









 本文介绍使用DeepQNetwork(DQN)算法使机器学习玩Connect4和乒乓球游戏的项目。项目分为游戏、算法和交互三部分,重点介绍了游戏规则、奖励设置、自我对战训练策略以及算法如何与游戏互动。
本文介绍使用DeepQNetwork(DQN)算法使机器学习玩Connect4和乒乓球游戏的项目。项目分为游戏、算法和交互三部分,重点介绍了游戏规则、奖励设置、自我对战训练策略以及算法如何与游戏互动。
这个项目用三篇文章进行介绍,各部分的内容如下:
项目实战:使用Deep Q Network(DQN)算法让机器学习玩游戏(一):总体介绍,游戏部分
项目实战:使用Deep Q Network(DQN)算法让机器学习玩游戏(二):算法部分
项目实战:使用Deep Q Network(DQN)算法让机器学习玩游戏(三):算法和游戏的交互部分,模型训练,模型评估,使用相同的算法和参数去玩另外一个不同的游戏
在这个项目中,我们使用Deep Q Network(DQN)算法来让机器学习玩游戏。DQN算法的介绍请参考这里。我们选择两个游戏来进行训练:connect 4(类似五子棋)和乒乓球。
项目的目标是通过训练让机器学会玩这些游戏,类似deep mind 团队训练AlphaGo学习玩围棋一样。项目的输入数据只是游戏界面的图片,没有其他的游戏数据,就和人类玩游戏所能得到的数据一样。同时,算法部分可以不需要修改网络结构和参数就能适用于不同的游戏。由于项目的输入数据是图像,所以在神经网络方面选择CNN算法。
整个项目被分成三个部分:游戏部分,算法部分,游戏与算法的交互部分。下面分别介绍这三个部分。
(一)游戏部分
游戏介绍
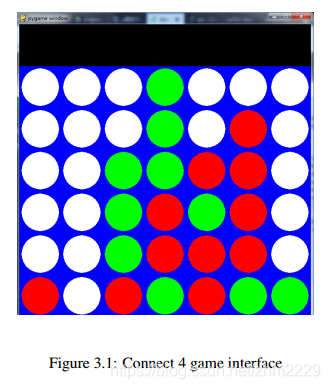
棋盘类游戏一直是ai领域研究的热点,由于它涉及到人类智能,优化问题等,而且很多棋盘类游戏的状态空间很,棋盘问题一直是一个较大的挑战。由于我们的训练资源没有deep mind这样的大公司那么多,所以只能选择状态空间稍微小一点的connect 4游戏。下图是connect 4的游戏界面。游戏部分是用用python中的pygame库开发的,这部分功能在下文中会介绍。它是一个两个玩家的游戏,类似于五子棋,只不过是一个垂直的棋盘,一共有6行7列,每次可以选择一列投入棋子,由于重力原因,棋子会落到最下面的那个空位置。相同颜色的棋子在横向,纵向,斜向上连成4个则这个玩家获胜。如果棋盘满了,还没有玩家能连成4个,则是平局。如果一列满了,而玩家还选择这列投入棋子,则被定义为illegal move。
由于精确计算游戏的状态空间比较复杂,我们可以简单计算一下理论上的最大状态数,由于有42个格子,每个格子都可能有红色,绿色或者空三种状态,所以这个游戏理论上最大的状态数是3的42次方。
reward设置
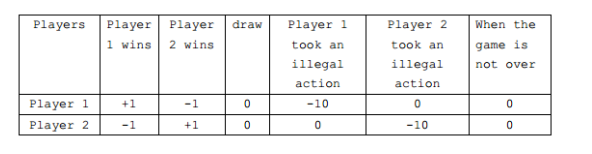
从强化学习的基础知识中可知,当agent在环境中采取一个action的时候,环境会返回一个reward,对于这个游戏,reward的设置如下:
如果玩家获胜,则得到1分,输了则获得-1分,如果平局,则两个玩家都是0分。为了防止玩家将棋子下到棋盘外面,我们对illegal move设置了一个很大的惩罚值-10分。以上这些状态都会导致一局游戏结束,如果在游戏没有结束的步骤中,两个玩家每走一步获得的reward都是0.
