






1. Linux下网络I/O模型
对于Linux系统,Richard Stevens在<Unix 网络编程:卷一>中提到了5种网络I/O模型(下面的图也来自于这本书),分别是:1. 阻塞式I/O模型
2. 非阻塞I/O模型
3. I/O复用模型
4. 信号驱动I/O模型
5. 异步I/O模型
其中前4种模型是都是同步I/O模型,有的只是API和API调用方式有所区别,只有最后一种是异步I/O模型。这里区分的标准是I/O读写是否由内核,还是由用户进程来完成。
2. 阻塞式I/O模型
对于阻塞式I/O模型,用户层的收发进程或线程会一直阻塞,直到数据拷贝完成。具体见下图: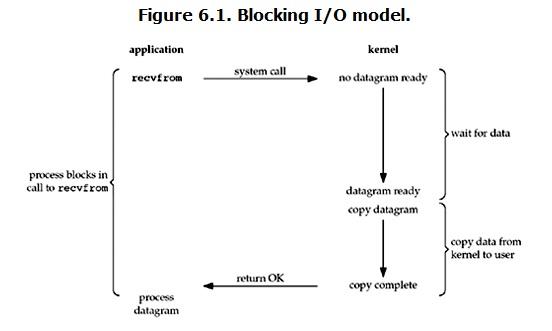
使用阻塞式I/O,server端的流程如下:
- socket
- |
- bind
- |
- listen
- |
- accept
- |
- read/write
- |
- close
客户端流程如下:
- socket
- |
- connect
- |
- write/read
- |
- close
使用阻塞模式的套接字,开发网络程序比较简单,容易实现。在套接字数量较少的情况下,可以考虑使用阻塞模型来开发。特别是在通讯双方,一问一答的形式下,阻塞模型实现最为简单。
如果需要在通讯的双方实现全双工,也就是每一方都能够同时收发数据,使用阻塞式套接字,意味着程序为每个连接必须存在两个线程。如果线程之间还需要同步,在大量套接字的情况下,阻塞式Socket模型难以维护,难以扩展。
3. 非阻塞I/O模型
对于非阻塞I/O模型,用户需要通过进程反复调用I/O函数(多次系统调用,并马上返回)。阻塞模式套接字的不足表现为,在大量建立好的套接字线程之间进行通信时比较困难。当使用“生产者-消费者”模型开发网络程序时,为每个套接字都分别分配一个读线程、一个处理数据线程和一个用于同步的事件,那么这样无疑加大系统的开销。其最大的缺点是当希望同时处理大量套接字时,将无从下手,扩展性很差。 具体见下图: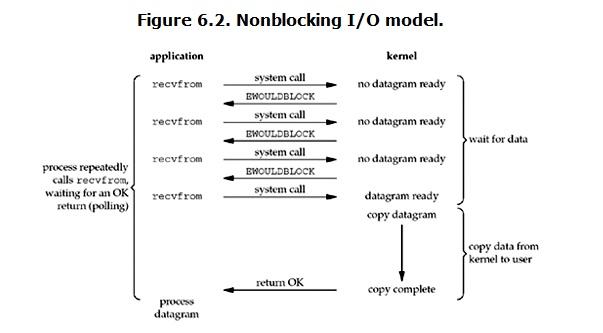
从上图中可以看出,这是一个用户不断轮询的过程。每次用户都会询问内核是否有数据报准备好(文件描述符缓冲区是否就绪),当数据报准备好的时候,就进行拷贝数据报的操作。当数据报没有准备好的时候,也不阻塞程序,内核直接返回未准备就绪的信号,等待用户程序的下一次轮询。
使用非阻塞I/O模型,server端的流程如下:
- socket
- |
- bind
- |
- listen
- |
- accept
- |
- read(null) -> read(null) -> read(null) -> ... read(data)
- |
- write(null) -> write(null) -> write(null) -> ... write(data)
- |
- close
客户端流程如下:
- socket
- |
- connect
- |
- read(null) -> read(null) -> read(null) -> ... read(data)
- |
- write(null) -> write(null) -> write(null) -> ... write(data)
- |
- close
在上述的非阻塞式I/O模型中,用户使用时需要不断的轮询,也就是不断的调用I/O操作去查询I/O上是否存在数据接收或者数据是否可以发送,因此CPU可能会被一直用于轮询,而造成资源的浪费。所以在实际情况下,很少会使用非阻塞式的I/O模型,但是也不排除使用I/O复用模型的局部,使用该种方式。举个例子,为了方便起见,当使用select函数获得某个socket可写的信号时,使用write函数一次写入的数据大小可能小于我们希望写入的数据大小,这时往往可以继续调用write函数,直至写完。而不必要重新进行select等待,直到等到下一个socket可写信号,而进行写入。
4. I/O复用模型
I/O复用模型的关键是使用select函数,对一个I/O端口,两次调用,两次返回,但同阻塞式I/O模型下的send/recv函数不同的是,select函数可以同时阻塞多个I/O操作,而且可以同时对多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。同select函数功能类似的,还有poll、epoll操作,这个接下来讨论。具体见下图:
从上图中可见,当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
使用I/O复用模型,server端的流程如下:
- socket
- |
- bind
- |
- listen
- |
- select <=============
- | |
- accept/read/write ====
- |
- close
客户端流程如下:
- socket
- |
- connect
- |
- select <=============
- | |
- read/write ===========
- |
- close
I/O复用模型的好处是在于它可以同时处理多个connection。
5. 信号驱动I/O模型
信号驱动模型是Linux/Unix系统上所特有的,源自Berkeley的Socket实现了SIGIO信号,用来支持套接字和终端设备上的信号驱动I/O功能。使用信号驱动I/O时,进程预先告知内核,使得当某个socketfd有events(事件)发生时,内核使用信号通知相关进程。具体见下图:

