






2016中国Spark技术峰会最早发起时间可以归结到2015年底,那时恰逢Reynold Xin(辛湜,Databricks联合创始人兼Apache Spark首席架构师)回国在CSDN参办的BDTC 2015(中国大数据技术大会,今年会在12月左右举办)上进行主题演讲。当时Reynold的时间很紧,我们只能约好在他演讲结束后进行交流,而令人意想不到的是,在Reynold分享结束后,十多个人围了上来,Spark实在太热了。因此,我们只能推后了Spark峰会的交流时间,另约了晚上。
在晚上见面时,Reynold首先就透露了这个信息,“对于峰会的目标,应该是通过优质内容聚集起一波Sparker,让大家可以充分的交流”,因此应该满足两个需求:第一,内容要干;其次,社区用户的聚会。对于第一个需求,过去两届的峰会已经证明了一切,而在2016中国Spark技术峰会上,在Reynold和七牛云技术总监陈超的严格把关下,不仅有3位Apache Spark Committer Ram Sriharsha、连城、范文臣为大家解析Spark 2.0,来自Intel、Hortonworks、Elastic、腾讯、新浪微博、Admaster、MediaV等国内外机构的9位专家将带来最新的Spark实践分享,详情可以看笔者之前的峰会解析,也可以前往峰会官网。而对于第二个需求,首先CSDN一直是一个面向开发者的社区,其次CSDN更是各个技术发烧友的殿堂,尤其是Sparker,因此除下峰会这个Sparker Party之外,我们还为对Spark感兴趣的同学提供了一条从小兵到专家的成长之路。
Spark零基础入门——约每周一节

本系列课程由绿城集团数据中心平台架构师、数据开发主管周志湖讲述,共分为两个部分,Scala入门知识与Spark入门知识,总计20节左右。其中Scala部分共9节,已经结束,视频回顾可以查看这里Spark零基础入门之Scala;Spark入门部分已经进入到第二期,报名和往期录像可以点击这里Spark零基础入门之Spark。
Spark线上峰会——每周一位大牛,统一报名入口,持续添加===》点击传送
入门之外,从本周起,CSDN每周都会为大家准备一场Spark技能提升课程,讲课嘉宾来自国内外知名大数据公司的资深实践者,也是对因为种种原因无法到现场同学的一种弥补,下面看详细内容。
1.TalkingData研发副总裁阎志涛:Spark在TalkingData移动大数据平台的实践——4月27日

议题简介: 2013年9月份,TalkingData开始尝试使用Spark解决数据挖掘性能问题。随着对Spark的逐渐了解,TalkingData开始将Spark应用到整个移动大数据平台的建设中。在移动大数据平台中,ETL过程、计算过程、数据挖掘、交互式数据提取等等都依赖于Spark。在这里,我将要介绍我们使用Spark的状况、平台架构、以及一些实践经验。当然也包括一些总结的最佳实践。统一报名入口,持续添加===》点击传送
2.乐视云计算资深数据工程师祝海林:Spark Streaming 常见的坑——5月5日

祝海林,现就职于乐视云计算,资深数据工程师。从事大数据平台架构相关工作,现专注在机器学习/数据查询分析领域。对Spark/ES较为熟悉,业余时间喜欢研究通用资源管理相关课题
议题简介:正在实践的一些Spark Streaming使用场景;Streaming一些常见的bug,以及一些feature的改进;Spark Streaming reciver的一些探讨;自研的Spark Streaming开发框架介绍:完全配置化、支持热加载,只关注逻辑处理、无需关注Spark Streaming初始化、checkpoint等,集成spark sql的支持。
3.AdMaster架构师刘喆:基于 Spark Streaming 的实时处理研究——5月10日

