简单总结一下以上的几个结论,Serrano[4]围绕着中间表示擦除设计了多组实验,观察模型决策的变化,得到的结论是:‘Attention does not necessarily correspond to importance.’,因为实验中Attention常常无法成功地识别能影响模型决策的最重要的中间表示。另外,有一个比较重要但是没有经过实验验证的小猜想:‘Attention magnitudes do seem more helpful i uncontextualized cases.’,也就是说,可能是上下文相关的编码器导致了Attention机制难以解释,但是作者并未对此进行深入研究。
‘Only weakly and inconsistenly’,Attention权重与特征的重要度指标(梯度分布、删去某个中间表示后模型结果变化程度TVD分布)的相关度并不大,并且不稳定;
‘It is very possible to construct adversarial attention distributions that yield effectively equivalent predictions.’,很容易就能构造出与原始权重关注特征完全不同的对抗权重,更进一步而言,随机设置权重往往不会对模型决策结果有太大影响。
3.2 Not Not Explanation
这一部分的标题是Not Not Explanation,是对之前关于Attention机制不可解释论证的反驳,而不是证明了Attention可解释,这里主要参考了Wiegreffe[6]对Jain[5]的反驳。Wiegreffe[6]主要给出了两个理由:
Attention Distribution is not a Primitive. Attention权重分布不是独立存在的,由于经历了前向传播和反向传播的整个过程,Attention层的参数是无法同整个模型隔离开的,不然就失去了实际的意义;
Existence does not Entail Exclusivity. Attention分布的存在并不蕴含着排他性,Attention只是提供一个解释而不是提供唯一的解释。尤其是当中间表示的向量维度很大而输出结果的类别很少时,降维的映射函数很容易就有较大的灵活性。
Uniform as Adversary 训练一个将Attention权重固定为均值的baseline来模型;
Variance with a Model 用随机种子初始化重新训练来作为Attention权重分布偏差的正常基准;
Diagnosing Attention Distribution by Guiding Simpler Models 实现一个利用的固定住的预训练Attention权重的诊断框架;
