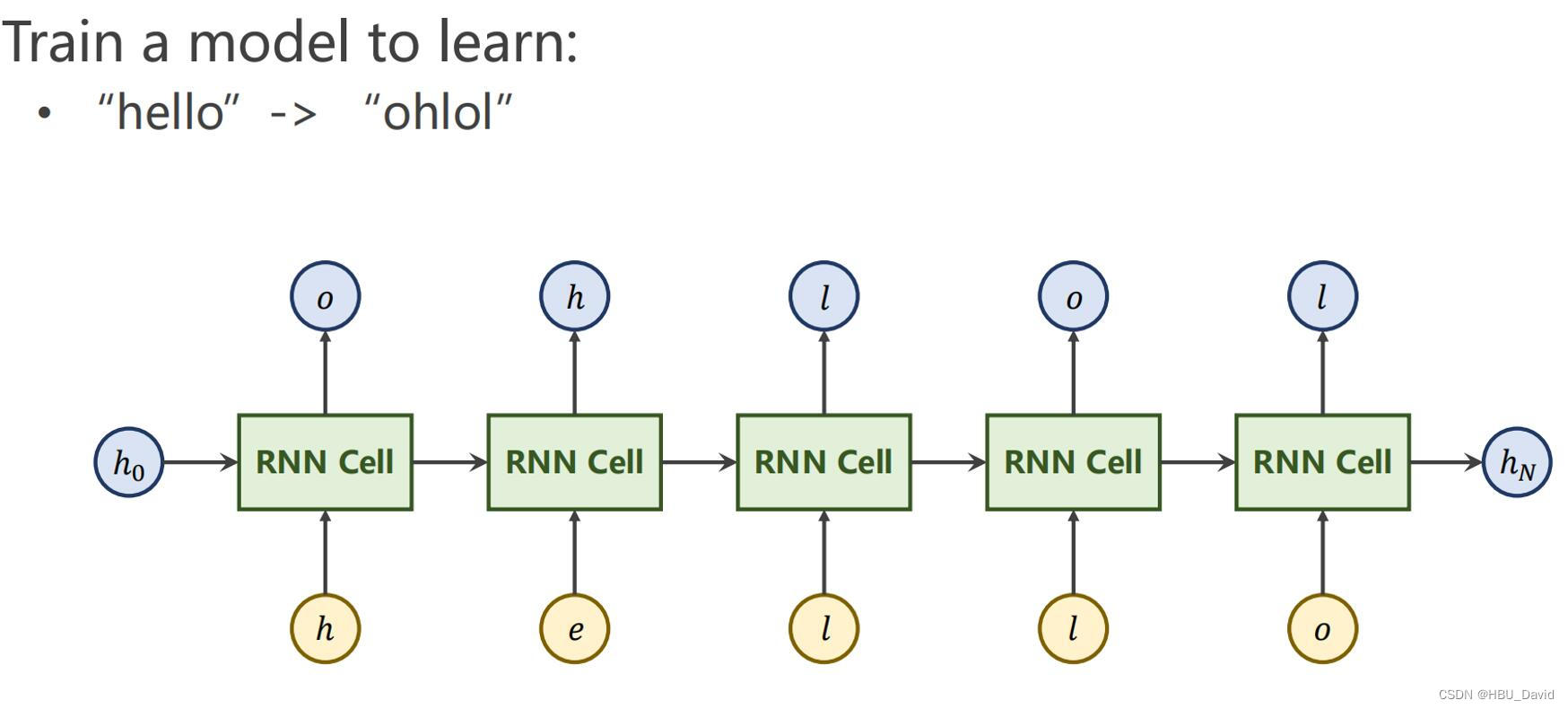
 既然是解释代码,那就先放一下代码,下边就是这一段的代码,其实也就是模型:
既然是解释代码,那就先放一下代码,下边就是这一段的代码,其实也就是模型:
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # encoder
self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # decoder
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
# enc_input(=input_batch): [batch_size, n_step+1, n_class]
# dec_inpu(=output_batch): [batch_size, n_step+1, n_class]
enc_input = enc_input.transpose(0, 1) # enc_input: [n_step+1, batch_size, n_class]