刘喆(Zhe Liu)2013年加入AdMaster,现任架构师。主要负责数据处理的全流程技术支持, 高性能和高可用的分布式架构设计, DSL 语言抽象, Hadoop/HBase/Storm/Spark等大数据平台优化。2010年硕士毕业后, 刘喆在百度就职, 负责当时全球规模最大的 hadoop 平台的运维开发工作. 2011年底加入人民搜索, 代理运维总监。近 7 年的大学生活和近 5 年的工作经历中, 刘喆一直在追求简单直接,关注于数据挖掘/大数据/DSL/系统架构, 对分布式计算/分布式架构和程序语言情有独钟, 曾多次被51CTO/spark 峰会/into100峰会等邀请为嘉宾分享Hadoop/spark/开源软件等相关经验。
议题简介:基于 Spark Streaming 的实时处理研究,分享主要涉及以下内容:实时系统构架设计、开源组件选择、逻辑开发注意事项、Spark Streaming 的适用性和坑、AdMaster 的实际应用案例。
4.GrowingIO田毅:Spark多数据源处理——5月12日

田毅,目前在数据分析服务公司GrowingIO数据平台部门工作,Spark社区的Contributor,北京Spark Meetup组织者,2010年开始在电信领域实践应用hadoop,2013年开始关注Spark,从Shark开始向社区贡献代码。目前主要的研究方向是使用Spark搭建企业级的数据计算分析平台。
议题简介:随着数据量的不断增加,企业越来越重视大数据处理的成本问题,越来越多的公司开始结合自己的业务特点,试用不同的存储方式来满足不同的应用场景。
但是数据的计算和分析往往要放在一起才能更加高效和灵活。
本次分享主要介绍一下如何通过Spark的DataSource API快速的读写外部数据源中的数据,并结合一些具体场景来分析和解释使用DataSource API的好处以及需要注意的问题,提纲如下:为什么需要多种数据源、Spark多数据源的实现机制、几个常用的数据源简介、GrowingIO使用案例。
5.黄忠:基于Spark的特征平台打造——5月19日

黄忠,目前主要从事数据挖掘及大数据平台等相关工作,Spark技术实践和研究者,多次担任Spark线下公开课讲师,曾参与云平台,分布式爬虫,推荐系统等项目。乐于学习和分享,业余维护个人原创公众号sparking。
议题简介: 主要介绍特征平台的设计,实现和应用,并分析实现过程中的技术细节和Spark相关问题。
机器学习的应用越来越广泛,互联网企业不论大小,都要满足用户的诉求,不论是个性化的推荐,还是精准的广告,又或者是满意的搜索,都离不开机器学习。特征平台给各类机器学习工程师提供了数据的入口,这里以用户特征为例,介绍了用户特征平台的数据来源,特征提取,特征处理,特征合并,特征转换等,特征提取主要通过MR的任务按天、月、年完成调度,特征处理、合并、转换等则主要是通过Spark任务完成,特征是以配置文件的方式添加和删除。
6.Hortonworks技术专家梁堰波:深入理解Spark MLlib——5月26日

梁堰波,Hortonworks技术专家,曾明略数据技术合伙人,更早的时候还曾就职于France Telecom、美团、Yahoo!等企业。梁堰波是Spark活跃贡献者,主要聚焦Spark ML/MLlib和SparkR项目,精通统计和机器学习算法在类似Spark这样分布式系统上的实现。
7.Alluxio活跃贡献者顾荣:开源大数据存储系统Alluxio(原Tachyon)的原理分析与案例简介——6月2日

