







本文主要利用opencv读取摄像头的手势画面数据,利用mediapipe库提供的方法将手势图像画面转化为手部21个关节点的坐标值,通过坐标值的数理关系进行任意手势的识别。
通过mediapipe拿到21个手势关节点坐标后,对任意手势识别的方法有很多种,常见的方法是通过数学公司推导进行识别,比如计算某两两关节点的距离进行判别特定手势。本文打算另辟蹊径,通过采集大量手势的坐标点后,通过KNN近邻算法进行手势识别分类。这种方法的主要优点是不需要对新增手势进行特定的数学公式推导和代码编程,只需要采集新的手势坐标数据,在程序启动前,由KNN近邻算法重新训练一下即可适用,以下是我的代码实现部分:
1. 读取训练数据
笔者分别采集了石头剪刀布三个手势20余次的数据(如果有条件可以多采集一些),训练出来的准确率已经高达90%以上,完全够用。采集石头、剪刀、布三个手势的坐标值数据,写入csv文件中以供KNN算法训练,采集数据时,在摄像头前不同角度和远近重复三个手势,并标注手势的类别。
数据集及代码如下:
num, x_value, y_value, hand_result
0,0.5252603888511658,1.023892879486084,Cloth
1,0.48582276701927185,1.0048032999038696,Cloth
2,0.45390379428863525,0.9613886475563049,Cloth
...
20,0.6634553074836731,0.8075148463249207,Clothimport cv2
import mediapipe as mp
import time
import csv
import numpy as np
import pandas as pd
import math
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
def readData(path):
data = pd.read_csv(path,
encoding='utf8', engine='python')
data = np.array(data)
return data2. 数据预处理
因为手势判别只与各个关节点的坐标相对位置相关,与在屏幕上的绝对位置无关,故将21个点坐标转换手掌心节点与其余20个点的距离数据,方法很简单,并不会运用到太多的数据公式,通过勾股定理即可计算而得。
def tarinData2Distance(data, train=False):
if train == True:
target = data[:, -1]
for i in np.arange(len(target)):
if target[i] == "Cloth":
data[i][-1] = 0
elif target[i] == "Scissor":
data[i][-1] = 1
else:
data[i][-1] = 2
data = np.array(data, dtype='float')
num_x = 10
num_y = 10
list1 = []
for i in np.arange(np.shape(data)[0]):
list01 = []
if int(data[i][0]) == 0:
basex = data[i][1] * num_x
basey = data[i][2] * num_y
for j in np.arange(1, 21):
str01 = math.pow((basex - data[i + j][1] * num_x), 2) + math.pow((basey - data[i + j][2] * num_y), 2)
list01.append(str01)
if train:
list01.append(data[i][3])
list1.append(list01)
list1 = np.array(list1)
return list1识别过程中,采集到的手势数据也需要进行同样的预处理才能放到模型里进行判别
def imgData2Distance(landmark, img):
list1 = []
for i, lm in enumerate(landmark):
list01 = [i, lm.x, lm.y]
list1.append(list01)
xPos = int(lm.x * np.shape(img)[1])
yPos = int(lm.y * np.shape(img)[0])
print(i, xPos, yPos)
cv2.putText(img, str(i), (xPos - 25, yPos + 5), cv2.FONT_HERSHEY_SIMPLEX, 0.4, (0, 0, 255), 2) # 大小,颜色,粗度
return np.array(list1)3. 训练KNN模型
def trainKNNHand():
# 1.获取数据集
sorc = tarinData2Distance(readData(r".\\handeData.csv"), train=True)
data = sorc[:, 0:-1]
data = np.array(data, dtype='float')
target = sorc[:, -1]
target = np.array(target, dtype='float')
# 2. 数据集切分
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=666)
# 3.建立KNN模型
param_grid = [
{
'weights': ['uniform'], # 不考虑距离权重的模式
'n_neighbors': [i for i in range(1, 11)] # 邻近点的个数
},
{
'weights': ['distance'], # 考虑距离权重的模式
'n_neighbors': [i for i in range(1, 11)],
'p': [i for i in range(1, 6)] # 明可夫斯基距离参数 p = (0:曼哈顿距离, 1:欧拉距离)
}
]
knn_clf = KNeighborsClassifier() # 实例化 KNN 算法