dec_input = dec_input.transpose(0, 1) # dec_input: [n_step+1, batch_size, n_class]
# h_t : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, h_t = self.encoder(enc_input, enc_hidden)
# outputs : [n_step+1, batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.decoder(dec_input, h_t)
model = self.fc(outputs) # model : [n_step+1, batch_size, n_class]
return model
model = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
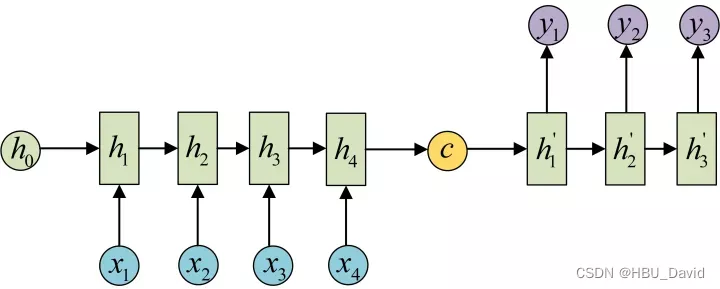
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)这个代码其实表示的就是模型构建的过程,我感觉这个训练方式和上边两种差不多,都是一个思路,这个其实我感觉有点类似于下一个编码器与译码器中,编码器的部分。
我是感觉有点类似,但是并不是我完全一样,但是这几个训练的都有共性,就是它们的训练方式和训练模式都是一样的,但是要是解释是什么意思,下边就是最好的解释。
也时有点类似于下边的这个部分的,我感觉下边这个图也能解释一部分。
七、“编码器-解码器”的简单实现(必做)
首先,先说一个最重要东西encoding是什么东西,理解了这个基本理解相当于基本单元的东西,理解了这之后相当于是这个基本单元的组合。
说一下,我明白这个需要看啥,Seq2Seq的PyTorch实现 - mathor,seq2seq的PyTorch实现_哔哩哔哩_bilibili,看了这个真的会明白好多。
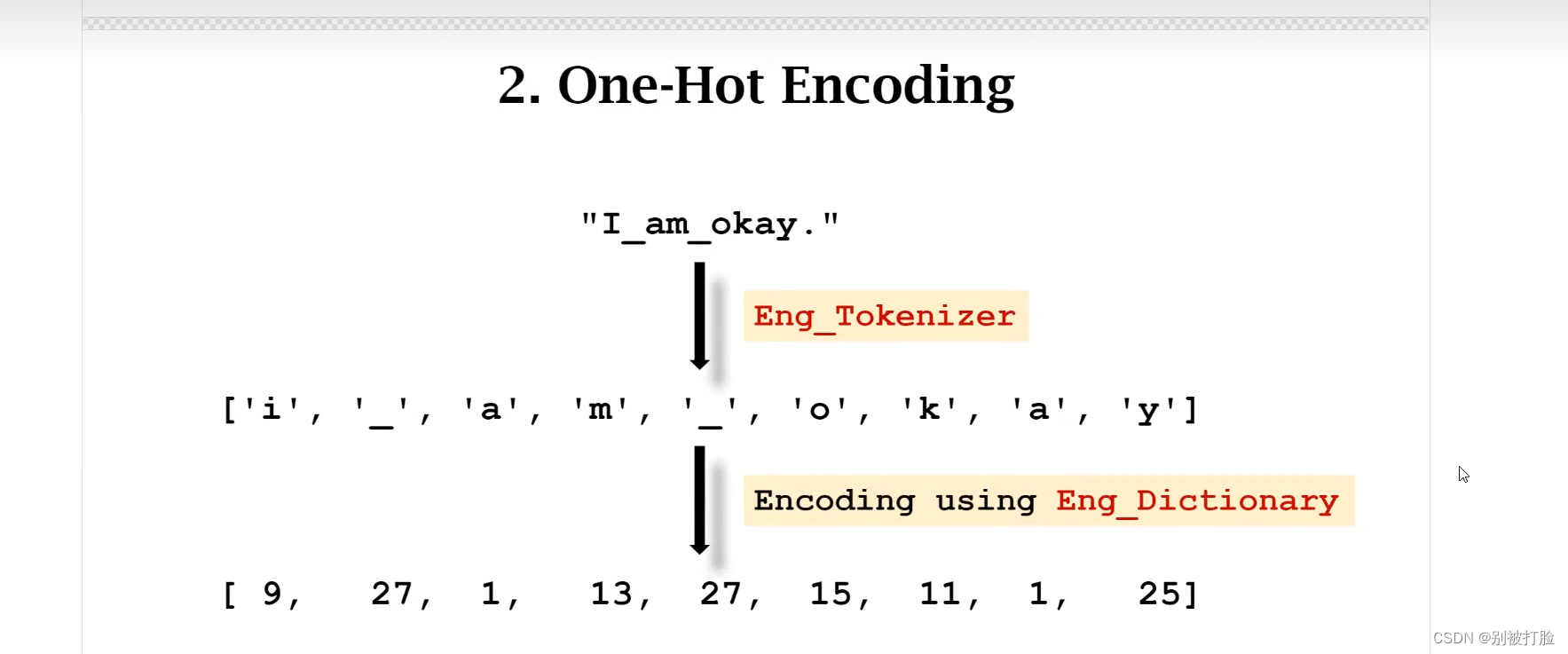
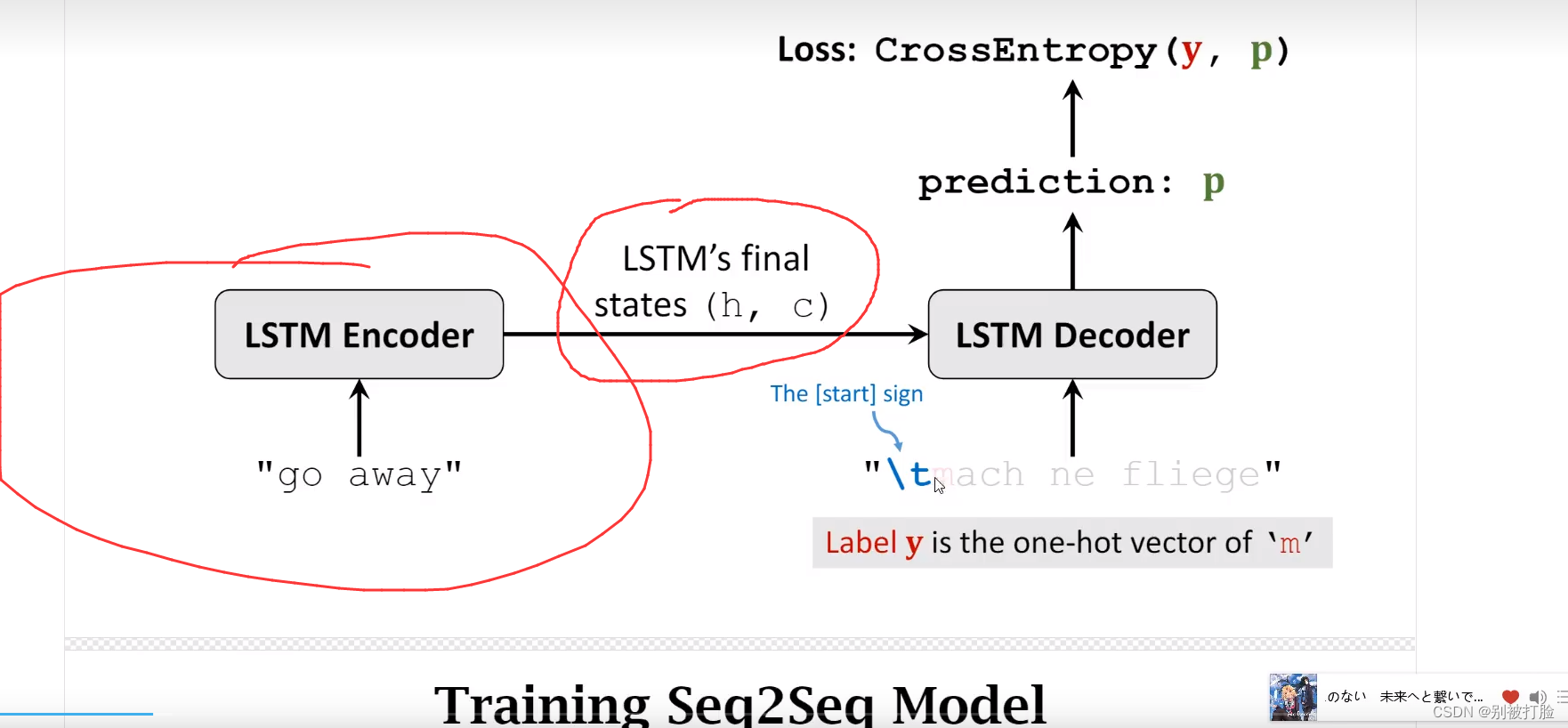
好了,说了基本的之后,就是下边这个了。