由于connect 4 是一个两个玩家的游戏,我们需要对手的数据才能组成一个完整的游戏环境。对手游戏数据的获取一般有3种方式:人类的经验数据,random-play, self-play.
使用人类的经验数据需要对这个领域非常了解,另外,特征和规则提取也是一个非常耗时的过程。而且这种经验数据不能再使用到其他游戏上,所以我们不使用经验数据进行训练。
random-play是指每次从可能的动作中随机选择一个动作。这类似与不会下棋的小朋友一起下棋一样。它不能判断哪个位置是最好的,所以它的水平不是很高,一般来说低于人类的平均水平。另外random player和普通人类玩家下棋的方式不一样,通过和它对战学到的技能可能不能完全适用于真正的人类对手。
self-play是指我们将模型复制一份,让两个玩家使用两个相同的模型相互对战,相互学习提升。由于self-play不需要人类的经验数据,所以它的泛化性更好。此外,它不是基于人类的经验,而是基于自己的经验,所以它有可能会学习到人类以前不知道的经验。但是,self-play也有一些缺点,比如在最开始的时候,两个模型都不知道怎么去下棋,它们会大概率地随机选择动作,这会花费比较长的时间去学习。此外,由于它没有从高水平的人类选手那里学习,所以当它碰到高水平的人类选手时,有可能不知道如何选择最优的动作。
结合上面的原因,我们在训练阶段会选择self-play的方式来产生对手的训练数据。
使用pygame来开发游戏功能
游戏部分主要功能:
1. 初始化
初始化各种状态值,在画布上画42个圆形,每个圆形中是一个棋子位置。最开始的时候42个棋子的值初始化为0,棋子的颜色用白色表示。
2. 走一步棋
当从神经网络处获得下棋的位置的时候,会在游戏中执行这个动作,并判断游戏是否结束及各个玩家的reward。
首先判断这一列是否还有空位置,如果没有则棋子会落在棋盘外面,被定义为illegal move,玩家会被赋予相应的reward。
如果这一列还有空位置,获取最小面一行的值,将对应这行这列的位置的值置为对应玩家的值。
判断是否有人获胜及游戏是否结束。当游戏结束时,有三种状态,平局,玩家1胜,玩家2胜,赋予两个玩家对应的状态和reward值。如果没有结束,两个玩家的reward值都为0.
def make_move_p1(self, player, col, print_flag):
# returns observation, reward, done, info
self.turn_counter = 1
done = False
self.P1_reward = 0
self.P2_reward = 0
self.draw_board()
pygame.display.update()
selected_row = self.field[:, col]
# 如果这一列没有空位置,则棋子会出棋盘,为非法动作,会给一个很大的惩罚reward,让agent以后学会避免这种操作
if (selected_row == 0).any() == 0:
observation = self.image_data
done = True
self.P1_reward = self.illegal_reward
self.P1_illegal = 1
self.P2_win = 0
self.P1_info = [self.P1_win, self.P1_draw, self.P1_lose, self.P1_illegal, col, self.field, self.P2_win,
self.P2_draw, self.P2_lose, self.P2_illegal]
if print_flag == 1:
print("player 1 run an illegal action")
return observation, self.P1_reward, self.P2_reward, done, self.P1_info
# first nonzero entry starting from the bottom
next_empty_space = (selected_row != 0).argmin()
self.field[next_empty_space, col] = player
if print_flag == 1:
self.draw_board()
observation = self.image_data
# 判断这一步是否有人获胜
winner = self.check_win() # check winner every played move
if winner != 0:
# 平局
if winner == 3:
if print_flag == 1:
print("It's a tie!")
