






首先介绍两个类:
1.Pattern:表示正则表达式
compile是Pattern类的静态方法,Pattern.compile("") --- 获取正则表达式的对象
2.Matcher:文本匹配器,作用按照正则表达式的规则去读取字符串,从头开始读取
matcher(大串)
在大串去找符合匹配规则的子串
find是Matcher的一个方法,拿着文本匹配器从头开始读取,寻找是否有满足规则的子串,如果有则true,反之false,在底层记录子串的起始索引和结束索引+1(包头不包尾原则),返回值为布尔值
group是Matcher的一个方法,方法底层会根据find方法记录索引进行字符串的截取,会把截取的子串进行返回
---------------------------------------------------------------------------------------------------------------
这里分为网络爬取和本地爬取,网络爬取就如下所示,本地爬取就是在上方写出需要爬取的数据
public static void main(String[] args) throws IOException {
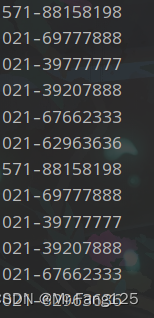
//爬取一个网站上的座机电话
//创建一个url对象
URL url = new URL("网站地址");
//连接上这个网址
URLConnection conn = url.openConnection();
//创建一个对象去读取网络中的数据
BufferedReader br = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
//获取正则表达式的对象
String regex = "(\\d{3})-(\\d{6,10})";
Pattern pattern = Pattern.compile(regex);
//在读取的时候每次都读一整行
while ((line = br.readLine()) != null){
Matcher matcher = pattern.matcher(line);
while (matcher.find()){
System.out.println(matcher.group());
}
}
br.close();
}
---------------------------------------------------------------------------------------------------------------
有条件的爬取数据:
其中涉及到拼接、全取、和排除(?代表前面的数据)
?i --- 取消大小写识别
1.?= --- 拼接
2.?: --- 全取
3.?! --- 排除
接下来的代码分别展示了这三个条件符号如何使用:
public static void main(String[] args) throws IOException {
//有条件的爬取数据
// 有如下文本,请按照要求爬取数据:
// Java自从95年以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,
// 因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台
/*
需求:
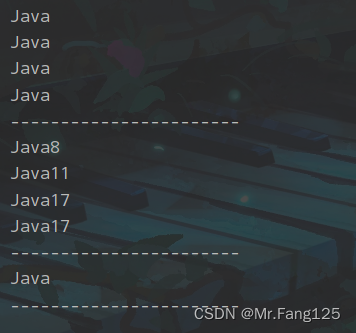
1.爬取版本号为8,11,17的Java文本,但是只要Java,不显示版本号
2.爬取版本号为8,11,17的java文本。正确爬取结果为:Java8Java11Java17Java17
3.爬取除了版本号为8,11,17的Java文本
*/
String str = " Java自从95年以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+
"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//需求1
String regex1 = "((?i)Java)(?=8|11|17)";
Pattern p1 = Pattern.compile(regex1);
Matcher m1 = p1.matcher(str);
while (m1.find()){
System.out.println(m1.group());
}
System.out.println("-----------------------");
//需求2
String regex2 = "((?i)Java)(?:8|11|17)";
Pattern p2 = Pattern.compile(regex2);
Matcher m2 = p2.matcher(str);
while (m2.find()){
System.out.println(m2.group());
}
System.out.println("-----------------------");
//需求3
String regex3 = "((?i)java)(?!8|11|17)";
Pattern p3 = Pattern.compile(regex3);
Matcher m3 = p3.matcher(str);
while (m3.find()){
System.out.println(m3.group());
}
System.out.println("-----------------------");
} 
---------------------------------------------------------------------------------------------------------------
贪婪爬取和非贪婪爬取
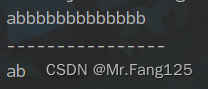
贪婪爬取:在爬取数据的时候尽可能的多获取数据
非贪婪爬取:在爬取数据的时候尽可能少获取数据
java当中,默认的就是贪婪爬取。
在数量词后加上?,如+?,*?,那么此时为非贪婪爬取
以下是示例代码:
public static void main(String[] args) {
//需求:在如下文本中,尽可能多或少获取规则数据
String str = " Java自从95年以来,经历了很多版本,目前企业中用的最多的是Java8和Java11,"+
"abbbbbbbbbbbbb"+
"因为这两个是长期支持版本,下一个长期支持版本是Java17,相信在未来不久Java17也会逐渐登上历史舞台";
//贪婪爬取
String regex1 = "ab+";
Pattern p1 = Pattern.compile(regex1);
Matcher m1 = p1.matcher(str);
while (m1.find()){
System.out.println(m1.group());
}
System.out.println("----------------");
//非贪婪爬取
String regex2 = "ab+?";
Pattern p2 = Pattern.compile(regex2);
Matcher m2 = p2.matcher(str);
while (m2.find()){
System.out.println(m2.group());
}
}
识别正则:
方法:
1.public String[] matches(String regex) --- 判断字符串是否满足正则表达式规则
2.public String replaceAll(String regex,String newStr) --- 按照正则表达式的规则进行替换
3.public String[] spilt(String regex) --- 按照正则表达式的规则切割字符串
以下是识别正则的示例代码:
public static void main(String[] args) {
// 1.public String replaceAll(String regex,String newStr) --- 按照正则表达式的规则进行替换
// 2.public String[] spilt(String regex) --- 按照正则表达式的规则切割字符串
/*
需求:
有一段字符串:顶顶顶asdafavajnanc13113嗷嗷嗷asdaafna阿迪王
要求1:把字符串中三个姓名之间的字母替换成vs
要求2:把字符串中的三个姓名切割出来
*/
String str = "顶顶顶asdafavajnanc13113嗷嗷嗷asdaafna阿迪王";
//要求1
//细节:
//方法在底层和之前一样也会创建文本解析器的对象,然后从头开始去读取字符串的内容,只要有满足,则用第二个参数替换
String result = str.replaceAll("[\\w&&[^_]]+", "vs");
System.out.println(result);
//要求2
//细节:根据我所给的正则表达式的规则,判断规则为切割点,然后每组数据整理为String的数组
String[] arr = str.split("[\\w&&[^_]]+");
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
}
寻找识别正则方法,在API帮助文档中看见参数中带有regex的,那么这个方法一定识别正则















 1278
1278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