Training an Adversary 设计一个end-to-end的对抗权重训练方法,需要注意的是这不是一个独立的实验,而是上一个实验的对抗权重生成的具体实现。
图13 使用的模型结果和对照实验部分
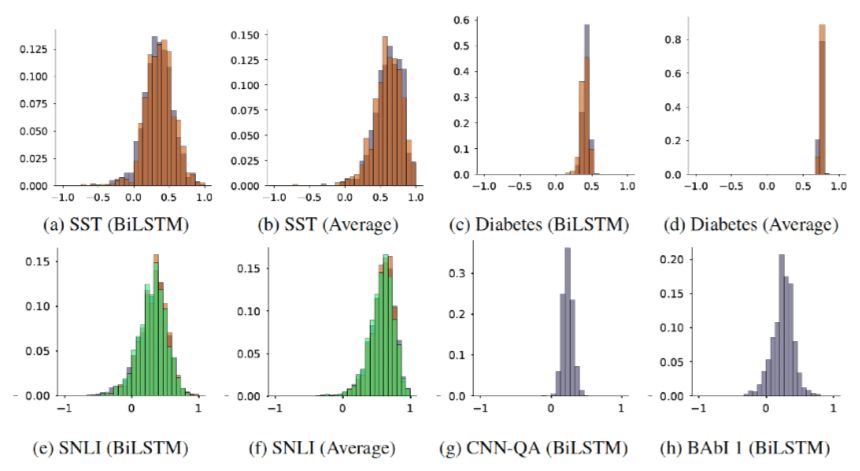
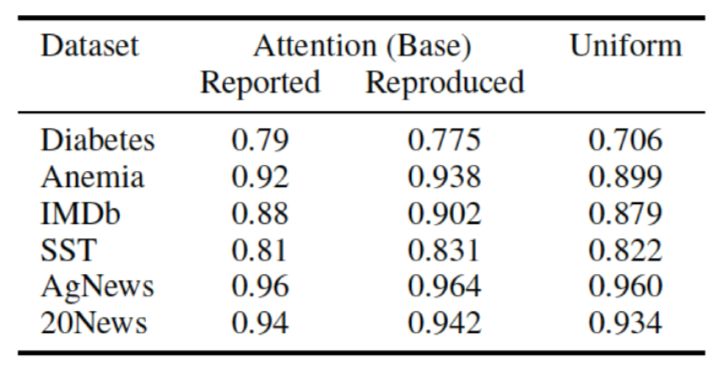
Uniform as Adversary 这部分实验的初衷是验证Attention机制在各个数据集上是否有使用的必要,因为如果任务本身太过简单,不需要Attention也能有很好的效果,那这组数据就不具备说服力。相反,如果Attention是必要的,那么将其去除会导致模型性能大幅度下降。实验设计很简单,直接将Attention权重设置为平均值并冻结,只训练其余部分,所有从编码层传入的中间表示直接计算平均作为Attention层的输出。得到的文本分类F1指标如图14,其中最左侧是Jain[5]给出的结果,中间是Wiegreffe[6]复现的结果,最右侧是这次实验得到的结果。直观上可以看到,以上大部分数据集在使用Attention之后效果提升其实并不显著,尤其是后两个数据集,几乎是毫无增长。对此作者总结为‘Attention is not explanation if you don’t need it’。
图14 文本分类任务的F1指标
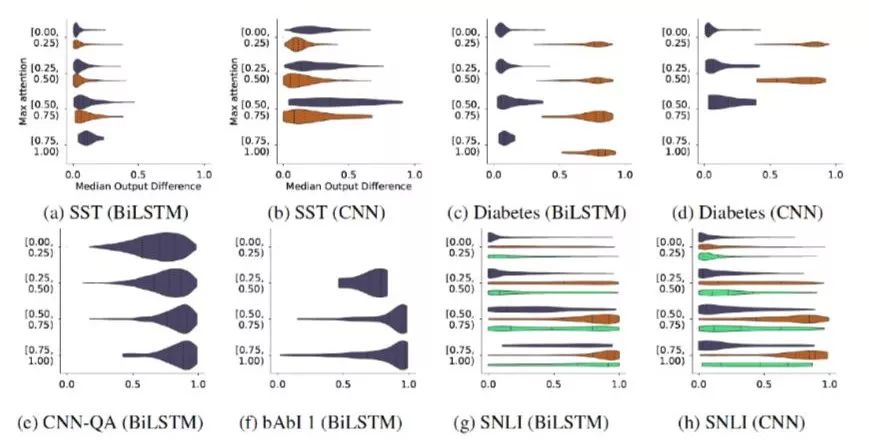
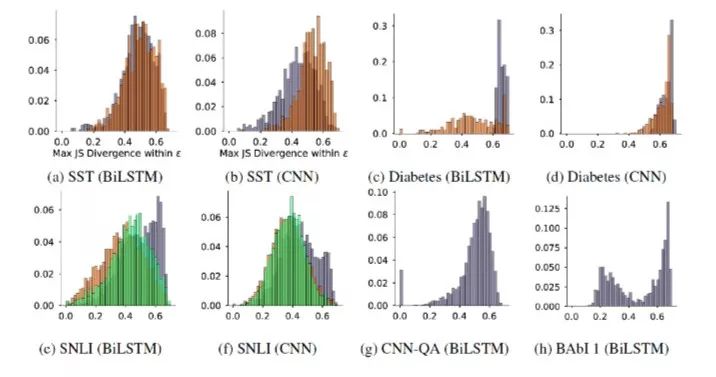
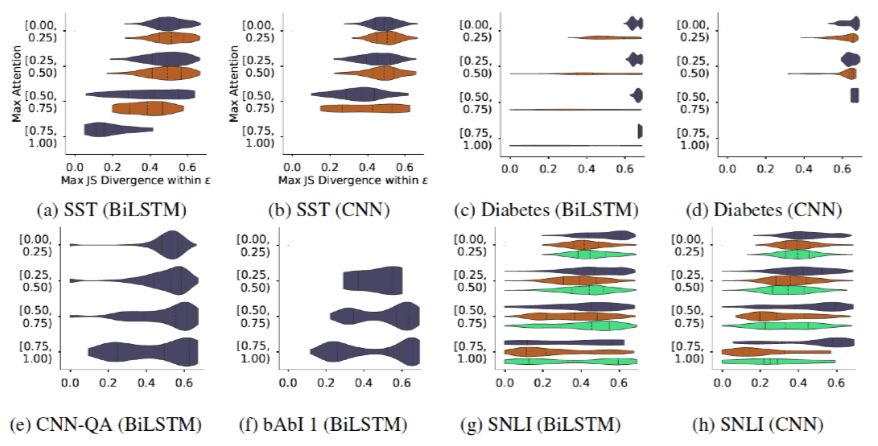
Variance with a Model 作者使用随机种子重新初始化并训练模型,得到不同的Attention权重,这些权重被视为是正常的权重,也就是只是被噪音干扰而不是人为干预的非对抗权重,将其与原始权重的分布计算JSD指标就可以得到正常权重的baseline,超过这一基准的权重都是不正常的权重。如图15所示,这与之前的heatmap一样,横坐标是JS距离,纵坐标是最大Attention权重范围。这是一组对比图,从a到d都是用随机种子生成出来的各个数据集上的baseline,e和f是Jain[5]的对抗权重实验数据,可以发现,SST数据集上生成权重与原始权重之间的JSD距离远超baseline。这意味着人工构造的对抗数据确实是不正常的,远远大于噪音的程度,这一结果其实和上一个实验的现象是不谋而合的,Attention起到的作用越小,其权重的分布就越不可预测,但是到这里为止还只是理论上的探讨,并没有确切的数据去解释构造出来的Attention权重到底是什么情况。
图15. 基于随机种子初始化训练得到的权重分布与对抗权重分布到原始分布的JS距离比较
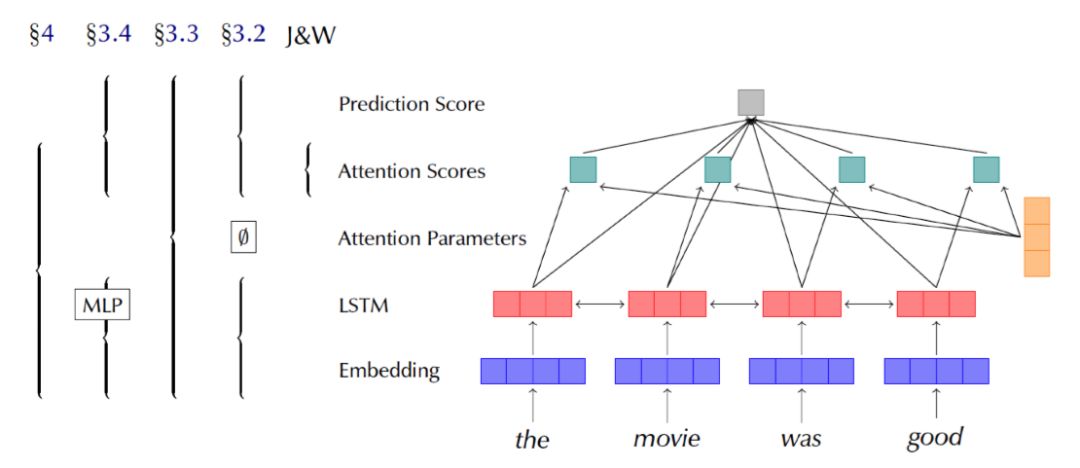
