







经过一段时间的学习,我对机器学习有了个大概的了解。现在打算重新回看先前的学习资料并重写一部分算法。为了便于上手,选择了一本相对简单并且有python源码的<机器学习实战>,书本上给的是python源码,我计划用我熟悉的matlab重写一遍,并给原来的python代码加上注释,便于后来者观看,书上的第一个算法便是这一次的主题–最邻近算法(K Nearest Neighbour)。
算法描述
KNN可以说是机器学习中最简单的算法之一,KNN的算法是基于一种自然而然的思想构造的,简单说来就是物以类聚,人以群分。KNN的伪代码如下:
对未知类别属性的数据集中的每个点一次执行以下操作:
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序;
(3)选取与当前距离最小的k个点;
(4)确定前k个点所在类别的出现频率;
(5)返回前k个点出现频率最高的类别作为当前点的预测分类。
可以看到算法很简单,但是其中也有两个参数需要确定,一个是距离的选择,距离的选择有很多常见的有欧氏距离,马氏距离,汉明距离等等,个人认为欧式距离已经足够,影响算法准确性的主要是特征的选择。第二个参数是k的选择,k可以通过交叉验证的方法进行确定。
实例分析
算法介绍后我们需要解决一个具体的问题,即手写识别。我们遇到的问题是,对于人脑来说,我们所看的数字是一幅图像,而在电脑看来这是一个二维或三维数组,那我们怎么对数字进行识别?
根据书本提供的资料,我们可以从trainningDigits中获取大约2000个例子,每个例子如下图所示。同样目录testDigits中包含了大约900个测试数据。接下来我们将使用目录trainningDigits中的数据训练分类器,使用目录testDigits中的数据测试分类器的效果。


