







散列函数(哈希函数)
实际上,散列函数也是哈希算法的一种应用。
- 散列函数是设计一个散列表(也叫做哈希表)的关键。它直接决定了散列冲突的概率和散列表的性能。
- 不过,相对哈希算法的其他应用,散列函数对于散列算法冲突的要求要低很多。
- 即便出现个别散列冲突,只要不是过于严重,我们都可以通过开放寻址法或者链表法解决。
- 不仅如此,散列函数对于散列算法计算得到的值,是否能反向解密也并不关心。
- 散列函数中用到的散列算法,更加关注散列后的值是否能平均分布,也就是,一组数据是否能均匀地散列在各个槽中。
- 除此之外,散列函数执行的快慢,也会影响散列表的性能,所以,散列函数用的散列算法一般都比较简单,比较追求效率。
实现哈希算法的函数叫做哈希函数,可以用f(in) = out表示
举个例子:
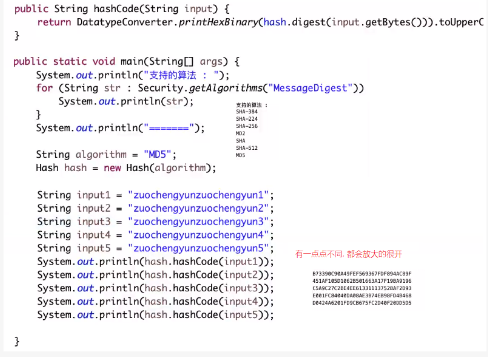
哈希函数应该有如下特性:
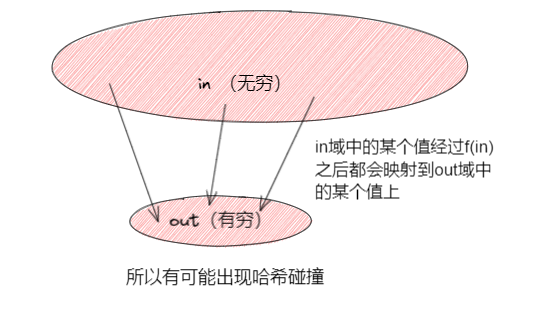
- 输入参数in,其值域范围可以看作是无穷大的。
- 输出函数out,其值域范围可能性很大,但是一定是有穷尽的
- 哈希函数没有任何随机的机制,固定的输入一定是固定的输出
- 输入无穷多但是输出值有限,所以不同的输入可能有相同的输出(哈希碰撞)
- 再相似的不同输入,得到的输出值,会几乎均匀的分布在out域上
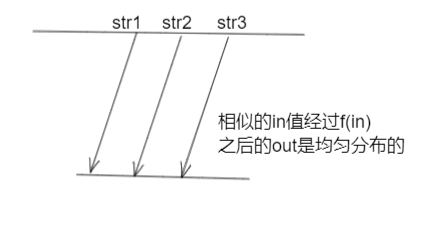
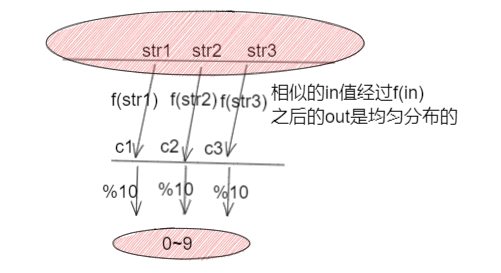
推论:相似字符串,经过f(str1)输出一个0~2^{128}-1中的一个数,经过%10之后,在0~9上还是均匀分布的
解决哈希冲突
开放寻址法
发生冲突,继续寻找下一块未被占用的存储地址。常见的实现方法有如下三种:
(1)线性探测(Linear Probing)(最好O(1);最坏情况下的时间复杂度为 O(n))
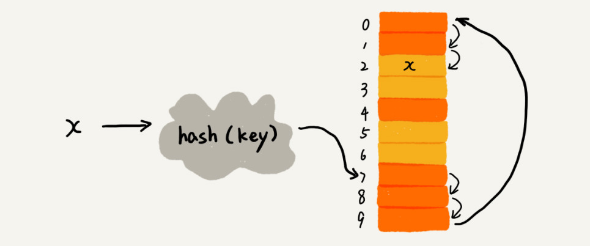
- 插入:如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
- 查找:过程和插入一样,找到对应数组下标后,对比x与数组中存储的值是否相等,若不等则依次往后查找…
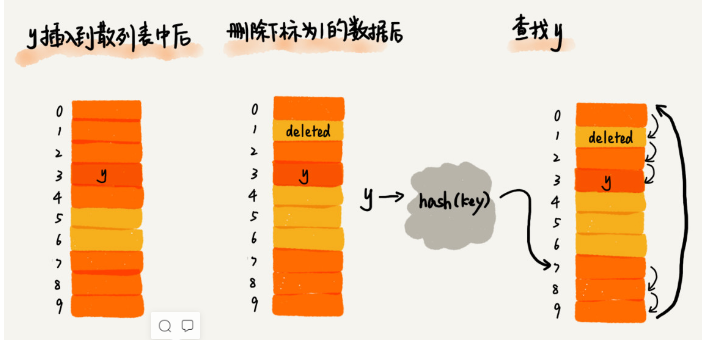
- 删除:删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
(2)二次探测(Quadratic probing)
和线性探测(Linear Probing)类似,只不过每次步长为冲突下标的平方(i^2)。
(3)双重散列(Double hashing)