grid_search = GridSearchCV(knn_clf, param_grid, n_jobs=-1, verbose=2) # n_jobs=-1 最大并行训练
grid_search.fit(X_train, y_train) # 针对训练数据进行最佳超参数搜索
best_estimator = grid_search.best_estimator_ # 这就是最终得到的最佳参数
best_score = grid_search.best_score_ # 使用上诉训练到的最佳参数得到的分类得分
print("模型训练得分{}".format(best_score))
print("模型参数{}".format(best_estimator))
# 5.使用并评估KNN模型
knn_clf = grid_search.best_estimator_
knn_clf.fit(X_train, y_train)
test_score_1 = knn_clf.score(X_test, y_test) # 可以直接通过KNeighborsClassifier内置函数得到分类得分
print("test_score_1 = {}".format(test_score_1)) # test_score_1 = 1.0
return knn_clf4. 手势判别
将上述步骤训练得到的模型运用到实时采集的摄像头画面中,即可对摄像头采集到的手势进行判别,注意opencv的 VideoCapture() 不仅可以读取摄像头画面数据,还可以读取视频文件,图片文件,只需在方法入参中传入相应文件的全路径加文件全名即可,非常方便,本文读取的是笔记本自带摄像头,只需在入参中填入数字0即可,如果是台式机也可加装USB摄像头进行试验。
通过mediapipe库提供的方法对视频图像数据进行手势21个关节点的坐标读取,顺便说一句,mediapipe不仅可以实现手势识别,还能进行人脸检测、人脸识别、姿势识别、眼动识别。
如下所示:
def handIdentify():
cap = cv2.VideoCapture(0)
mpHands = mp.solutions.hands
hands = mpHands.Hands(
static_image_mode=False, # 是否为静态图片
max_num_hands=2, # 最大识别手的数量
model_complexity=1, # 模型置信度
min_detection_confidence=0.5, # 侦测置信度
min_tracking_confidence=0.5) # 追踪置信度
mpDraw = mp.solutions.drawing_utils
handLmsStyle = mpDraw.DrawingSpec(color=(0, 0, 255), thickness=5)
handConStyle = mpDraw.DrawingSpec(color=(255, 0, 0), thickness=10)
pTime = 0
while True:
ret, img = cap.read() # ret 代表是否读到图片(Boolean), img表示截取到的一帧的图片数据
if ret:
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = hands.process(imgRGB) # 手势识别的结果数据
if result.multi_hand_landmarks:
for handLms in result.multi_hand_landmarks:
mpDraw.draw_landmarks(img, handLms, mpHands.HAND_CONNECTIONS, handLmsStyle, handConStyle)
list1 = imgData2Distance(handLms.landmark, img)
x_data = tarinData2Distance(list1, train=False)
hand_num = knn_clf.predict(x_data)
if hand_num == 0:
hand_type = 'Cloth'
elif hand_num == 1:
hand_type = 'Scissor'
else:
hand_type = 'Stone'
xPos = int(list1[0][1] * np.shape(img)[1])
yPos = int(list1[0][2] * np.shape(img)[0])
cv2.putText(img, hand_type, (xPos, yPos), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
print("此图识别到的手势是{}".format(hand_type))
cTime = time.time()
fps = 1 / (cTime - pTime)
pTime = cTime
cv2.putText(img, f"FPS:{int(fps)}", (30, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0))
cv2.imshow('img', img)
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
knn_clf = trainKNNHand()
handIdentify()5. 总结
通过opencv读取图像数据,使用mediapipe识别手势图像21个坐标点,通过求掌心坐标点与其余20个关键坐标点的距离作为20个特征值形成训练数据,使用KNN算法对数据进行分类判别,能够有效识别石头剪刀布三个手势,如果读者感兴趣的话,还可以基于以上代码做一个与机器人对玩石头剪刀布的程序。最终效果如下所示:
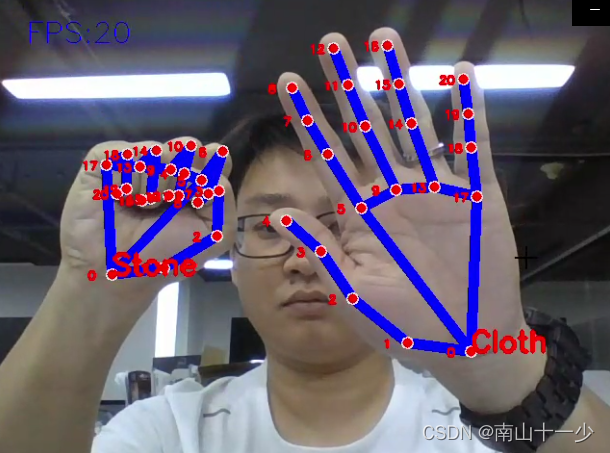
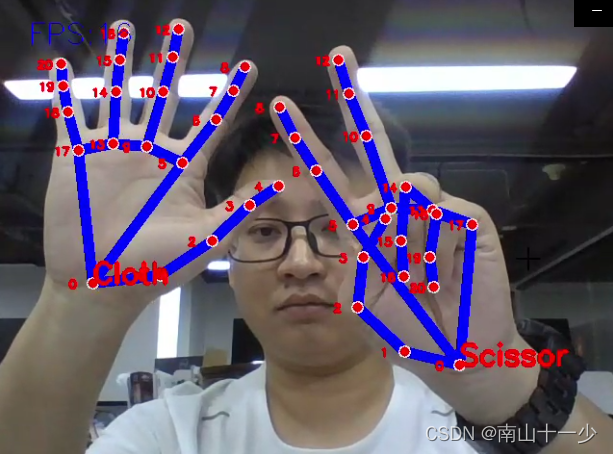

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









