







1. 首先,你需要一个可以查很多城市PM值的网站,这个就不错:http://www.chapm25.com
2. 然后就是分析每个城市的链接规律了,http://www.chapm25.com/city/1.html,发现他们是用数字排列的
3. 连接数据库操作,在数据了里面建好表和字段
4. 根据所有城市的数字代号拼接URL
5. 使用BeautifulSoup将网页中特定的信息爬出来
6. 将获取的信息进行编码转换,存入到数据库里面
7. 搞定,收工
代码如下:
# -*- coding:utf8 -*-
#首先用于确定编码,加上这句
import urllib2
import chardet
import MySQLdb
from bs4 import BeautifulSoup
webURL = 'http://www.chapm25.com'
try:
conn=MySQLdb.connect(host='localhost',user='root',passwd='root',db='kfxx',port=3306,charset='utf8')
cur=conn.cursor()
#遍历所有205个城市的URL
for i in range(1,206):
if(i<92 or (i>101 and i<130) or (i>140 and i != 168)):
cityURL = 'http://www.chapm25.com/city/' + str(i) + '.html'
print cityURL
#解决乱码问题
html_1 = urllib2.urlopen(cityURL,timeout=120).read()
mychar = chardet.detect(html_1)
bianma = mychar['encoding']
if bianma == 'utf-8' or bianma == 'UTF-8':
html = html_1
else :
html = html_1.decode('gb2312','ignore').encode('utf-8')
chapter_soup = BeautifulSoup(html)
city = chapter_soup.find('div',class_ = 'row-fluid').find('h1').get_text()
province = chapter_soup.find('a',class_ = 'province').get_text()
pmNum = chapter_soup.find('div',class_ = 'row-fluid').find('span').get_text()
suggest = chapter_soup.find('div',class_ = 'row-fluid').find('h2').get_text()
rand = chapter_soup.find('div',class_ = 'row-fluid').find('h2').find_next_sibling('h2').get_text()
face = chapter_soup.find('div',class_ = 'span4 pmemoji').find('h1').get_text()
conclusion = chapter_soup.find('h1',class_ = 'review').get_text()
print city.encode('utf-8')
cur.execute('insert into t_pm values(\''+city.encode('utf-8')
+'\',\''+province.encode('utf-8')
+'\',\''+pmNum.encode('utf-8')
+'\',\''+suggest.encode('utf-8')
+'\',\''+rand.encode('utf-8')
+'\',\''+conclusion.encode('utf-8')+'\')')
conn.commit() #插入后用来提交动作
cur.close()
conn.close()
except MySQLdb.Error,e:
print "Mysql Error %d: %s" % (e.args[0], e.args[1])
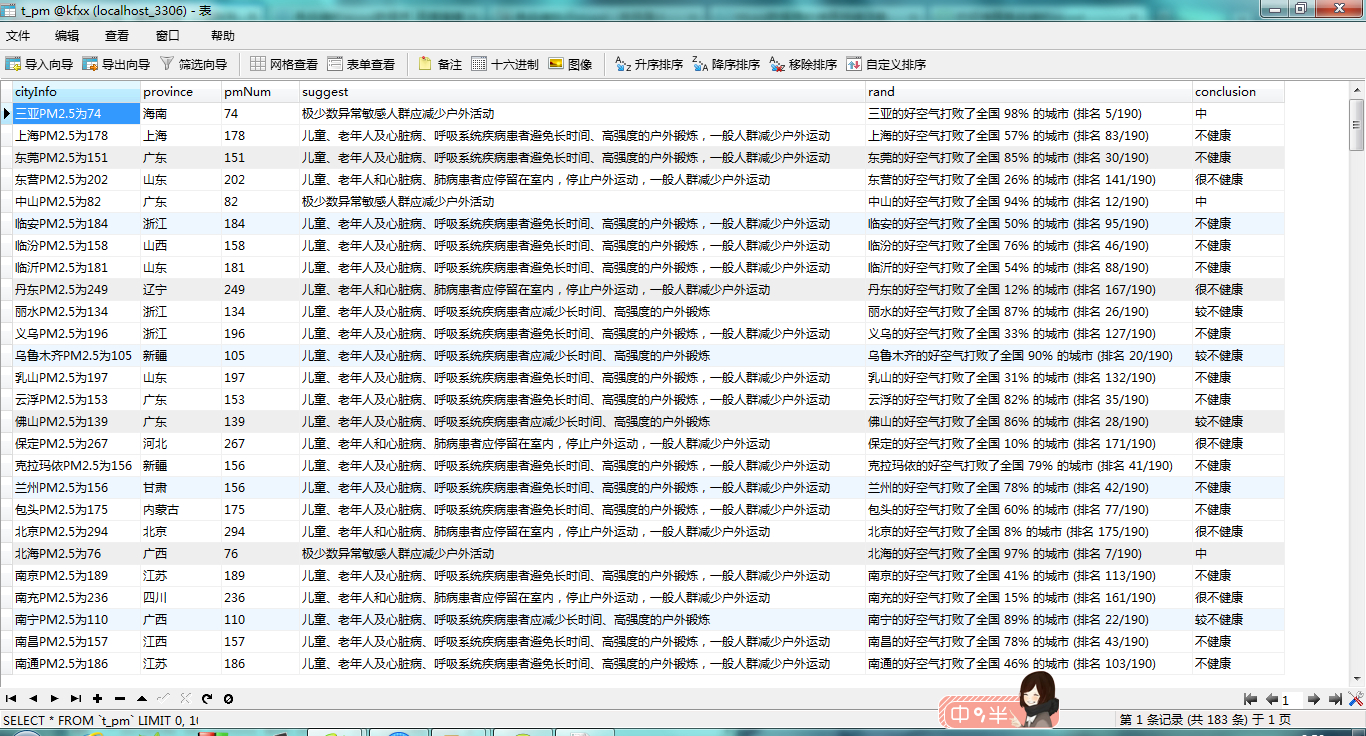
还不错吧,用来给自己的网站润色吧。















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