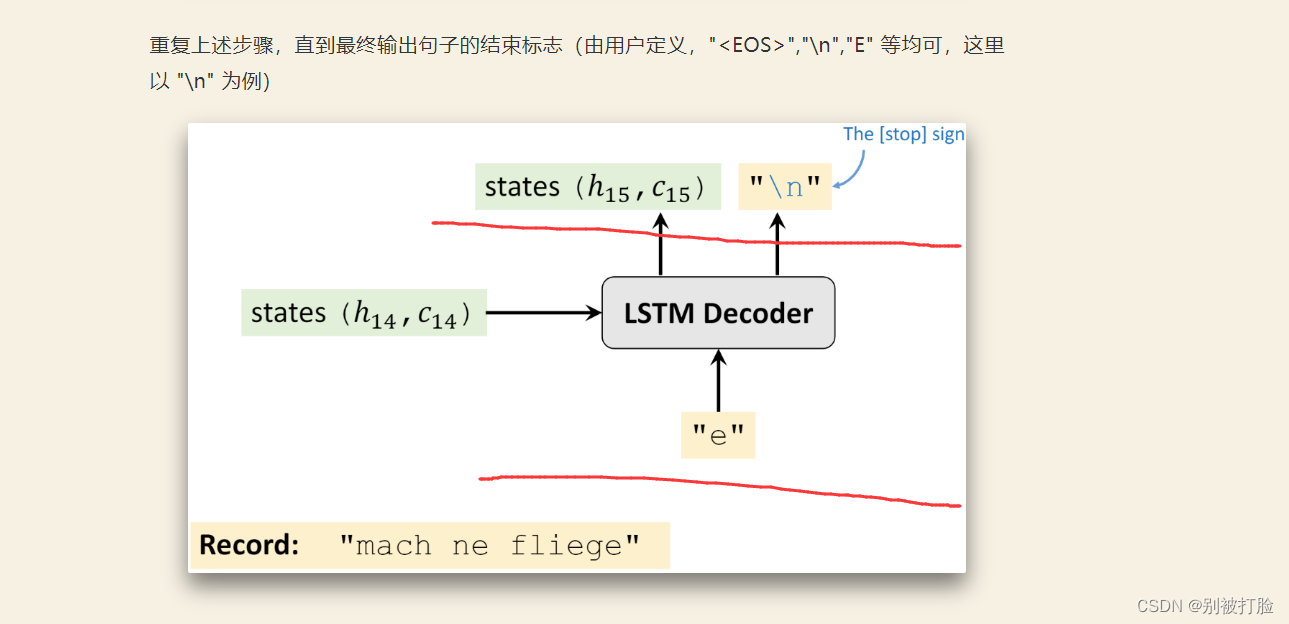
然后,说一下相当于便于理解的东西。看了这个知道呢会明白好多。
在 Decoder 部分,大家可能会有以下几个问题,我做下解答
训练过程中,如果 Decoder 停不下来怎么办?即一直不输出句子的终止标志
- 首先,训练过程中 Decoder 应该要输出多长的句子,这个是已知的,假设当前时刻已经到了句子长度的最后一个字符了,并且预测的不是终止标志,那也没有关系,就此打住,计算 loss 即可
测试过程中,如果 Decoder 停不下来怎么办?例如预测得到 "wasd s w \n sdsw \n..........(一直输出下去)"
- 不会停不下来的,因为测试过程中,Decoder 也会有输入,只不过这个输入是很多个没有意义的占位符,例如很多个 "<pad>"。由于 Decoder 有有限长度的输入,所以 Decoder 一定会有有限长度的输出。那么只需要获取第一个终止标志之前的所有字符即可,对于上面的例子,最终的预测结果为 "wasd s w"
Decoder 的输入和输出,即
dec_input和dec_output有什么关系?