所谓双重散列,意思就是不仅要使用一个散列函数。我们使用一组散列函数 hash1(key),hash2(key),hash3(key)……我们先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。
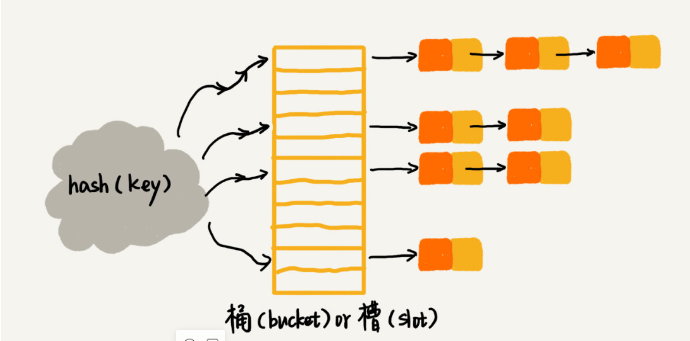
拉链法
散列表中,每个“桶(bucket)”或者“槽(slot)”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中:
- 当hash冲突不严重的时候,查找某个键,只需要求hash值,然后取余,定位到数组的某个下标即可,时间复杂度为
O(1) - 当hash冲突十分严重的时候,即使负载因子和散列函数设计得再合理,也免不了会出现拉链过长的情况,即使定位到数组的某个下标,也要遍历一条很长很长的链表,就退化为查找链表了。时间复杂度为
O(n)
怎么解决呢?
- 到了一定时候就扩容。什么时候是一定时候呢?
- 用一个装载因子来衡量
- 我们知道,当散列表中数组空闲位置不多的时候,散列冲突的概率会大大提高
- 装载因子 = 填入数组的元素个数/数组长度
- 装载因子越大,说明空闲位置越少,冲突越多,散列表的性能会下降。当装载因子超过某个值时,就扩容数组。
- 将链表转换为其他结构。比如,在java中的hashmap中:
- 当链表长度太长(默认超过 8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高 HashMap 的性能。
- 当红黑树结点个数少于 6个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。
开放寻址法 VS 链表法
Java 中 LinkedHashMap 就采用了链表法解决冲突,ThreadLocalMap 是通过线性探测的开放寻址法来解决冲突。
开放寻址法
- 优点:开放寻址法不像链表法,需要拉很多链表。散列表中的数据都存储在数组中,可以有效地利用 CPU 缓存加快查询速度。而且,这种方法实现的散列表,序列化起来比较简单。链表法包含指针,序列化起来就没那么容易。
- 缺点:开放寻址法解决冲突的散列表,删除数据的时候比较麻烦,需要特殊标记已经删除掉的数据。而且,在开放寻址法中,所有的数据都存储在一个数组中,比起链表法来说,冲突的代价更高。所以,使用开放寻址法解决冲突的散列表,装载因子的上限不能太大。这也导致这种方法比链表法更浪费内存空间。
当数据量比较小、装载因子小的时候,适合采用开放寻址法。 这也是 Java 中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
链表法
- 首先,链表法对内存的利用率比开放寻址法要高。因为链表结点可以在需要的时候再创建,并不需要像开放寻址法那样事先申请好。
- 对于链表法来说,只要散列函数的值随机均匀,即便装载因子变成 10,也就是链表的长度变长了而已,虽然查找效率有所下降,但是比起顺序查找还是快很多。
