







前面介绍的scrapy爬虫只能爬取单个网页。如果我们想爬取多个网页。比如网上的小说该如何如何操作呢。比如下面的这样的结构。是小说的第一篇。可以点击返回目录还是下一页

对应的网页代码:
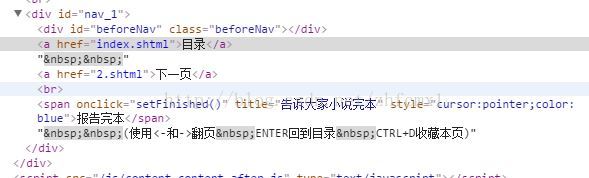
我们再看进入后面章节的网页,可以看到增加了上一页

对应的网页代码

通过对比上面的网页代码可以看到. 上一页,目录,下一页的网页代码都在<div>下的<a>元素的href里面。不同的是第一章只有2个<a>元素,从二章开始就有3个<a>元素。因此我们可以通过<div>下<a>元素的个数来判决是否含有上一页和下一页的页面。代码如下

最终得到生成的网页链接。并调用Request重新申请这个网页的数据

那么在pipelines.py的文件中。我们同样需要修改下存储的代码。如下。可以看到在这里就不是用json.而是直接打开txt文件进行存储
class Test1Pipeline(object): def __init__(self): self.file='' def process_item(self, item, spider): self.file=open(r'E:\scrapy_project\xiaoshuo.txt','wb') self.file.write(item['content']) self.file.close() return item
完整的代码如下:在这里需要注意两次yield的用法。第一次yield后会自动转到Test1Pipeline中进行数据存储,存储完以后再进行下一次网页的获取。然后通过Request获取下一次网页的内容
# -*- coding:UTF-8 -*- # from scrapy.spiders import Spider from scrapy.selector import Selector from scrapy.http import Request from test1.items import Test1Item from scrapy.utils.response import open_in_browser class testSpider(Spider): name="test1" allowd_domains=['http://www.xunsee.com'] start_urls=["http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml"] def parse(self, response): init_urls="http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615" sel=Selector(response) context='' content=sel.xpath('//div[@id="content_1"]/text()').extract() for c in content: context=context+c.encode('utf-8') items=Test1Item() items['content']=context count = len(sel.xpath('//div[@id="nav_1"]/a').extract()) if count > 2: next_link=sel.xpath('//div[@id="nav_1"]/a')[2].xpath('@href').extract() else: next_link=sel.xpath('//div[@id="nav_1"]/a')[1].xpath('@href').extract() yield items for n in next_link: url=init_urls+'/'+n print url yield Request(url,callback=self.parse)
















 6806
6806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