顾荣,南京大学计算机系博士生,Alluxio项目核心开发者。完成了Alluxio很多功能/性能增强的工作,并主持实现性能测试框架和社区中文文档等。顾荣曾在微软亚洲研究院、英特尔、百度、星环科技从事大数据系统相关的研发工作
议题简介: Alluxio(原名Tachyon)是以内存为中心的虚拟的分布式存储系统。它统一了数据访问方式,构建了计算框架和存储系统的桥梁。它以内存为中心的架构使得数据的访问速度比常规方案快几个数量级。Alluxio是伯克利大数据分析软件栈中的存储层软件, 也是 Fedora发行版的一部分。自今年2月发布1.0版本的过去三年以来,全球已有超过50个组织机构的 200多贡献者参与到项目开发。在分享中,我将介绍Alluxio的演变历程以及1.0版本的新特性和工作原理,以及一些使用案例。
8. 亚信数据橘云大数据平台技术经理王庚:分布式资源管理系统的前世今生,深入剖析YARN资源调度架构——6月9日

王庚,目前就职于亚信数据,担任橘云大数据平台技术经理。西北工业大学硕士,曾经就职于腾讯,从事网络负载均衡,数据中心系统的研发工作;之后加入IBM Platform Computing,从事大数据产品Platform Symphony的研发工作。
议题简介: Hadoop项目发展至今,经历了第一代MapReduce作业调度与资源管理紧耦合,到第二代Hadoop解耦了资源管理模块YARN,从而作为资源调度器支持多种类型作业(包括新一代大数据引擎Spark)。YARN因为统一的资源管理,灵活可插拔的资源调度器以及支持多维度的资源定义等特性,使之成为大数据社区最活跃的组件之一。此次主题将会介绍分布式资源管理的发展历程,介绍Hadoop YARN功能模块以及架构,以及亚信数据对于YARN的资源管理优化实践——Jaguar项目。
Spark知识库——你身边的技术百科全书
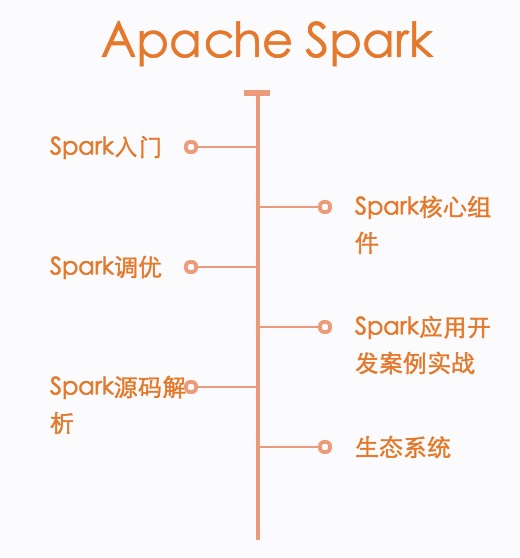
CSDN知识库致力于以可视化方式展示各技术领域的整体架构,并依据每个领域的分支脉络提供该领域最优质的精华学习资源。学习资源经特邀编辑一一审核、精心挑选,呈现给广大技术开发者,以期为开发者提供工作学习中的案头手册,解决日常技术困惑,实现自我提升。Sparker看这里。
CSDN在线问答——下周开始持续一周
微信群“CSDN Spark聚集地”汇聚了全国顶尖的Spark技术专家,入群请加微信号zhongyineng。PS,一群已满。
未完待续,更多精彩内容只在www.csdn.net。
2016年5月13日-15日,由CSDN重磅打造的2016中国云计算技术大会(CCTC 2016)将于5月13日-15日在北京举办,今年大会特设“中国Spark技术峰会”、“Container技术峰会”、“OpenStack技术峰会”、“大数据核心技术与应用实战峰会”四大技术主题峰会,以及“云计算核心技术架构”、“云计算平台构建与实践”等专场技术论坛。大会讲师阵容囊括Intel、微软、IBM、AWS、Hortonworks、Databricks、Elastic、百度、阿里、腾讯、华为、乐视、京东、小米、微博、迅雷、国家电网、中国移动、长安汽车、广发证券、民生银行、国家超级计算广州中心等60+顶级技术讲师,CCTC必将是中国云计算技术开发者的顶级盛会。目前会议门票限时7折(截止至4月29日24点),详情访问CCTC 2016官网。















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









