







命令
| 命令 | 描述 | 返回值和备注 |
|---|---|---|
| HSET | Hset key-name key value–为散列里面的一个字段赋值 | 如果字段或者散列不存在则创建并且返回1,如果字段已经存在则覆盖并且返回0 |
| HMSET | Hset key-name key value [key value …]–为散列里面的一个或者多个键赋值 | 如果不存在则创建,存在则覆盖。操作成功返回OK。推荐使用 |
| Hsetnx | Hset key-name key value–用于为哈希表中不存在的的字段赋值 | 如果字段已经存在,操作无效返回0,否则创建字段并设置值并且返回0 |
| HDEL | HDEL key-name key [key …]–删除散列 中的一个或多个指定字段,不存在的字段将被忽略 | 返回成功删除的键值对的数量 |
| HLEN | HLEN key-name --查看hash中有几个字段 | 返回散列包含的键值对数量, 当 key 不存在时,返回 0 |
| HEXISTS | HEXISTS key-name key–查看散列的指定字段是否存在 | 如果存在返回1,不存在返回0 |
| HKEYS | HKEYS key-name–获取散列中包含的所有字段 | 包含散列中所有字段的列表 |
| HVALS | HVALS key-name–获取散列中包含的所有值 | 包含散列中所有值的列表 |
| HGET | HGET key-name key --获取散列中指定字段的值 | 返回给定字段的值。如果给定的字段或 key 不存在时,返回 nil |
| HMGET | HMGET key-name key value [key value …]–获取散列中一个或多个指定字段的值 | 推荐 |
| HGETALL | HGETALL key-name --获取散列中所有的字段和值 | 以列表形式返回哈希表的字段及字段值,若 key 不存在,返回空列表。返回值的长度是哈希表大小的两倍。 |
| HINCRBY | hincrby key-name key increment–将键key存储的值加上整数increment | |
| HINCRBYFLOAT | HINCRBYFLOAT key-name key increment–将键key存储的值加上浮点数increment |
不需要再添加字段前先初始化一个空哈希,redis会自动实现初始化,redis会自动回收空哈希
设置
HSET:设置value
作用
- 用于为哈希表中的字段赋值 。
- 如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。
- 如果字段已经存在于哈希表中,旧值将被覆盖。
语法
redis 127.0.0.1:6379> HSET KEY_NAME FIELD VALUE
可用版本
>= 2.0.0
返回值
- 如果字段是哈希表中的一个新建字段,并且值设置成功,返回 1 。
- 如果哈希表中域字段已经存在且旧值已被新值覆盖,返回 0 。
实例
redis 127.0.0.1:6379> HSET myhash field1 "foo"
OK
redis 127.0.0.1:6379> HGET myhash field1
"foo"
redis 127.0.0.1:6379> HSET website google "www.g.cn" # 设置一个新域
(integer) 1
redis 127.0.0.1:6379>HSET website google "www.google.com" # 覆盖一个旧域
(integer) 0
Hsetnx:设置value
作用
- 用于为哈希表中不存在的的字段赋值 。
- 如果哈希表不存在,一个新的哈希表被创建并进行 HSET 操作。
- 如果字段已经存在于哈希表中,操作无效。
语法
redis 127.0.0.1:6379> HSETNX KEY_NAME FIELD VALUE
可用版本
>= 2.0.0
返回值
- 设置成功,返回 1 。
- 如果给定字段已经存在且没有操作被执行,返回 0 。
实例
redis 127.0.0.1:6379> HSETNX myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HSETNX myhash field1 "bar"
(integer) 0
redis 127.0.0.1:6379> HGET myhash field1
"foo"
redis 127.0.0.1:6379> HSETNX nosql key-value-store redis
(integer) 1
redis 127.0.0.1:6379> HSETNX nosql key-value-store redis # 操作无效, key-value-store 已存在
(integer) 0
hmset:批量设置value
作用
- 用于同时将多个 field-value (字段-值)对设置到哈希表中。
