







集群
广义的集群
- 只要是多个机器 且构成了分布式系统,均可称为是一个集群
- 主从结构、哨兵模式,也可认为是 广义的集群
狭义的集群
- Redis 提供的集群模式,在集群模式下,主要解决存储空间不足问题,即拓展存储空间
- 虽然哨兵模式提高了系统的可用性,但其本质还是通过 Redis 主从节点来存储数据
- 即通过 主节点/从节点 来存储整个数据的全集
问题:
- 一台机器的内存存储的空间始终是有限的!
解决方案:
- 引入多台机器,每台机器存储一部分数据
实例理解
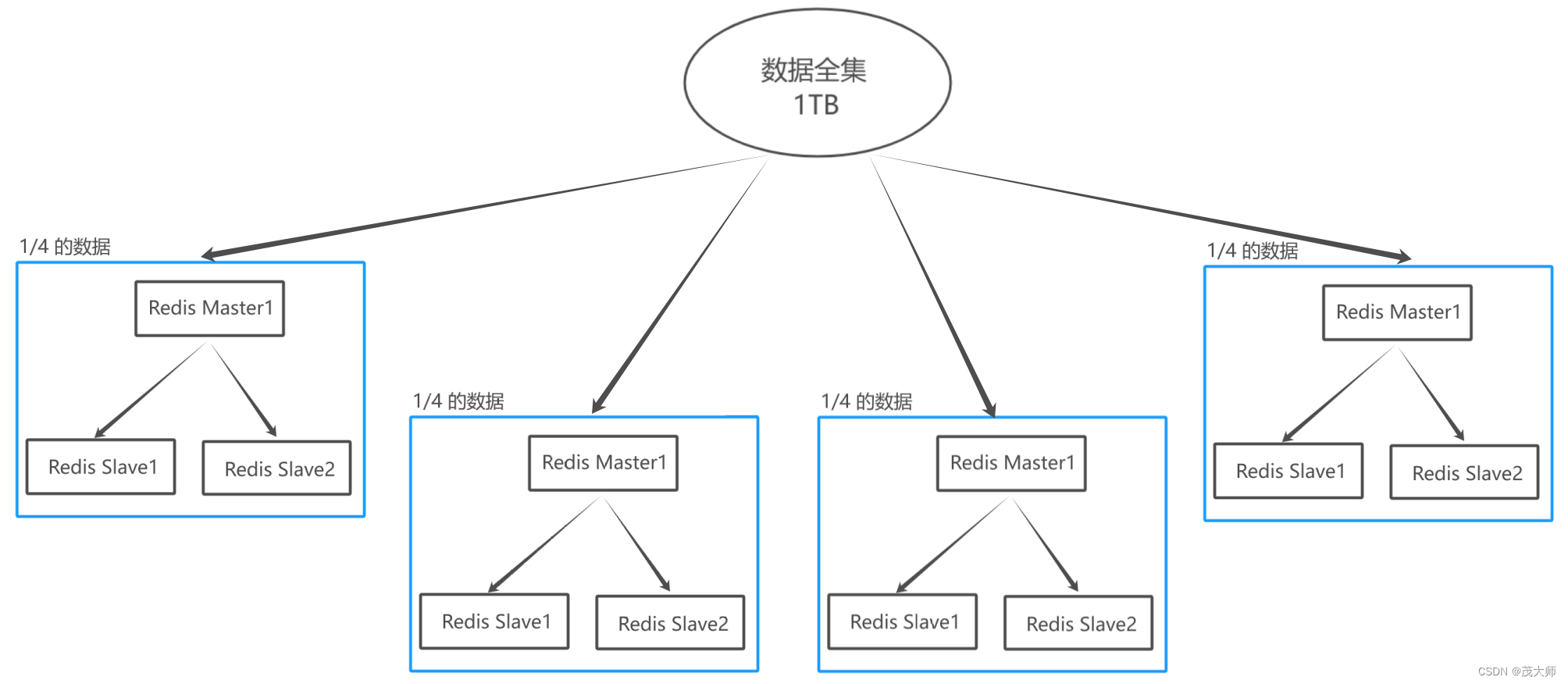
- 例如有 1TB 的数据需要存储
- 拿两台机器来存,每台机器仅需存 512GB
- 拿四台机器来存,每台机器仅需存 256GB
- 随着机器数目的增加,每台机器所存储的数据量也便跟着减少
- 只要机器的规模足够多,便可以存储任意大小的数据
注意:
- 对于拿四台机器而言,不是说光搞四台机器就够了,而是每台存储数据的机器还需搭配若干个从节点
- 下述文章将介绍三种主流的数据分片算法
一、Redis集群方案的简单介绍
Redis集群的方案一般分为三种:
- 哈希取余分区
- 一致性哈希算法分区
- 哈希槽分区(本文介绍的就是这种)
1、哈希取余分区:
优点:
简单粗暴,只要提前预估好数据量,然后规划好节点,例如:3台、30台、300台节点,就能保证未来一段时间内的数据支撑。

缺点:
事先规划好节点,进行扩容或者缩容就比较麻烦了额,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。如果某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1894
1894

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









