







Pipeline
管道或流水线,设计类似双向链表,ReferencePipeline主要实现了Stream接口,Stream是暴露给用户的接口。AbstractPipeline主要实现了BaseStream接口。它们的继承关系如图:

ReferencePipeline实现类有三种:Head-链表头、StatelessOp-无状态操作、StatefullOp-有状态操作。无状态操作和有状态操作都属于中间操作,Head是stream操作创建的第一个Stream,记录了数据集的Spliterator、stream操作的初始状态及特性、是进行同步操作还是异步操作。这篇文章分享的就是同步操作。中间操作包括:筛选、映射、去重、排序、切片等。
Spliterator
分路器或可分割迭代器(Splitable iterator),主要接口:
1)tryAdvance,执行接口,对元素进行操作或可向下传递
2)forEachRemaining,遍历数据集的剩余元素,通过tryAdvance分发
3)trySplit,并行操作,Fork分割接口,实现数据分割
4)estimateSize,评估执行数量,数据集执行的最终位置减去执行的初始位置,异步操作中配合trySplit使用,同步操作中数值为数据集总量
5)getExactSizeIfKnow 确切数据集数量
6)characteristics 特性,用于初始化Stream的初始状态
TerminalOp
终端操作,终端操作是对中间操作搜集的数据进行消费,终端操作包括遍历、匹配、查找、归约、聚合、统计、分组\分区等,这篇文章分享遍历、匹配、查找、归约。

终端操作继承或者包含了Sink,Sink接口继承Consumer接口,Sink主要包括begin、end、accept等方法,是数据的操作流向。中间操作通过opWrapSink产生Sink,opWrapSink是AbstractPipeline的抽象方法。中间操作或者终端操作具体做啥事情,都是通过实现Sink来实现。
Sink
水槽或操作池,槽就是有进有耗有出,Sink完成三件事情:
1)接收上一个Sink来的数据
2)对数据做中间操作,例如映射、排序等
3)数据流向下一个Sink
Sink的流动策略分为:单数据操作后流(无状态操作,例如:映射)、搜集全数据操作后流(有状态操作,例如:排序)
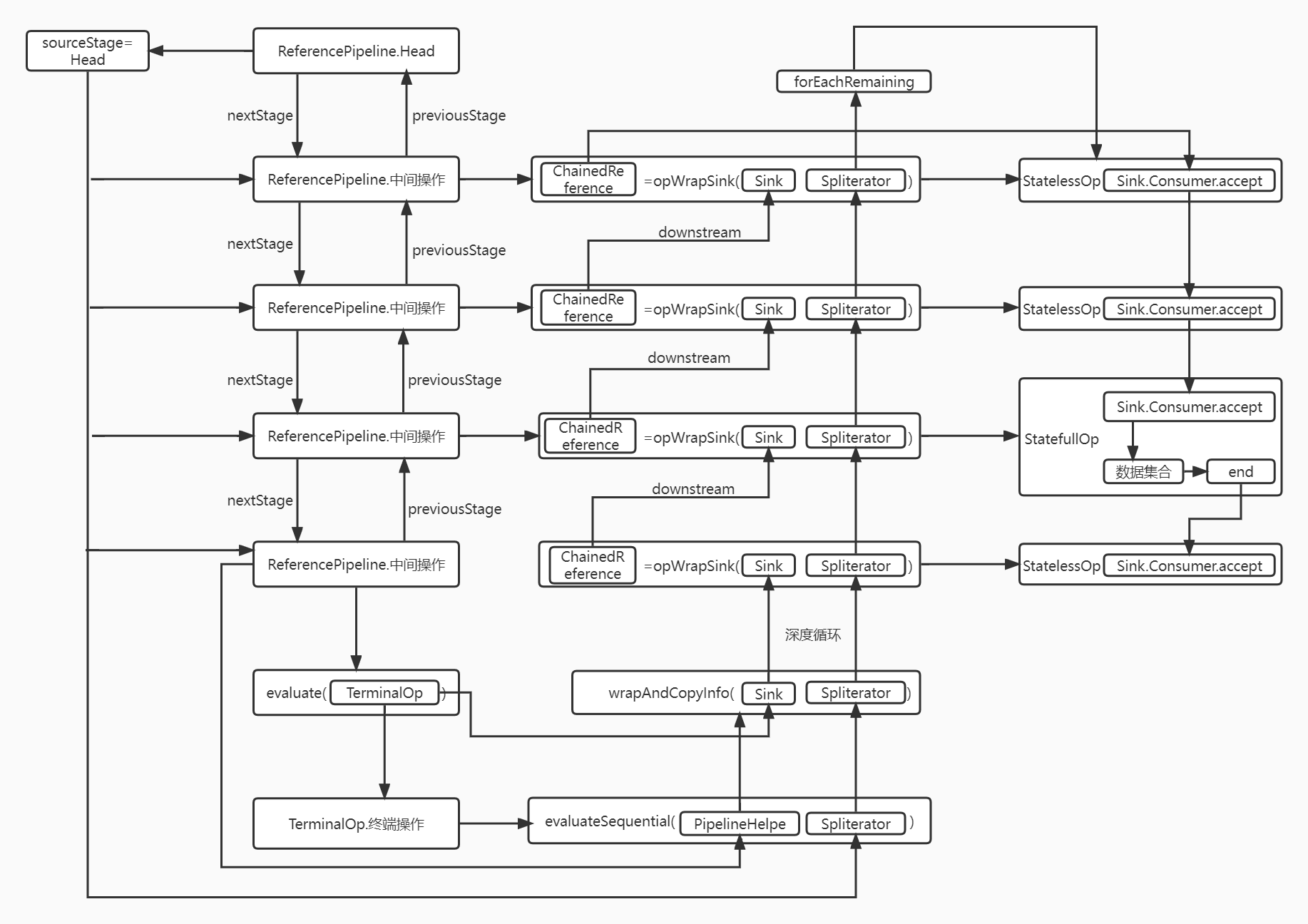
每个中间操作实现其对应的功能,中间操作是通过双向链表串联起来的ReferencePipeline,其中包括:nextStage,下一个ReferencePipeline;previousPipeline,前一个ReferencePipeline;sourceStage,指向Head ReferencePipeline。
中间操作ReferencePipeline通过evaluate执行终端操作TerminalOp,通过wrapAndCopyInfo完成ReferencePipeline向ChainedReference转换,ChainedReference中包含Sink。第一个Sink就是终端操作本身(ForEachOp)或者其内包含的Sink(MatchOp、FindOp、ReduceOp)。
wrapAndCopyInfo从最后一个中间操作开始,通过depth和previousState向前找,直到Head链接的第一个ReferencePipeline,Head的depth是0,不会产生Sink,不做任何操作。
ChainedReference中包含Sink,即指向下一个的Sink,Spliterator是Head中的sourceState中包含的Spliterator,即创建Stream时,数据集创建的Spliterator。
StatelessOp
无状态中间操作:筛选、映射、切片。
筛选:filter
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
// Android-changed: Make public, to match the method it's overriding.
public Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.Chai 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 522
522











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