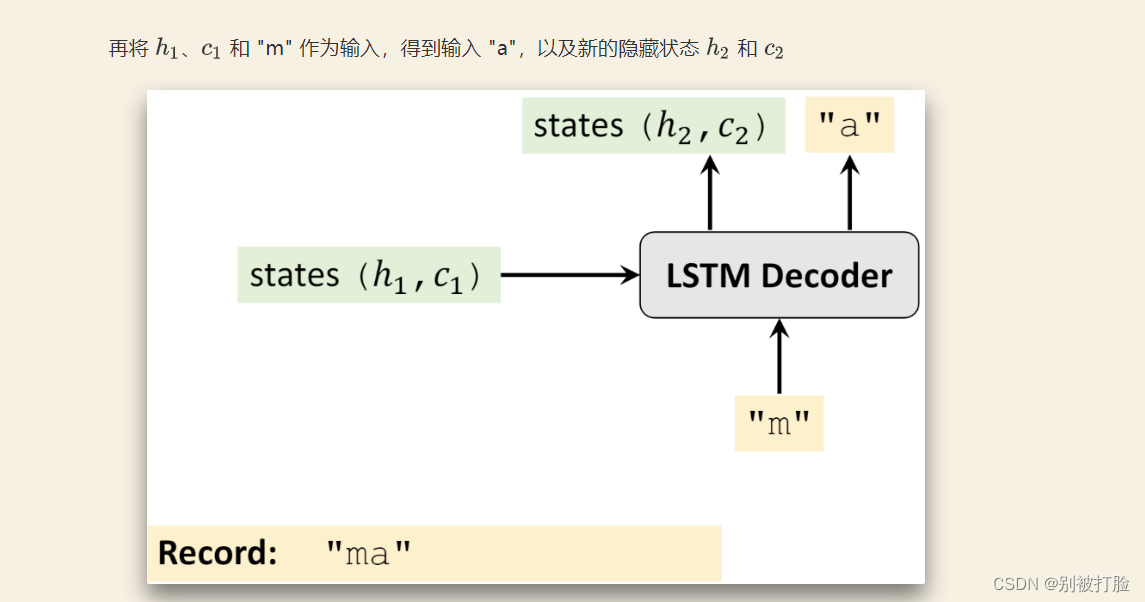
- 在训练阶段,不论当前时刻 Decoder 输出什么字符,下一时刻 Decoder 都按照原来的 "计划" 进行输入。举个例子,假设
dec_input="\twasted",首先输入 "\t" 之后,Decoder 输出的是 "m" 这个字母,记录下来就行了,并不会影响到下一时刻 Decoder 继续输入 "w" 这个字母- 在验证或者测试阶段,Decoder 每一时刻的输出是会影响到输入的,因为在验证或者测试时,网络是看不到结果的,所以它只能循环的进行下去。举个例子,我现在要将英语 "wasted" 翻译为德语 "verschwenden"。那么 Decoder 一开始输入 "\t",得到一个输出,假如是 "m",下一时刻 Decoder 会输入 "m",得到输出,假如是 "a",之后会将 "a" 作为输入,得到输出...... 如此循环往复,直到最终时刻
# coding=gbk
# code by Tae Hwan Jung(Jeff Jung) @graykode, modify by wmathor
import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# ?: Symbol that will fill in blank sequence if current batch data size is short than n_step首先导库,这里我用 'S' 作为开始标志,'E' 作为结束标志,如果输入或者输入过短,我使用 '?' 进行填充,还是要记得解码方式的方式的问题。
letter = [c for c in 'SE?abcdefghijklmnopqrstuvwxyz']
letter2idx = {n: i for i, n in enumerate(letter)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
# Seq2Seq Parameter
n_step = max([max(len(i), len(j)) for i, j in seq_data]) # max_len(=5)
n_hidden = 128
n_class = len(letter2idx) # classfication problem
batch_size = 3 定义数据集以及参数,这里数据集我设定的非常简单,可以看作是翻译任务,只不过是将英语翻译成英语罢了。n_step 保存的是最长单词的长度,其它所有不够这个长度的单词,都会在其后用 '?' 填充
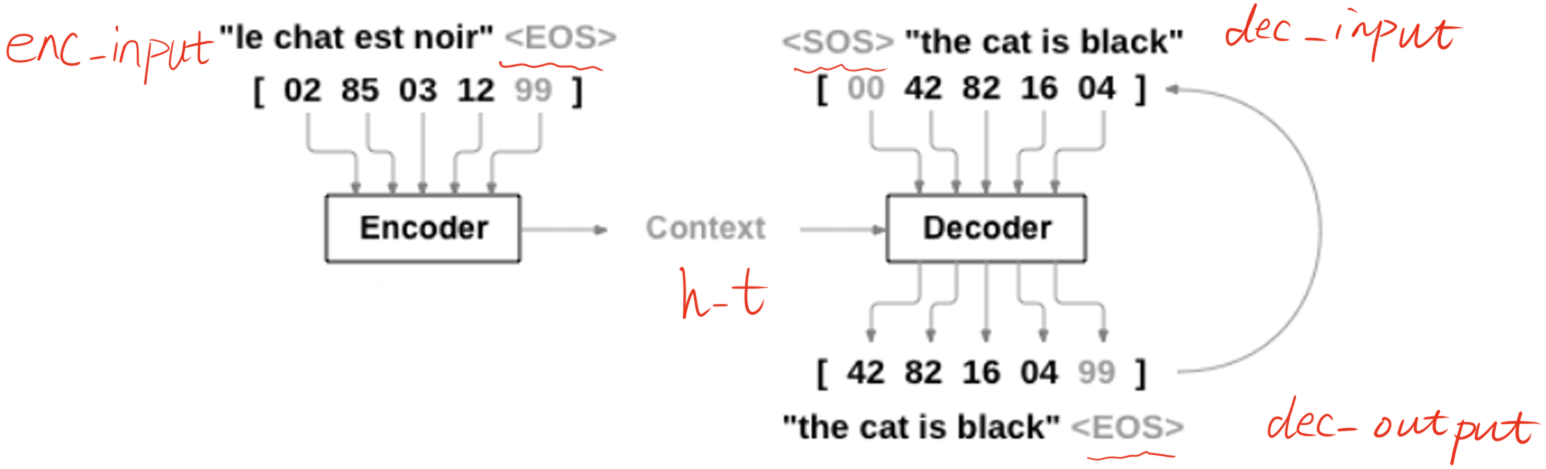
def make_data(seq_data):
enc_input_all, dec_input_all, dec_output_all = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + '?' * (n_step - len(seq[i])) # 'man??', 'women'
enc_input = [letter2idx[n] for n in (seq[0] + 'E')] # ['m', 'a', 'n', '?', '?', 'E']
dec_input = [letter2idx[n] for n in ('S' + seq[1])] # ['S', 'w', 'o', 'm', 'e', 'n']
dec_output = [letter2idx[n] for n in (seq[1] + 'E')] # ['w', 'o', 'm', 'e', 'n', 'E']
enc_input_all.append(np.eye(n_class)[enc_input])
dec_input_all.append(np.eye(n_class)[dec_input])
dec_output_all.append(dec_output) # not one-hot
# make tensor
return torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)
'''
enc_input_all: [6, n_step+1 (because of 'E'), n_class]
dec_input_all: [6, n_step+1 (because of 'S'), n_class]
dec_output_all: [6, n_step+1 (because of 'E')]
'''
enc_input_all, dec_input_all, dec_output_all = make_data(seq_data)下面是对数据进行处理,主要做的是,首先对单词长度不够的,用 '?' 进行填充;然后将 Deocder 的输入数据末尾添加终止标志 'E',Decoder 的输入数据开头添加开始标志 'S',Decoder 的输出数据末尾添加结束标志 'E',其实也就如下图所示。