1. 建立SIGIO信号处理函数
sigaction 结构:
- struct sigaction
- {
- void (*sa_handler)(int); //信号处理函数
- sigset_t sa_mask; //用来设置在处理该信号时暂时将sa_mask指定的信号搁置
- int sa_flags; //用来设置信号处理的其他相关操作
- void (*sa_restorer)(void); //这个参数没有使用
- } ;
sigaction 函数:
- int sigaction(int signum, // 所注册的信号,我们这边都设置为SIGIO
- const struct sigaction *act, // 信号触发所处理的函数
- struct sigaction *oldact); // 一般设置为NULL
示例:
- void do_sigio(int sig)
- {
- /* SIGIO处理 */
- }
- struct sigaction sigio_action;
- memset(&sigio_action, 0, sizeof(sigio_action));
- sigio_action.sa_flags = 0;
- sigio_action.sa_handler = do_sigio;
- sigaction(SIGIO, &sigio_action, NULL);
2. 设置该套接口的属主,通常使用fcntl的F_SETOWN命令设置。
- int fd;
- fd = socket(AF_INET, SOCK_DGRAM, 0);
- ......
- fcntl(fd, F_SETOWN, getpid()); // 设置套接字所有者以接收SIGIO
3. 开启该套接口的信号驱动I/O,通常使用fcntl的F_SETFL命令打开O_ASYNC标志完成。
- int flags;
- flags = fcntl(fd, F_GETFL, 0); // 获取Socket原有flag参数
- flags |= O_ASYNC | O_NONBLOCK;
- fcntl(fd, F_SETFL, flags); // 设置信号驱动和非阻塞模式
信号驱动I/O模型用的比较少,主要使用在UDP套接字上,TCP套接字几乎不使用。这是因为,在UDP编程中使用信号驱动I/O,此时SIGIO信号产生于下面两种情况:
1. 套接字收到一个数据报。
2. 套接字上发生了异步错误。
因此,当应用因为收到一个UDP数据报而产生的SIGIO时,要么可以调用recvfrom读取该数据报,要么得到一个异步错误。
而对于TCP编程,信号驱动I/O就没有太大意义了,因为对于流式套接字而言,有很多情况都可以导致SIGIO产生,而应用又无法区分是什么具体情况导致该信号产生的。例如 :
1. 监听套接字完成了一个连接请求。
2. 收到了一个断连请求。
3. 断连操作完成。
4. 套接字收到数据。
5. 有数据从套接字发出。
对于TCP下应用信号驱动I/O模型,Stevens 指出:我们应该考虑只对“监听(形容词)TCPsocket”(描述符)使用SIGIO,因为对于“监听TCPsocket”产生SIGIO的唯一条件是新 连接完成。也就是说,只有TCP下只有用作listen的端口,才考虑使用信号驱动I/O模型。
6. 异步I/O模型
Linux下的异步I/O模型使用的非常少,通常认为Linux下没有比较完美的异步文件I/O方案。目前比较出名的有 Glibc 的AIO与 Kernel Native AIO 等方案。异步I/O表现为:
用户进程发起read操作之后,立刻就可以开始去做其它的事。而从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。请注意这个过程和信号驱动I/O模型是不同的,内核完成了I/O数据的读写,而不是用户进程。具体如下图:
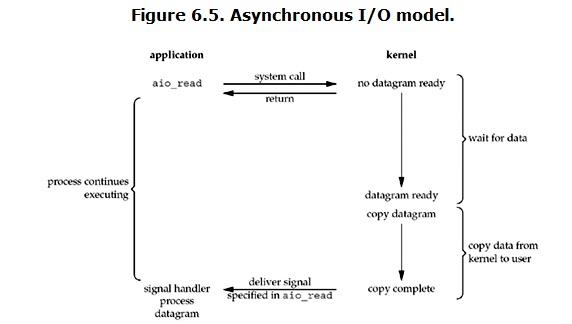
7. 各种I/O模型的比较:















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