- 此命令会覆盖哈希表中已存在的字段。
- 如果哈希表不存在,会创建一个空哈希表,并执行 HMSET 操作
语法
redis 127.0.0.1:6379> HMSET KEY_NAME FIELD1 VALUE1 ...FIELDN VALUEN
可用版本
>= 2.0.0
返回值
如果命令执行成功,返回 OK 。
实例
redis 127.0.0.1:6379> HMSET myhash field1 "Hello" field2 "World"
OK
redis 127.0.0.1:6379> HGET myhash field1
"Hello"
redis 127.0.0.1:6379> HGET myhash field2
"World"
hincrby
作用
- 用于为哈希表中的字段值加上指定增量值。
- 增量也可以为负数,相当于对指定字段进行减法操作。
- 如果哈希表的 key 不存在,一个新的哈希表被创建并执行 HINCRBY 命令。
- 如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0
- 对一个储存字符串值的字段执行 HINCRBY 命令将造成一个错误。
- 本操作的值被限制在 64 位(bit)有符号数字表示之内
语法
redis 127.0.0.1:6379> HINCRBY key field increment
可用版本
>= 2.0.0
返回值
执行 HINCRBY 命令之后,哈希表中字段的值。
实例
redis> HSET myhash field 5
(integer) 1
redis> HINCRBY myhash field 1
(integer) 6
redis> HINCRBY myhash field -1
(integer) 5
redis> HINCRBY myhash field -10
(integer) -5
redis>
HINCRBYFLOAT
作用
-
Redis Hincrbyfloat 命令用于为哈希表中的字段值加上指定浮点数增量值。
-
如果指定的字段不存在,那么在执行命令前,字段的值被初始化为 0 。
语法
HINCRBYFLOAT key field increment
可用版本
>= 2.6.0
返回值
执行 Hincrbyfloat 命令之后,哈希表中字段的值。
实例
redis> HSET mykey field 10.50
(integer) 1
redis> HINCRBYFLOAT mykey field 0.1
"10.6"
redis> HINCRBYFLOAT mykey field -5
"5.6"
redis> HSET mykey field 5.0e3
(integer) 0
redis> HINCRBYFLOAT mykey field 2.0e2
"5200"
redis>
查询
hget:获取value
作用
用于返回哈希表中指定字段的值。
语法
redis 127.0.0.1:6379> HGET KEY_NAME FIELD_NAME
可用版本
>= 2.0.0
返回值
- 返回给定字段的值。
- 如果给定的字段或 key 不存在时,返回 nil 。
实例
> HSET site redis redis.com
1
> HGET site redis
"redis.com"
> HGET site mysql
(nil)
Hmget:批量查询value
作用
- 用于返回哈希表中,一个或多个给定字段的值。
- 如果指定的字段不存在于哈希表,那么返回一个 nil 值
语法
redis 127.0.0.1:6379> HMGET KEY_NAME FIELD1...FIELDN
可用版本
>= 2.0.0
返回值
- 一个包含多个给定字段关联值的表,表值的排列顺序和指定字段的请求顺序一样。
实例
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HSET myhash field2 "bar"
(integer) 1
redis 127.0.0.1:6379> HMGET myhash field1 field2 nofield
1) "foo"
2) "bar"
3) (nil)
Hlen:查询field数量
作用
- 获取哈希表中字段的数量。
语法
redis 127.0.0.1:6379> HLEN KEY_NAME
可用版本
>= 2.0.0
返回值
哈希表中字段的数量。 当 key 不存在时,返回 0 。
实例
下面myhash 表有两个字段field1 、field2
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HSET myhash field2 "bar"
(integer) 1
redis 127.0.0.1:6379> HLEN myhash
(integer) 2
hexist:查询field是否存在
作用
查看哈希表的指定字段是否存在。
语法
redis 127.0.0.1:6379> HEXISTS KEY_NAME FIELD_NAME
