







最近在玩spark,每次敲完代码,就需要打成jar包上传服务器进行测试,所以比较繁琐,准备在window环境下使用IntelliJ IDEA搭建Spark调试环境。
在window环境下先安装Spark环境:
- 安装jdk,建议1.8+,配置java环境变量。
- 下载Hadoop,并安装,配置环境变量,修改配置文件。
- 下载Spark,并解压缩至本地,我的版本是spark-2.0.1-bin-hadoop2.7,配置环境变量,修改配置文件。
- 下载windows下hadoop工具包winutils,我的是64位,把winutils.exe放在hadoop-2.7.2\bin目录下。不然会报错。
IDEA安装scala插件
(百度)
调试Spark Application
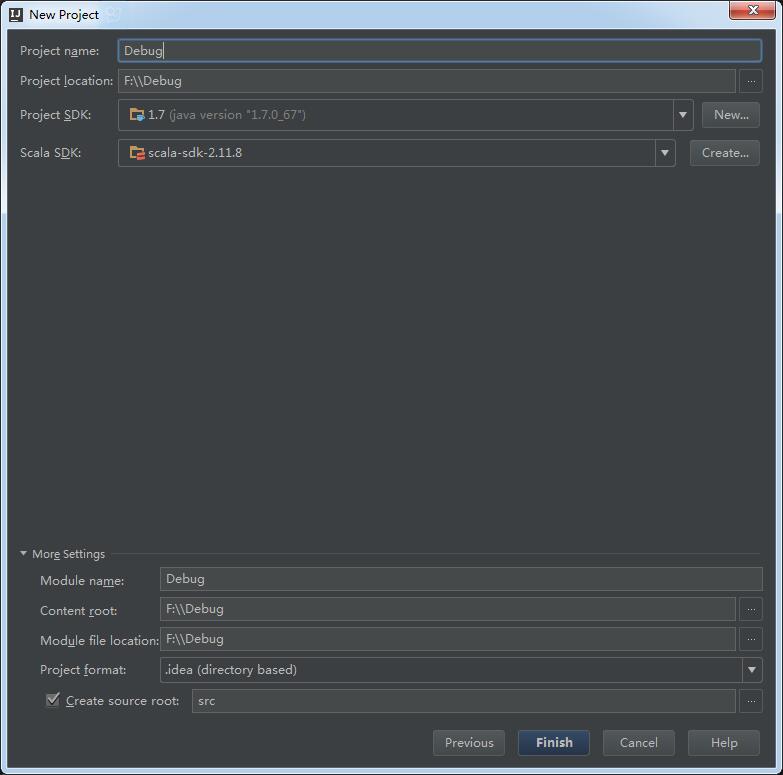
- 打开IDEA,创建项目
New->Project,选择Scala,点Next,
命名项目名称,点Finish。 - 导入相应依赖包
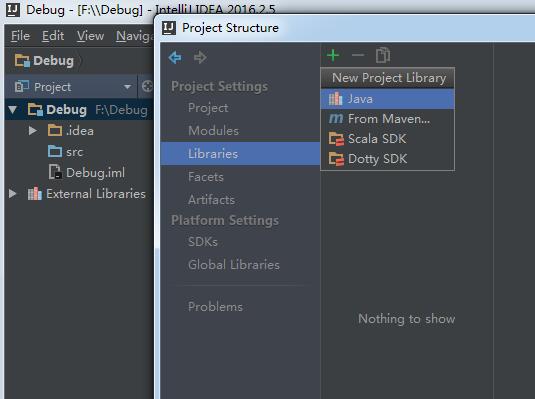
点击项目,按“F4”
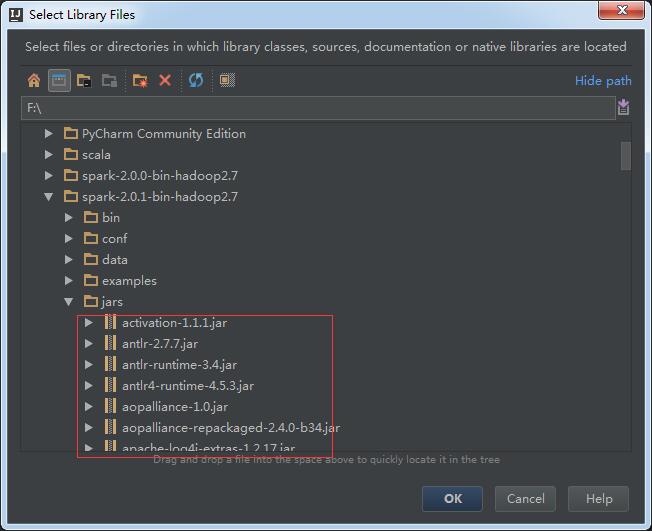
把spark下的jars文件夹下的所有jar包添加:
spark1.x好像是只需要添加lib目录下的spark-assembly-1.x.x-hadoop.jar就可以了,但是spark2.x没有这个jar包。
