







dataframe是在spark1.3.0中推出的新的api,这让spark具备了处理大规模结构化数据的能力,在比原有的RDD转化方式易用的前提下,据说计算性能更还快了两倍。spark在离线批处理或者实时计算中都可以将rdd转成dataframe进而通过简单的sql命令对数据进行操作,对于熟悉sql的人来说在转换和过滤过程很方便,甚至可以有更高层次的应用,比如在实时这一块,传入kafka的topic名称和sql语句,后台读取自己配置好的内容字段反射成一个class并利用出入的sql对实时数据进行计算,这种情况下不会spark streaming的人也都可以方便的享受到实时计算带来的好处
下面的示例为读取本地文件成rdd并隐式转换成dataframe对数据进行查询,最后以追加的形式写入mysql表的过程,scala代码示例如下
import java.sql.Timestamp
import org.apache.spark.sql.{SaveMode, SQLContext}
import org.apache.spark.{SparkContext, SparkConf}
object DataFrameSql {
case class memberbase(data_date:Long,memberid:String,createtime:Timestamp,sp:Int)extends Serializable{
override def toString: String="%d\t%s\t%s\t%d".format(data_date,memberid,createtime,sp)
}
def main(args:Array[String]): Unit ={
val conf = new SparkConf()
conf.setMaster("local[2]")
// ----------------------
//参数 spark.sql.autoBroadcastJoinThreshold 设置某个表是否应该做broadcast,默认10M,设置为-1表示禁用
//spark.sql.codegen 是否预编译sql成java字节码,长时间或频繁的sql有优化效果
// spark.sql.inMemoryColumnarStorage.batchSize 一次处理的row数量,小心oom
//spark.sql.inMemoryColumnarStorage.compressed 设置内存中的列存储是否需要压缩
// ----------------------
conf.set("spark.sql.shuffle.partitions","20") //默认partition是200个
conf.setAppName("dataframe test")
val sc = new SparkContext(conf)
val sqc = new SQLContext(sc)
val ac = sc.accumulator(0,"fail nums")
val file = sc.textFile("src\\main\\resources\\000000_0")
val log = file.map(lines => lines.split(" ")).filter(line =>
if (line.length != 4) { //做一个简单的过滤
ac.add(1)
false
} else true)
.map(line => memberbase(line(0).toLong, line(1),Timestamp.valueOf(line(2)), line(3).toInt))
// 方法一、利用隐式转换
import sqc.implicits._
val dftemp = log.toDF() // 转换
/*
方法二、利用createDataFrame方法,内部利用反射获取字段及其类型
val dftemp = sqc.createDataFrame(log)
*/
val df = dftemp.registerTempTable("memberbaseinfo")
/*val sqlcommand ="select date_format(createtime,'yyyy-MM')as mm,count(1) as nums " +
"from memberbaseinfo group by date_format(createtime,'yyyy-MM') " +
"order by nums desc,mm asc "*/
val sqlcommand="select * from memberbaseinfo"
val sel = sqc.sql(sqlcommand)
val prop = new java.util.Properties
prop.setProperty("user","etl")
prop.setProperty("password","xxx")
// 调用DataFrameWriter将数据写入mysql
val dataResult = sqc.sql(sqlcommand).write.mode(SaveMode.Append).jdbc("jdbc:mysql://localhost:3306/test","t_spark_dataframe_test",prop) // 表可以不存在
println(ac.name.get+" "+ac.value)
sc.stop()
}
}上面代码textFile中的示例数据如下,数据来自hive,字段信息分别为 分区号、用户id、注册时间、第三方号
20160309 45386477 2012-06-12 20:13:15 901438
20160309 45390977 2012-06-12 22:38:06 901036
20160309 45446677 2012-06-14 21:57:39 901438
20160309 45464977 2012-06-15 13:42:55 901438
20160309 45572377 2012-06-18 14:55:03 902606
20160309 45620577 2012-06-20 00:21:09 902606
20160309 45628377 2012-06-20 10:48:05 901181
20160309 45628877 2012-06-20 11:10:15 902606
20160309 45667777 2012-06-21 18:58:34 902524
20160309 45680177 2012-06-22 01:49:55
20160309 45687077 2012-06-22 11:23:22 902607这里注意字段类型映射,即case class类到dataframe映射,从官网的截图如下
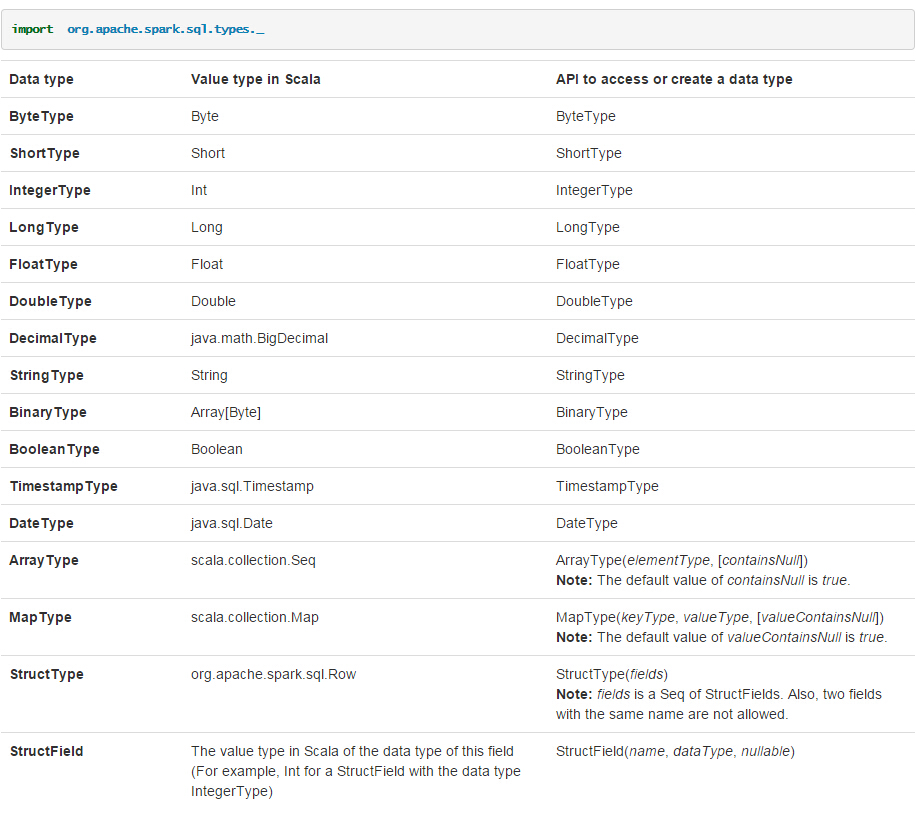
更多明细可以查看官方文档Spark SQL and DataFrame Guide















 1966
1966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









