







本文作者:田毅,目前在数据分析服务公司GrowingIO数据平台部门工作,Spark社区的Contributor,北京Spark Meetup组织者,2010年开始在电信领域实践应用hadoop,2013年开始关注Spark,从Shark开始向社区贡献代码。目前主要的研究方向是使用Spark搭建企业级的数据计算分析平台。
责任编辑:仲浩(zhonghao@csdn.net)
本文为《程序员》原创文章,未经允许不得转载,更多精彩文章请订阅2016年《程序员》
本文主要介绍如何使用Apache Spark中的DataSource API以实现多个数据源混合计算的实践,那么这么做的意义何在,其主要归结于3个方面:
- 首先,我们身边存在大量的数据,结构化、非结构化,各种各样的数据结构、格局格式,这种数据的多样性本身即是大数据的特性之一,从而也决定了一种存储方式不可能通吃所有。因此,数据本身决定了多种数据源存在的必然性。
- 其次:从业务需求来看,因为每天会开发各种各样的应用系统,应用系统中所遇到的业务场景是互不相同的,各种各样的需求决定了目前市面上不可能有一种软件架构同时能够解决这么多种业务场景,所以在数据存储包括数据查询、计算这一块也不可能只有一种技术就能解决所有问题。
- 最后,从软件的发展来看,现在市面上出现了越来越多面对某一个细分领域的软件技术,比如像数据存储、查询搜索引擎,MPP数据库,以及各种各样的查询引擎。这么多不同的软件中,每一个软件都相对擅长处理某一个领域的业务场景,只是涉及的领域大小不相同。因此,越来越多软件的产生也决定了我们所接受的数据会存储到越来越多不同的数据源。
Apache Spark的多数据源方案
传统方案中,实现多数据源通常有两种方案:冗余存储,一份业务数据有多个存储,或者内部互相引用;集中的计算,不同的数据使用不同存储,但是会在统一的地方集中计算,算的时候把这些数据从不同位置读取出来。下面一起讨论这两种解决方案中存在的问题:
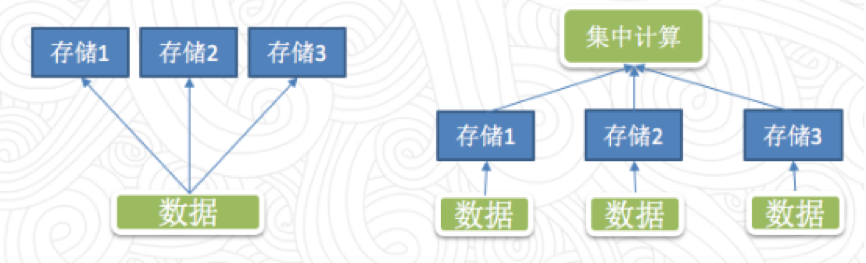
第一种方案中存在的一个问题是数据一致性,一样的数据放在不同的存储里面或多或少会有格式上的不兼容,或者查询的差异,从而导致从不同位置查询的数据可能出现不一致。比如有两个报表相同的指标,但是因为是放在不同存储里查出来的结果对不上,这点非常致命。第二个问题是存储的成本,随着存储成本越来越低,这点倒是容易解决。
第二种方案也存在两个问题,其一是不同存储出来的数据类型不同,从而在计算时需求相互转换,因此如何转换至关重要。第二个问题是读取效率,需要高性能的数据抽取机制,尽量避免从远端读取不必要的数据,并且需要保证一定的并发性。
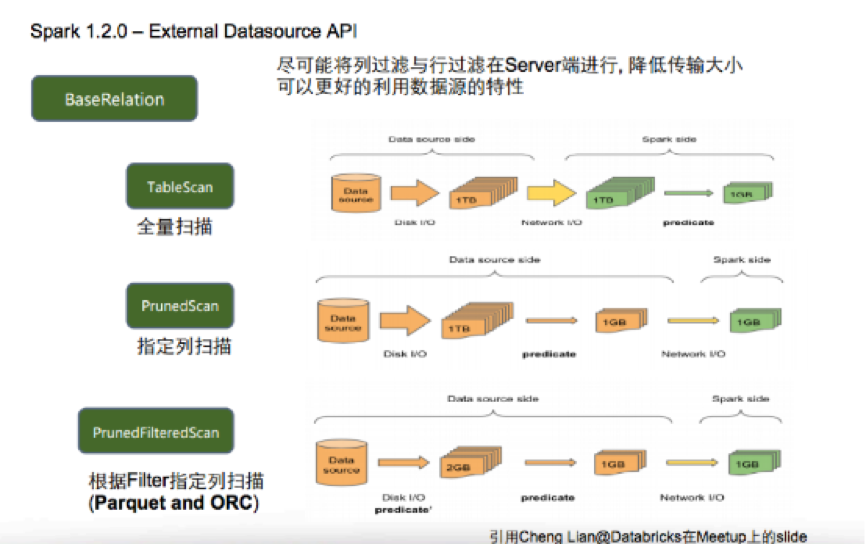
Spark在1.2.0版本首次发布了一个新的DataSourceAPI,这个API提供了非常灵活的方案,让Spark可以通过一个标准的接口访问各种外部数据源,目标是让Spark各个组件以非常方便的通过SparkSQL访问外部数据源。很显然,Spark的DataSourceAPI其采用的是方案二,那么它是如何解决其中那个的问题的呢?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5966
5966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