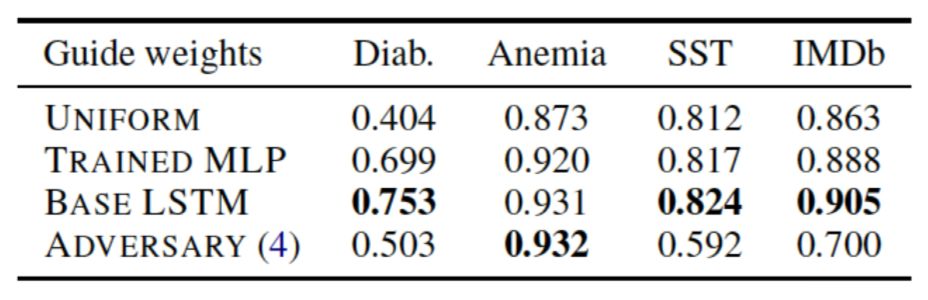
Diagnosing Attention Distribution by Guiding Simpler Models 这部分的模型与之前有所不同,这里希望能更精准地检验Attention权重分布,消除上下文相关结构的影响,故而将原先使用的LSTM编码层剔除,只使用一个MLP来完成从嵌入层到分类结果的仿射变换,之后直接使用预设的不训练的Attention权重,加权求和得到模型决策结果,具体模型如图16所示。作者在此基础上设计了四种对照实验:
[1] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems, pp. 5998-6008.
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171-4186.
[3] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations.
[4] Sofia Serrano, and Noah A. Smith. 2019. Is Attention Interpretable. arXiv preprint arXiv:1906.03731.
[5] Sarthak Jain and Byron C. Wallace. 2019. Attention is not Explanation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers).
[6] Sarah Wiegreffe, and Yuval Pinter. 2019. Attention is not not Explanation.arXiv preprint arXiv:1908.04626.
[7] Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical attention networks for document classification. InProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
[8] Yoon Kim. 2014. Convolutional neural networks for sentence classification. InProceedings of the Conference on Empirical Methods in Natural Language Processing.
[9] Zachary C Lipton. 2016. The mythos of model interpretability. arXiv preprint arXiv:1606.03490.