因为算法比较简单,我们直接看代码,先看python代码:
from numpy import *
import operator
from os import listdir
def classify0(inX, dataSet, labels, k):
#采用KNN判断类别
dataSetSize = dataSet.shape[0]#计算训练样本样本数
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5#以上4行计算距离
sortedDistIndicies = distances.argsort()#对距离计算结果进行排序,默认为升序
classCount={}
for i in range(k):#计算最近K个距离所属类别
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)#得到最后的类别
return sortedClassCount[0][0]
def img2vector(filename):
#从text文本中读取数据
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #加载训练集
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #去掉.txt后缀名
classNumStr = int(fileStr.split('_')[0])#获取其所属类别
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #加载测试集
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #去掉.txt后缀名
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)#采用最邻近算法进行分类
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0#计算样本错误个数
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))#计算错误率
handwritingClassTest()可以看到主要有三个函数,classify0负责计算未知样本所属分类,img2vector负责将text文本转化为向量,handwritingClassTest则是识别的入口函数,handwritingClassTest将逐个读取测试样本,并统计最后的错误率。
接下来是matlab代码:
function KNN_digits
%调用KNN算法,计算手写输入情况
%% 读取测试样本及其标签
testDigits=dir('testDigits');
fprintf('Loading testDigits....\n');
testDigits(1:2,:)=[];%名字中带有表示此文件和上一文件夹的字符
Cell_name={testDigits.name};%将单元数组中的某一字段取出放入一个单元数组中
Char_name=cell2mat(Cell_name);%将单元数组变成一字符串
index=regexpi(Char_name,'\d_\d');%利用正则表达式找到合适的字符
labels=Char_name(index);%利用索引将指定字符取出
test_real_Labels=abs(labels)-48;%获得样本的标签
size_testDigits=size(testDigits);
test_Features=zeros(size_testDigits(1),1024);
for i=1:size_testDigits(1)
readname=strcat('testDigits\',testDigits(i).name);
Middle_text=textread(readname,'%s');%读取样本
Middle_text=cell2mat(Middle_text);
Middle_text=abs(Middle_text)-48;
test_Features(i,:)=reshape(Middle_text,[1,1024]);%将样本转化为1024维的向量
end
%% 读取训练样本及其标签
trainingDigits=dir('trainingDigits');
fprintf('Loading trainingDigits....\n');
trainingDigits(1:2,:)=[];%名字中带有表示此文件和上一文件夹的字符将其去掉
Cell_name={trainingDigits.name};%将单元数组中的某一字段取出放入一个单元数组中
Char_name=cell2mat(Cell_name);%将单元数组变成一字符串
index=regexpi(Char_name,'\d_\d');%利用正则表达式找到合适的字符
labels=Char_name(index);%利用索引将指定字符取出
train_Labels=abs(labels)-48;%获得样本的标签
size_trainingDigits=size(trainingDigits);
train_Features=zeros(size_trainingDigits(1),1024);
for i=1:size_trainingDigits(1)
readname=strcat('trainingDigits\',trainingDigits(i).name);
Middle_text=textread(readname,'%s');%读取样本
Middle_text=cell2mat(Middle_text);
Middle_text=abs(Middle_text)-48;
train_Features(i,:)=reshape(Middle_text,[1,1024]);%将样本转化为1024维的向量
end
%% 利用KNN算法进行预测
fprintf('正在进行计算\n');
test_Labels=Knn(test_Features,train_Features,train_Labels,3);
%计算错误率
error=0;
for i=1:size(test_Features,1)
% fprintf('识别数字为%d,实际数字为%d\n',test_Labels,test_real_Labels);%可以选择注释
if test_Labels(i)~=test_real_Labels(i)
error=error+1;
end
end
error_ratio=error/size(test_Features,1);
fprintf('选取的测试样本为%f\n',size(test_Features,1));
fprintf('错误的样本数为%d\n',error);
fprintf('错误率为%f\n',error_ratio);
function test_Labels=Knn(test_Features,train_Features,train_Labels,k)
% function :运用knn算法进行分类
% input: test_Features: train sample Features,m-by-p matrix
% train_Features: test sample Features,n-by-p matrix
% train_Labels: test sample labels ,n-by-1 vector
% k: the k in nearest neighbors
%
% output: test.Labels: the train sample labels,m-by-1 vector
%% 运用Knn算法进行预测
test_Labels=zeros(size(test_Features,1),1);
distance=Getdist(test_Features,train_Features,'o');
[~,index]=sort(distance,2);
for i=1:size(test_Features,1)
Labels=train_Labels(index(i,1:k));
tabLabels=tabulate(Labels);
[~,ind]=max(tabLabels(:,2));
test_Labels(i)=tabLabels(ind,1);
end
end
function dist=Getdist(start_matrix,end_matrix,method)
% Function : 根据参数method,计算两个矩阵之间的距离
% Input: start_matrix:The vector to calculate distance,a 1-by-p matrix
% end_matrix:The end matrix to calculate distance,a m-by-p matrix
% metho:To determine use which distance
%
%Output: dist:a matrix n-by-m matrix,one row is the vector to The end_matrix distance
%
%
%% 根据要求计算距离
size_start_matrix=size(start_matrix);
size_end_matrix=size(end_matrix);
dist=zeros(size_start_matrix(1),size_end_matrix(1));
switch method
case 'o'
for i=1:size_start_matrix(1)
dist(i,:)=sum((repmat(start_matrix(i,:),[size_end_matrix(1),1])-end_matrix).^2,2);
end
case 'm'
end
end
end代码和样本集的下载地址:http://download.csdn.net/detail/zhj_matlab/9666115
为了让这个算法更有趣,我用matlab写了个GUI,界面如下:
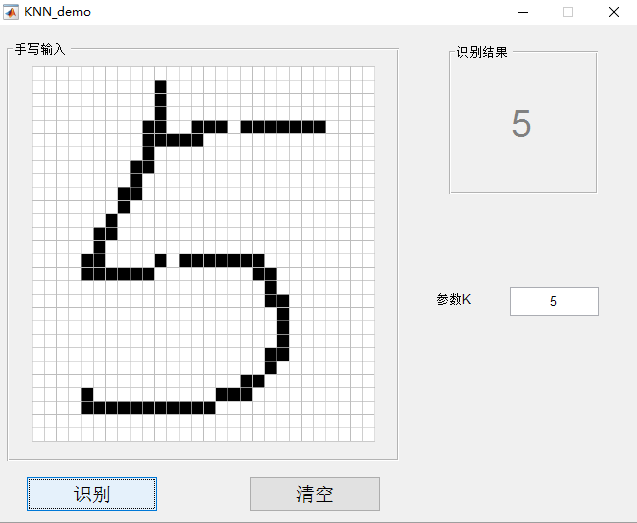
感兴趣的同学可以下载,也可以把识别方法改成其他算法,地址:
http://download.csdn.net/detail/zhj_matlab/9667174















 1835
1835











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