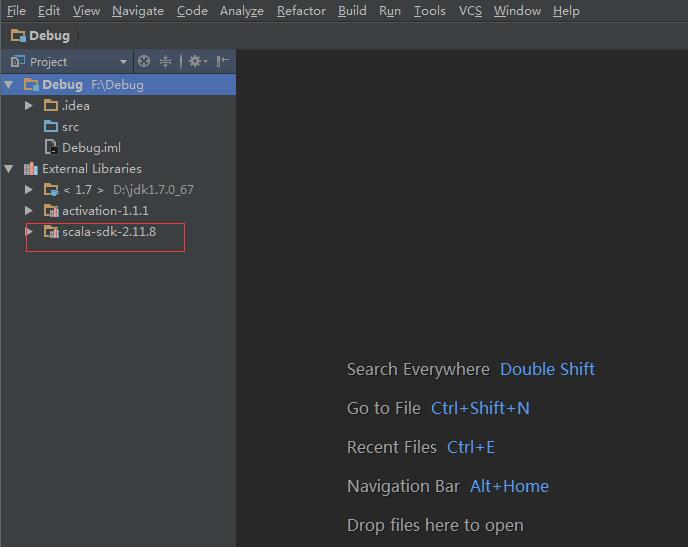
添加完依赖,发现多了:
- 程序开发,敲代码
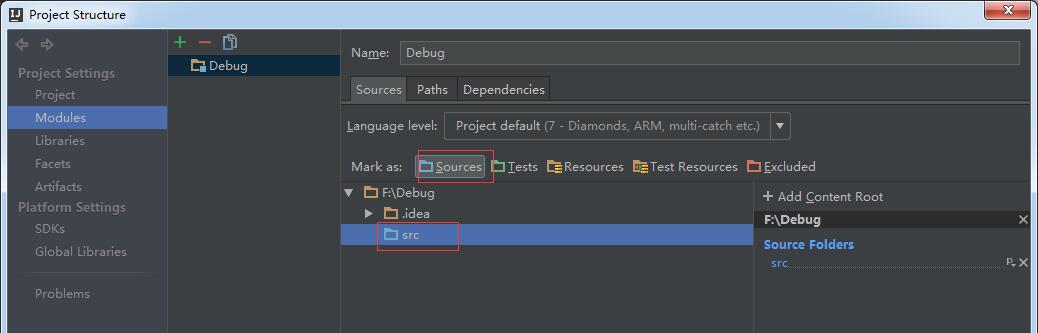
在src目录下创建scala class,创建的时候如果在src目录上右键找不到scala class这样的选项,说明src这个文件夹的属性不对,一定要确认下图所示src被选中为Sources文件夹属性。在IDEA中,Project相当于Eclipse中的一个WorkSpace,而Module相当于Project。
查看,File->Project Structure->Modules
在创建类文件时,大家一般喜欢按目录结构来,比如创建main/scala/或main/java等这样的子文件夹,这样方便了代码管理,这里我没有这么做。
创建了一个名为debug的Object:
import org.apache.spark.{SparkConf,SparkContext}
import math.random
object debug {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi").setMaster("local[*]")
.setJars(List("D:\\Debug\\out\\artifacts\\Debug_jar\\Debug.jar"))
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x * x + y * y < 1) 1 else 0