- 链表因为要存储指针,所以对于比较小的对象的存储,是比较消耗内存的,(如果我们存储的是大对象,也就是说要存储的对象的大小远远大于一个指针的大小(4 个字节或者 8 个字节),那链表中指针的内存消耗在大对象面前就可以忽略),还有可能会让内存的消耗翻倍。而且,因为链表中的结点是零散分布在内存中的,不是连续的,所以对 CPU 缓存是不友好的,这方面对于执行效率也有一定的影响。
- 实现一个更加高效的散列表。那就是,我们将链表法中的链表改造为其他高效的动态数据结构,比如跳表、红黑树。这样,即便出现散列冲突,极端情况下,所有的数据都散列到同一个桶内,那最终退化成的散列表的查找时间也只不过是 O(logn)。这样也就有效避免了散列碰撞攻击。
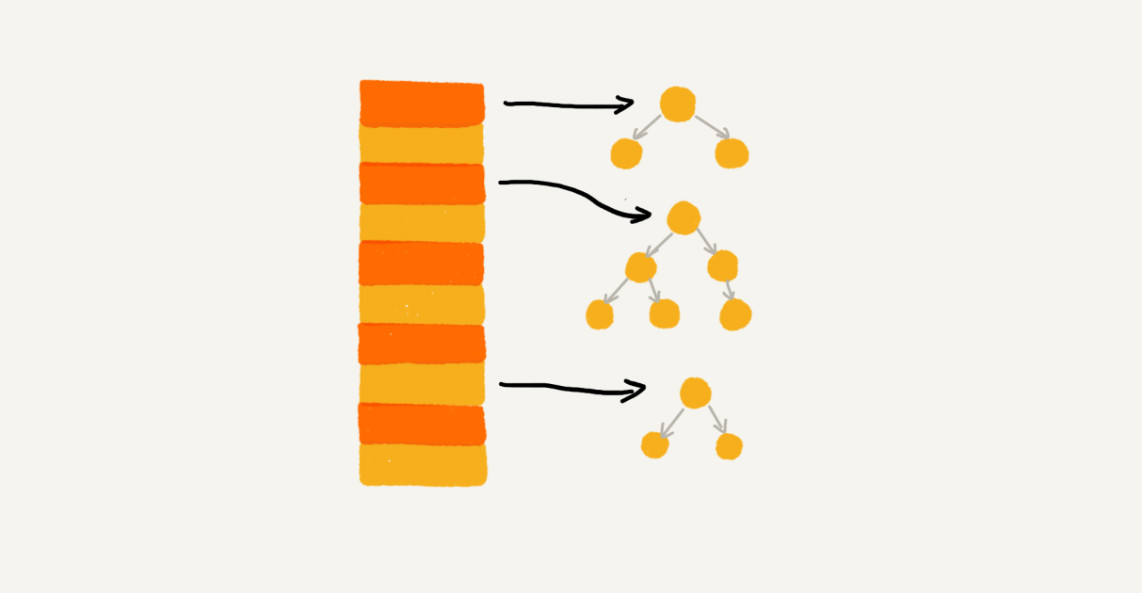
基于链表的散列冲突处理方法比较适合存储大对象、大数据量的散列表,而且,比起开放寻址法,它更加灵活,支持更多的优化策略,比如用红黑树代替链表。
设计实现哈希表
为什么要有哈希表(也叫做散列表,hashtable)这一数据结构,它是用来解决什么问题的。
在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能
- 数组:采用一段连续的存储单元来存储数据。对于指定下标的查找,时间复杂度为O(1);通过给定值进行查找,需要遍历数组,逐一比对给定关键字和数组元素,时间复杂度为O(n),当然,对于有序数组,则可采用二分查找,插值查找,斐波那契查找等方式,可将查找复杂度提高为O(logn);对于一般的插入删除操作,涉及到数组元素的移动,其平均复杂度也为O(n)
- 线性链表:对于链表的新增,删除等操作(在找到指定操作位置后),仅需处理结点间的引用即可,时间复杂度为O(1),而查找操作需要遍历链表逐一进行比对,复杂度为O(n)
- 二叉树:对一棵相对平衡的有序二叉树,对其进行插入,查找,删除等操作,平均复杂度均为O(logn)。
- 哈希表:相比上述几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下(后面会探讨下哈希冲突的情况),仅需一次定位即可完成,时间复杂度为O(1)
可以看出,哈希表是用来进行快速查找的。
设计实现哈希表
哈希表底层一定是数组。
- 我们知道,数据结构的物理存储结构只有两种:顺序存储结构和链式存储结构(像栈,队列,树,图等是从逻辑结构去抽象的,映射到内存中,也这两种物理组织形式)
- 在数组中根据下标查找某个元素,一次定位就可以达到,哈希表利用了这种特性,哈希表的主干就是数组。
比如我们要新增或查找某个元素,我们通过把当前元素的关键字 通过哈希函数映射到数组中的某个位置,通过数组下标一次定位就可完成操作。
第一步:申请一个数组,用来做哈希表
问题:数组的长度应该如何选择?