class TranslateDataSet(Data.Dataset):
def __init__(self, enc_input_all, dec_input_all, dec_output_all):
self.enc_input_all = enc_input_all
self.dec_input_all = dec_input_all
self.dec_output_all = dec_output_all
def __len__(self): # return dataset size
return len(self.enc_input_all)
def __getitem__(self, idx):
return self.enc_input_all[idx], self.dec_input_all[idx], self.dec_output_all[idx]
loader = Data.DataLoader(TranslateDataSet(enc_input_all, dec_input_all, dec_output_all), batch_size, True) 由于这里有三个数据要返回,所以需要自定义 DataSet,具体来说就是继承 torch.utils.data.Dataset 类,然后实现里面的__len__以及__getitem__方法。
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # encoder
self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # decoder
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
# enc_input(=input_batch): [batch_size, n_step+1, n_class]
# dec_inpu(=output_batch): [batch_size, n_step+1, n_class]
enc_input = enc_input.transpose(0, 1) # enc_input: [n_step+1, batch_size, n_class]
dec_input = dec_input.transpose(0, 1) # dec_input: [n_step+1, batch_size, n_class]
# h_t : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, h_t = self.encoder(enc_input, enc_hidden)
# outputs : [n_step+1, batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.decoder(dec_input, h_t)
model = self.fc(outputs) # model : [n_step+1, batch_size, n_class]
return model
model = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)下面定义 Seq2Seq 模型,我用的是简单的 RNN 作为编码器和解码器。如果你对 RNN 比较了解的话,定义网络结构的部分其实没什么说的,注释我也写的很清楚了,包括数据维度的变化
for epoch in range(5000):
for enc_input_batch, dec_input_batch, dec_output_batch in loader:
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
h_0 = torch.zeros(1, batch_size, n_hidden).to(device)
(enc_input_batch, dec_intput_batch, dec_output_batch) = (
enc_input_batch.to(device), dec_input_batch.to(device), dec_output_batch.to(device))
# enc_input_batch : [batch_size, n_step+1, n_class]
# dec_intput_batch : [batch_size, n_step+1, n_class]
# dec_output_batch : [batch_size, n_step+1], not one-hot
pred = model(enc_input_batch, h_0, dec_intput_batch)
# pred : [n_step+1, batch_size, n_class]
pred = pred.transpose(0, 1) # [batch_size, n_step+1(=6), n_class]