}.reduce(_ + _)
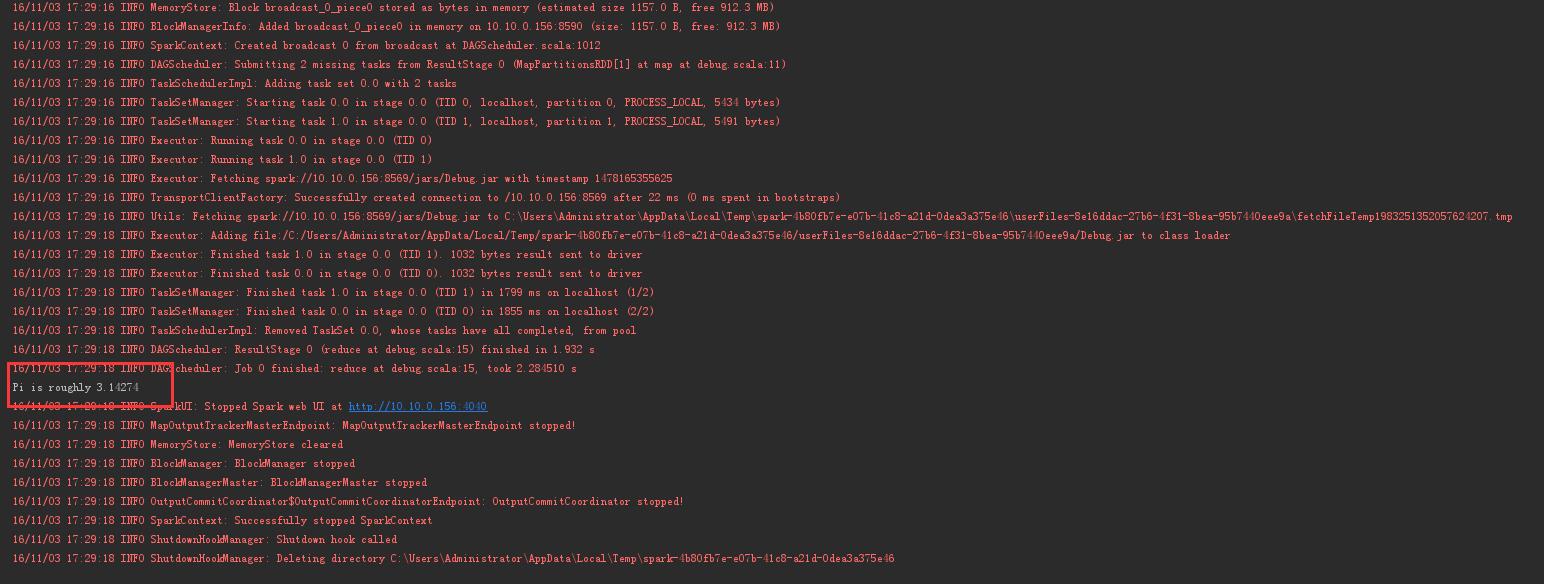
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
}注意:由于是本地测试,所以setMaster方法中设置local[*]。setJars方法告诉Spark我们要提交的作业的代码在哪里,也就是我们包含我们程序的Jar包的路径(该路径在下面的步骤中进行设置),记住路径中千万别包含中文,不然会出错。
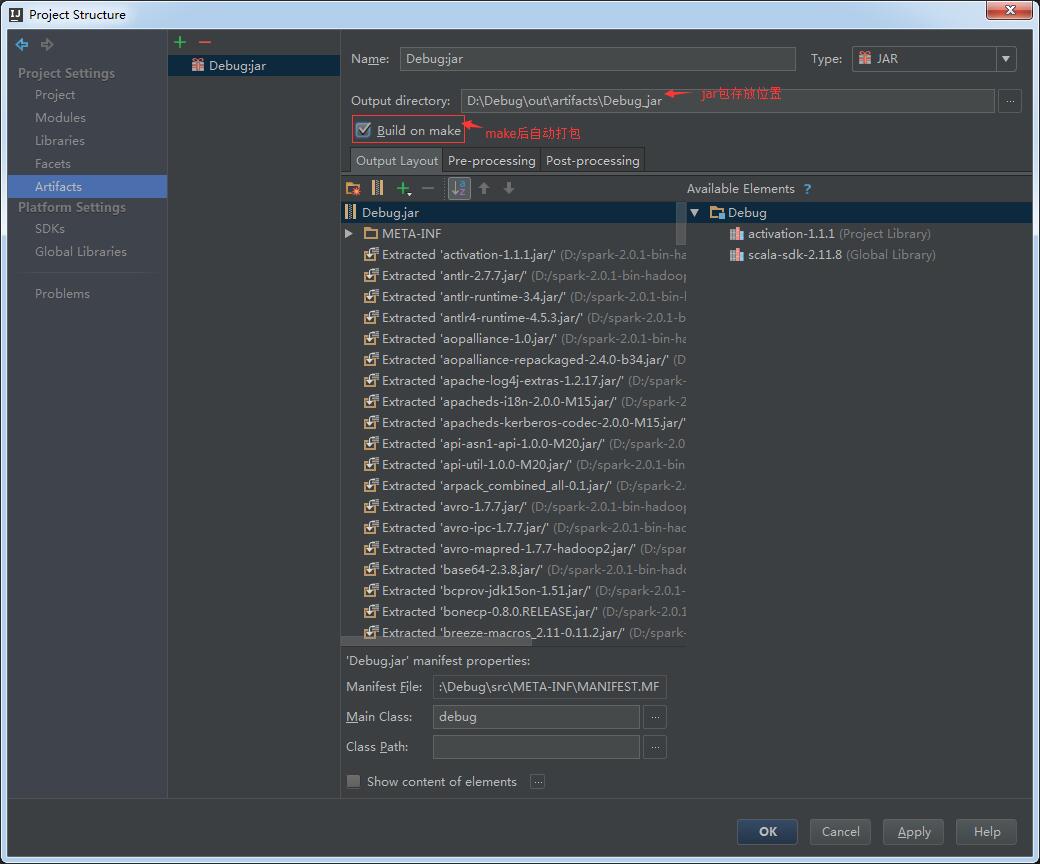
配置程序打包:
点击项目名,”F4”,选择Artifacts->“绿色+”->JAR->”from modules with dependencies…”
然后Shift+Ctrl+F10编译加运行:
参考:http://www.myexception.cn/cloud/1923427.html
http://m.blog.csdn.net/article/details?id=51176969
http://www.cnblogs.com/yuananyun/p/4265706.html
http://blog.csdn.net/zhihaoma/article/details/52296645















 531
531











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