比如HashMap中,默认的初始大小是16。这个默认值是可以设置的,如果事先知道大概的数据量有多大,可以通过修改默认初始大小,减少动态扩容的次数。
第二步:选择哈希函数,通过哈希函数可以获得hash值
哈希函数的作用:
- 根据key获取hash值
哈希函数怎么设计?
- 散列函数的设计不能太复杂。过于复杂的散列函数,势必会消耗很多计算时间,也就间接地影响到散列表的性能。
- 散列函数生成的值要尽可能随机并且均匀分布,这样才能避免或者最小化散列冲突,而且即便出现冲突,散列到每个槽里的数据也会比较平均,不会出现某个槽内数据特别多的情况。
比如:
- 处理手机号码,因为手机号码前几位重复的可能性很大,但是后面几位就比较随机,(因为随机,所以会分布比较均匀)我们可以取手机号的后四位作为散列值。这种散列函数的设计方法,我们一般叫做“数据分析法”。
第三步:根据hash值映射到哈希数组,得到数组索引
数组寻址(存储位置 = hash(关键字)):
- 拿到哈希值之后,我们要将这个值映射到数组的某一个空间,也就是进行数组寻址
- 如果数组的长度为len,那么
index = hash % len,得到了一个索引

总的过程:先通过哈希函数计算出实际存储地址,然后去对应数组中进行操作
第三步:检测是否出现哈希冲突
然而万事无完美,如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。
得到索引后,去索引出找这个位置是否已经被占用了。
- 如果没有:
- 查询、删除操作:说明这个找不到这个数,直接返回
- 插入、修改操作: hashtable[idx] = val
- 如果有:
- 查询操作:说明找到了,直接返回
- 删除操作: hashtable[idx] = null
- 修改操作:hashtable[idx] = newVal
- 插入操作:说明出现了哈希冲突。
出现了哈希冲突怎么办?
- 检测装载因子,如果发现装载因子 < 阈值,那么直接插入
- 检测装载因子,如果发现装载因子 >= 阈值,进行哈希扩容
阈值应该怎么设置?
- java的hashmap,最大装载因子默认是 0.75,当 HashMap 中元素个数超过 0.75*capacity(capacity 表示散列表的容量)的时候,就会启动扩容,每次扩容都会扩容为原来的两倍大小。
第四步:哈希扩容
为避免低效扩容:
- 当装载因子达到阈值之后,我们只申请新空间,但并不将老的数据搬移到新散列表中
- 当有新数据要插入时,我们将新数据插入到新散列表中,并从老的散列表中拿出一个数据放入到新散列表中。每次插入一个数据到散列表,我们都重复上面的过程。经过多次插入操作之后,老的散列表中的数据就一点一点全部搬移到新散列表中了。
- 这期间的查询操作怎么来做呢?对于查询操作,为了兼容新、老散列表中的数据,我们先从新散列表中查找。如果没有找到,再去老的散列表中查找

将一次性扩容的代价,均摊到多次插入操作中:任何情况下,插入一个数据的时间复杂度都是 O(1)。
















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