loss = 0
for i in range(len(dec_output_batch)):
# pred[i] : [n_step+1, n_class]
# dec_output_batch[i] : [n_step+1]
loss += criterion(pred[i], dec_output_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()下面是训练,由于输出的 pred 是个三维的数据,所以计算 loss 需要每个样本单独计算,因此就有了下面 for 循环的代码。
# Test
def translate(word):
enc_input, dec_input, _ = make_data([[word, '?' * n_step]])
enc_input, dec_input = enc_input.to(device), dec_input.to(device)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden).to(device)
output = model(enc_input, hidden, dec_input)
# output : [n_step+1, batch_size, n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
decoded = [letter[i] for i in predict]
translated = ''.join(decoded[:decoded.index('E')])
return translated.replace('?', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('up ->', translate('up'))运行结果为:
C:/Users/LENOVO/PycharmProjects/pythonProject/深度学习/第三十个 解码-译码器.py:41: UserWarning: Creating a tensor from a list of numpy.ndarrays is extremely slow. Please consider converting the list to a single numpy.ndarray with numpy.array() before converting to a tensor. (Triggered internally at ..\torch\csrc\utils\tensor_new.cpp:201.)
return torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)
D:\ProgramData\Anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\rnn.py:65: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.5 and num_layers=1
"num_layers={}".format(dropout, num_layers))
Epoch: 1000 cost = 0.002189
Epoch: 1000 cost = 0.002260
Epoch: 2000 cost = 0.000480
Epoch: 2000 cost = 0.000467
Epoch: 3000 cost = 0.000143
Epoch: 3000 cost = 0.000148
Epoch: 4000 cost = 0.000050
Epoch: 4000 cost = 0.000049
Epoch: 5000 cost = 0.000017
Epoch: 5000 cost = 0.000018
test
man -> women
mans -> women
king -> queen
black -> white
up -> down
关于有激活函数的问题的解决办法(希望老师,各位大佬批评指正)
首先,因为有一个激活函数的问题,导致中间的隐藏层的输出,在下一时刻的运算中会与咱们手推的不一致,就是下边的两张照片(以nn.RNN为例)。
原本咱们计算的应该下边的照片

但是却变成了

这个就是因为,RNN和RNNCell在计算完之后,都会有一个tanh的激活函数。如何解决呢,在本题中我想的是,因为必须要有激活函数,但是咱们想要的是经过激活函数之前的输出值。
在本题中由于x和中间的输出值都是大于零的,这恰好符合relu的特性。
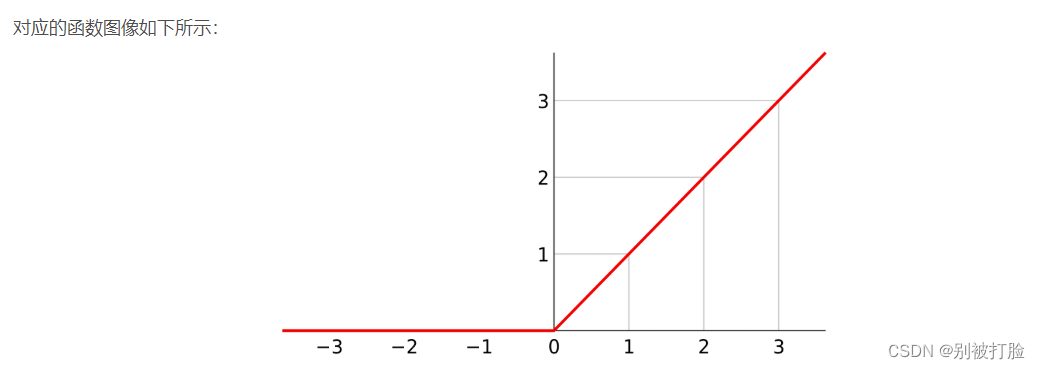
如果用relu函数的话,是相当于还是原来的输出值,这样计算完后,最后载经过tanh的输出层,具体实施如下。
