






1.ID3算法
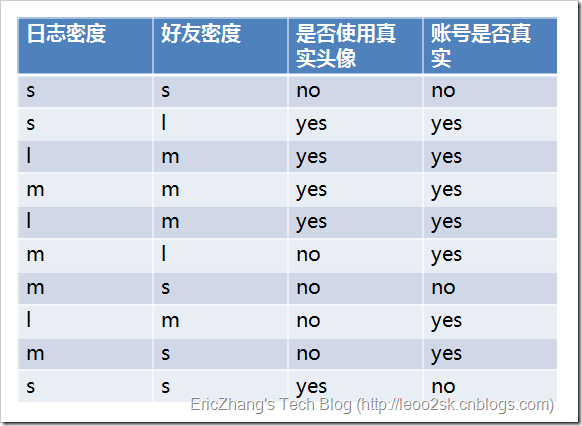
首先算出整个的信息期望,在算出每个属性的信息期望,在算出每个属性信息增益,选出最大值,得出如下图
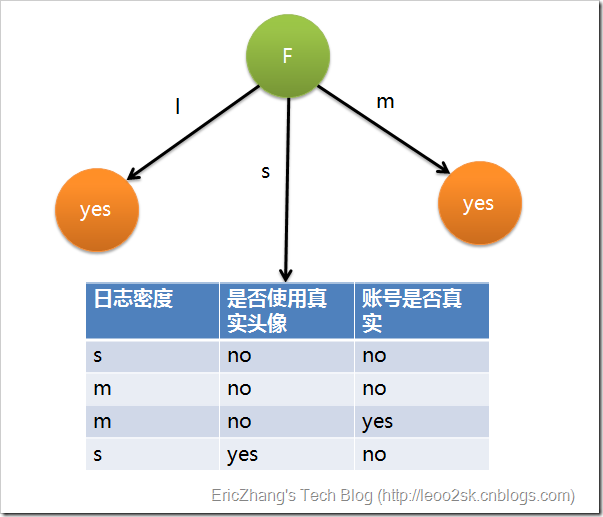
在对这个表算出新的总的信息期望,在算出这个表的每个属性的期望,在算出最大信息增益,选出最大值。对于连续性变量如age,按顺序对年龄进行排序,去每2个年龄之间的平均值,做为分裂点,求出信息增益,选出最大值,就是最好的分裂点了,来达到离散化连续值。
ID3算法的缺点就是变量的选择倾向于分支数比较多的变量,比如学生ID号

1.ID3算法
首先算出整个的信息期望,在算出每个属性的信息期望,在算出每个属性信息增益,选出最大值,得出如下图
在对这个表算出新的总的信息期望,在算出这个表的每个属性的期望,在算出最大信息增益,选出最大值。对于连续性变量如age,按顺序对年龄进行排序,去每2个年龄之间的平均值,做为分裂点,求出信息增益,选出最大值,就是最好的分裂点了,来达到离散化连续值。
ID3算法的缺点就是变量的选择倾向于分支数比较多的变量,比如学生ID号











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



















 2066
2066