self.reset()
done = True
self.P1_draw = 1
self.P2_draw = 1
self.P1_reward = self.draw_reward
self.P2_reward = self.draw_reward
else:
# player 1 赢,player 2 输
if winner == 1:
self.P1_reward = self.win_reward
self.P2_reward = self.lose_reward
self.P1_win = 1
self.P2_lose = 1
# player 2 赢, player 1 输
else:
self.P1_reward = self.lose_reward
self.P2_reward = self.win_reward
self.P1_lose = 1
self.P2_win = 1
if print_flag == 1:
print("Player {} wins".format(winner))
done = True
self.P1_info = [self.P1_win, self.P1_draw, self.P1_lose, self.P1_illegal, col, self.field, self.P2_win, self.P2_draw, self.P2_lose, self.P2_illegal]
#返回游戏的画面,两个玩家的reward,游戏是否结束,其他信息
return observation, self.P1_reward, self.P2_reward, done, self.P1_info3. 判断哪个玩家获胜
如果某一个颜色的棋子在6*7的棋盘上在横向,纵向,斜线4个方向上连成4个,则对应的玩家获胜。
简单的判断方法是先逐行扫描是否存在四连,然后逐列扫描是否存在四连,然后再在斜线方向扫描是否存在四连。这种方法计算量比较大,效率比较低。我们采用一种卷积的方法来判断是否存在4个连着的棋子。
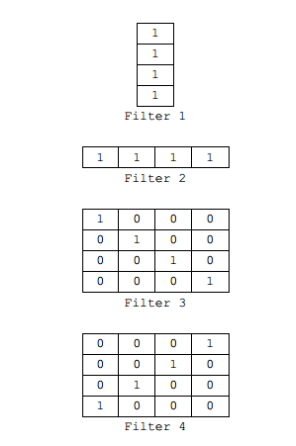
我们使用下面4个filter,
假设玩家1在棋盘上的棋子如下所示
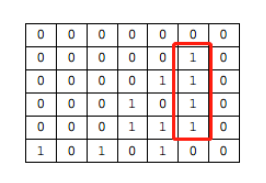
我们用4个filter和棋盘矩阵做卷积计算,卷积的计算方法请见卷积神经网络介绍。如果计算的结果为4,则说明棋盘上存在4连。例如棋盘上红框标注的位置,有4个连着的1,说明存在4连。当它和第一个filter做卷积计算时,计算的结果是1*1+1*1+1*1+1*1=4,则可以检测出4连,这个玩家获胜。
在每个玩家的每一步都用调用这个函数去进行游戏结果判断,然后返回给执行动作的函数。
def check_win(self):
# 使用卷积的方法来判断是否存在玩家获胜,如果结果中有4出现,则说明该玩家存在4个连着的棋子
mask = np.zeros(shape=(self.row_size, self.col_size), dtype=int)
if self.turn_counter % 2:
mask[self.field == 1] = 1
possible_winner = 1
else:
mask[self.field == 2] = 1
possible_winner = 2
if self.turn_counter == self.col_size * self.row_size:
return 3
k1 = np.array([[1], [1], [1], [1]])
k2 = np.array([[1, 1, 1, 1]])
k3 = np.array([[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]])
k4 = np.array([[0, 0, 0, 1], [0, 0, 1, 0], [0, 1, 0, 0], [1, 0, 0, 0]])
conv_vertical = convolve(mask, k1, mode='constant', cval=0)
if 4 in conv_vertical:
return possible_winner
conv_vertical = convolve(mask, k2, mode='constant', cval=0)
if 4 in conv_vertical:
return possible_winner
conv_vertical = convolve(mask, k3, mode='constant', cval=0)
if 4 in conv_vertical:
return possible_winner
conv_vertical = convolve(mask, k4, mode='constant', cval=0)
if 4 in conv_vertical:
return possible_winner
return 0
算法部分请见第二篇文章。
完整的代码请见:https://github.com/zm2229/use-DQN-to-play-a-simple-game

















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