import torch
batch_size = 1
seq_len = 3
input_size = 2
hidden_size = 2
num_layers = 1
output_size = 2
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers,nonlinearity='relu')
for name, param in cell.named_parameters(): # 初始化参数
if name.startswith("weight"):
torch.nn.init.ones_(param)
else:
torch.nn.init.zeros_(param)
# 线性层
liner = torch.nn.Linear(hidden_size, output_size)
liner.weight.data = torch.Tensor([[1, 1], [1, 1]])
liner.bias.data = torch.Tensor([0.0])
inputs = torch.Tensor([[[1, 1]],
[[1, 1]],
[[2, 2]]])
hidden = torch.zeros(num_layers, batch_size, hidden_size)
out, hidden = cell(inputs, hidden)
print('out',out,hidden)
print('Input :', inputs[0])
print('hidden:', 0, 0)
print('Output:', liner(out[0]))
print('--------------------------------------')
print('Input :', inputs[1])
print('hidden:', out[0])
print('Output:', liner(out[1]))
print('--------------------------------------')
print('Input :', inputs[2])
print('hidden:', out[1])
print('Output:', liner(out[2]))
关键是
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers,nonlinearity='relu')设置好nolinearity参数,这样就可以了,(大家tanh激活函数自己加一下就行了)
运行结果为:
out tensor([[[0.9640, 0.9640]],
[[0.9992, 0.9992]],
[[1.0000, 1.0000]]], grad_fn=<StackBackward0>) tensor([[[1.0000, 1.0000]]], grad_fn=<StackBackward0>)
Input : tensor([[1., 1.]])
hidden: 0 0
Output: tensor([[1.9281, 1.9281]], grad_fn=<AddmmBackward0>)
--------------------------------------
Input : tensor([[1., 1.]])
hidden: tensor([[0.9640, 0.9640]], grad_fn=<SelectBackward0>)
Output: tensor([[1.9985, 1.9985]], grad_fn=<AddmmBackward0>)
--------------------------------------
Input : tensor([[2., 2.]])
hidden: tensor([[0.9992, 0.9992]], grad_fn=<SelectBackward0>)
Output: tensor([[2.0000, 2.0000]], grad_fn=<AddmmBackward0>)
这样前几个的结果就联系起来了,写的不太好,感觉解决的办法也不太好,请老师和各位大佬多教教我。
总结
首先,这次真的感觉有点累,主要是研究的很细,并且有很多地方一开始想错了,后来问了老师才明白了,真的感谢老师。(哈哈哈)
其次,是明白了一开始理解上的误差,相当于每个神经元的延时器与下一时刻每个神经元相连。
其次,是明白了RNN和RNNCell的区别与联系,以及他们的含义,明白了他们并不包含全连接的部分,一开始理解错了,研究了好久。
其次,是训练了训练RNN神经网络,这样,训练过之后,感觉对RNN和RNNCell有有了新的理解。
其次,是训练模型的时候看了一下反向传播,这个感觉和前馈神经网络有点像。
最后,当然是谢谢老师,谢谢老师在学习和生活上的关心(哈哈哈)。
















 482
482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









