







CNN
cnn每一层会输出多个feature map, 每个Feature Map通过一种卷积滤波器提取输入的一种特征,每个feature map由多个神经元组成,假如某个feature map的shape是m*n, 则该feature map有m*n个神经元。对于卷积层会有kernel, 记录上一层的feature map与当前层的卷积核的权重,因此kernel的shape为(上一层feature map的个数,当前层的卷积核数)。本文默认子采样过程是没有重叠的,卷积过程是每次移动一个像素,即是有重叠的。默认子采样层没有权重和偏置。关于CNN的其它描述不在这里论述,可以参考一下参考文献。只关注如何训练CNN。
CNN网络结构
一种典型卷积网络结构是LeNet-5,用来识别数字的卷积网络。结构图如下(来自Yann LeCun的论文):
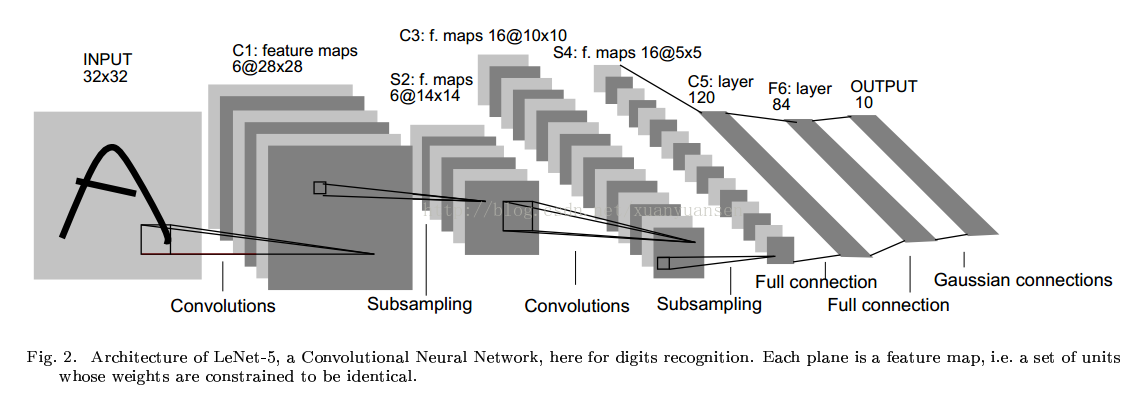
在卷积神经网络算法的一个实现文章中,有一个更好看的图:

该图的输入是一张28*28大小的图像&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