可用版本
>= 2.0.0
返回值
- 如果哈希表含有给定字段,返回 1
- 如果哈希表不含有给定字段,或 key 不存在,返回 0
实例
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HEXISTS myhash field1
(integer) 1
redis 127.0.0.1:6379> HEXISTS myhash field2
(integer) 0
hkeys:获取所有field
作用
Hkeys 叫做Hfields更合适,它用于获取哈希表中的所有域(field)。
语法
redis 127.0.0.1:6379> HKEYS key
可用版本
>= 2.0.0
返回值
- 包含哈希表中所有域(field)列表。
- 当 key 不存在时,返回一个空列表
实例
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HSET myhash field2 "bar"
(integer) 1
redis 127.0.0.1:6379> HKEYS myhash
1) "field1"
2) "field2"
hvals:获取所有value
作用
返回哈希表所有的值。
语法
redis 127.0.0.1:6379> HVALS key
可用版本
>= 2.0.0
返回值
- 一个包含哈希表中所有值的列表。
- 当 key 不存在时,返回一个空表。
实例
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HSET myhash field2 "bar"
(integer) 1
redis 127.0.0.1:6379> HVALS myhash
1) "foo"
2) "bar"
# 空哈希表/不存在的key
redis 127.0.0.1:6379> EXISTS not_exists
(integer) 0
redis 127.0.0.1:6379> HVALS not_exists
(empty list or set)
hgetall:获取所有的field和value
- 用于返回哈希表中,所有的字段和值。
- 在返回值里,紧跟每个字段名(field name)之后是字段的值(value),所以返回值的长度是哈希表大小的两倍。
语法
redis 127.0.0.1:6379> HGETALL KEY_NAME
可用版本
>= 2.0.0
返回值
- 以列表形式返回哈希表的字段及字段值。
- 若 key 不存在,返回空列表。
实例
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
redis>
注意:
- 当使用hgetall时,如果hash元素比较多,会存在阻塞redis的可能
- 如果只需要获取部分field,建议使用hmget
- 如果一定要获取全部的field-value,建议用hscan,该命令会渐进式遍历hash类型
hstrlen:计算value的字符串长度
作用
- 返回哈希表中给定域相关联的值的字符串长度
语法
hstrlen key field
可用版本
>= 3.2.0
返回值
- 返回字符串字节长度
- 如果给定的键或者域不存在, 返回 0
- 如果 key 不存在时,返回 0
实例
127.0.0.1:6379> hset website qq "qq.com"
(integer) 1
127.0.0.1:6379> hset website baidu "baidu.com"
(integer) 1
127.0.0.1:6379> hstrlen website qq
(integer) 6
127.0.0.1:6379> hstrlen website baidu
(integer) 9
127.0.0.1:6379> hstrlen website jd
(integer) 0
127.0.0.1:6379> hstrlen no:exists:key field
(integer) 0
删除
hdel:删除field
作用
- 用于删除哈希表 key 中的一个或多个指定字段,不存在的字段将被忽略。
语法
redis 127.0.0.1:6379> HDEL KEY_NAME FIELD1.. FIELDN
可用版本
>= 2.0.0
返回值
- 被成功删除字段的数量,不包括被忽略的字段。
实例
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HDEL myhash field1
(integer) 1
redis 127.0.0.1:6379> HDEL myhash field2
(integer) 0
内部编码
哈希类型的内部编码有两种
- ziplist(压缩列表)
- hashtable
ziplist(压缩列表)
- 对于那些长度度小于配置中hash-max-ziplist-entries选项配置的值[默认512字节],且所有元素的大小都小于配置中hash-max-ziplist-value选项配置的值[默认64字节],采用此编码
- ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀
hashtable(哈希表)
- 当哈希类型无法满足ziplist的条件时,redis会采用hashtable作为哈希的内部实现
- 因此此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)
ziplist与hashtable的转换
- 当field个数比较少且没有大的value时,内部编码为ziplist:
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2
OK
127.0.0.1:6379> object encoding hashkey
"ziplist"
- 当value大于64字节内部编码会有ziplist转换成hashtable
127.0.0.1:6379> hset hashkey f3 "one string skjahfd hkjshkd shakfj 长度传递长度 长度skldfj sdf"
(integer) 1
127.0.0.1:6379> OBJECT encoding hashkey
"hashtable"
- 当前filed个数超过512个时内部编码也会又ziplist转换成hashtable
127.0.0.1:6379> hmset hashkey f1 v1 f2 v2 f3 v3 f4 v4 f5 v5 ... f513 v513
OK
127.0.0.1:6379> OBJECT encoding hashkey
"hashtable"
使用场景:缓存用户信息
redis VS mysql
下图为关系型数据库表记录的两条用户信息,用户的属性作为表的列,每条用户信息作为行
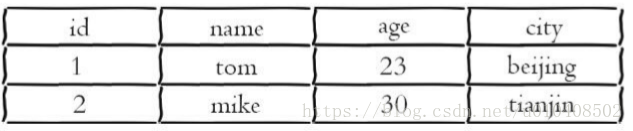
如果将其用hash类存储,如下图
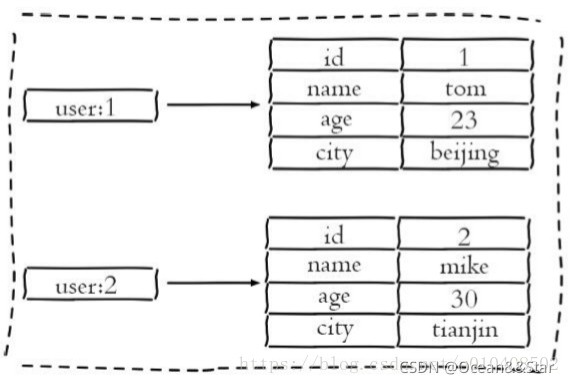
相比于使用字符串序列化缓存用户信息,hash类型变得更加直观,在更新操作上会更加便捷。
可以给每个用户的id定义为后缀,多对field-value对应每个用户的属性
UserInfo getUserInfo(long id){
// 用户id作为key后缀
userRedisKey = "user:info:" + id;
// 使用hgetall获取所有用户信息映射关系
userInfoMap = redis.hgetAll(userRedisKey);
UserInfo userInfo;
if (userInfoMap != null) {
// 将映射关系转换为UserInfo
userInfo = transferMapToUserInfo(userInfoMap);
} else {
// 从MySQL中获取用户信息
userInfo = mysql.get(id);
// 将userInfo变为映射关系使用hmset保存到Redis中
redis.hmset(userRedisKey, transferUserInfoToMap(userInfo));
// 添加过期时间
redis.expire(userRedisKey, 3600);
}
return userInfo;
}
哈希类型和关系型数据库的区别
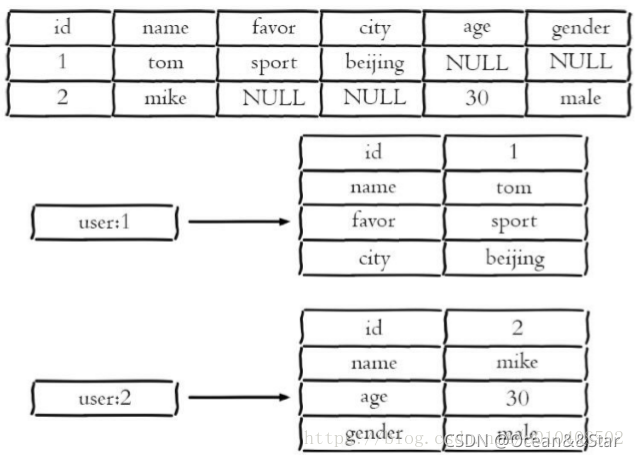
- 哈希类型是稀疏的,而关系型数据库是完全结构化的,比如hash类型每个键都可以有不同的field,而关系型数据库一旦添加新的列,所以行都要为其设置值(即使为NULL),如下图所示
- 关系型数据库可以做复杂的关系操作,而Redis去模拟关系型复杂查询开发困难,维护成本高。
缓存用户信息的三种方案分析
原生字符串类型:一个属性一个键
set user:1:name tom
set user:1:age 23
set user:1:city beijing
优点:
- 简单直观,每个属性都支持更新操作
缺点:
- 占用过多的键,内存占用量较大,同时信息内聚性较差,所以一般不会再生产环境中使用
序列化字符串:用用户信息序列化之后用一个键保存
set user:1 serialize(userInfo)
优点:
- 简化编程,如果合理的使用序列化可以提高内存的使用效率
缺点:
- 序列化和反序列有一定的开销
- 每次更新属性都需要把全部数据取出进行反序列化,更新后再序列化到redis中
hash类型:每个用户属性使用一对field-value,但是只用一个键保存
hmset user:1 name tomage 23 city beijing
优点:
- 简单直观,如果使用合理可以减少内存空间的使用
缺点:
- 要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存

















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