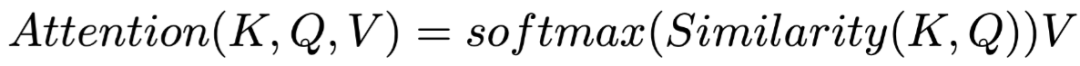

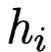 (作为Value)是上一层的在序列第i个位置的输出张量,如果上一层是双向RNN结构则
(作为Value)是上一层的在序列第i个位置的输出张量,如果上一层是双向RNN结构则
 ;
;
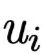 是第i个位置的键Key,由值Value通过一层全连接层计算得到;
是第i个位置的键Key,由值Value通过一层全连接层计算得到;
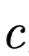 是这一个Attention层的查询Query,随机初始化,在训练的过程中同步更新,如果Attention并不单独成层而是搭建在解码器上,则
是这一个Attention层的查询Query,随机初始化,在训练的过程中同步更新,如果Attention并不单独成层而是搭建在解码器上,则
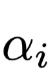 即是Attention权重,
即是Attention权重,
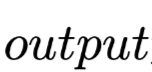 是Attention层的输出。
是Attention层的输出。
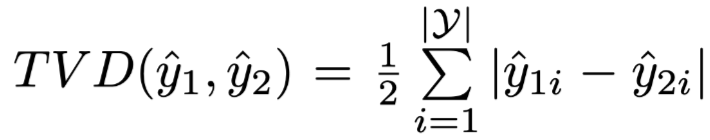
 和
和
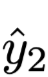 为两个不同的输出结果分布。
为两个不同的输出结果分布。
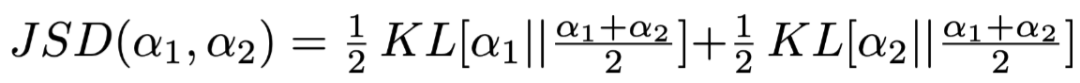
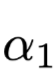 和
和
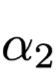 为两个不同的分布,可以是输出结果也可以是Attention权重,
为两个不同的分布,可以是输出结果也可以是Attention权重,
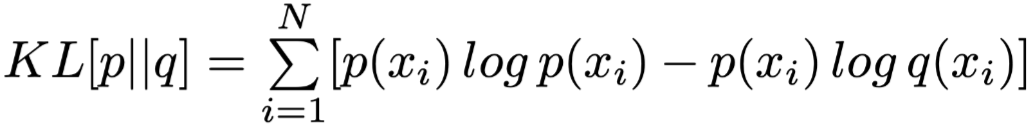
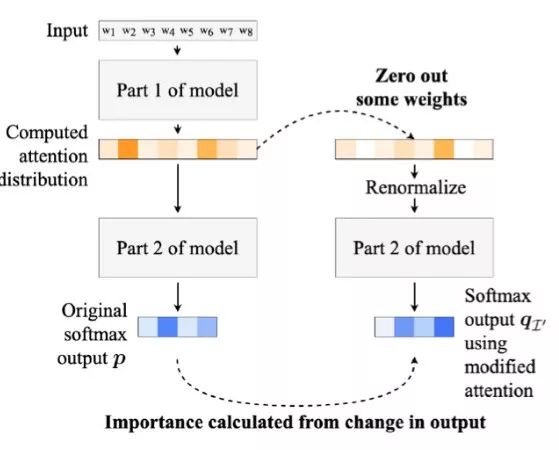


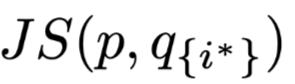 ,其中
,其中
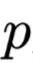 是正常结果的分布,
是正常结果的分布,
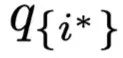 是擦除最高权重对应位置
是擦除最高权重对应位置
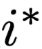 的中间表示之后的结果分布。为了检验这个距离到底有多少,重新随机选择一个位置
的中间表示之后的结果分布。为了检验这个距离到底有多少,重新随机选择一个位置
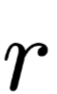 ,用同样的流程擦除其中间表示,得到对应的JSD指标
,用同样的流程擦除其中间表示,得到对应的JSD指标
 ,此时我们可以使用
,此时我们可以使用
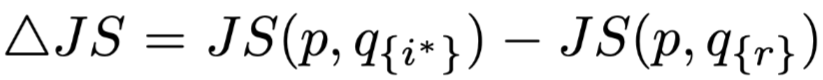 进行比较。直觉上来说,如果权重高的项确实是更重要的,那么这个公式应该是恒为正的,并且置零的两个权重大小差距
进行比较。直觉上来说,如果权重高的项确实是更重要的,那么这个公式应该是恒为正的,并且置零的两个权重大小差距
 越大,
越大,
 的值也应该越大。作者在文中展示的图表如图4左侧所示,横坐标是两个权重的差值,纵坐标是
的值也应该越大。作者在文中展示的图表如图4左侧所示,横坐标是两个权重的差值,纵坐标是
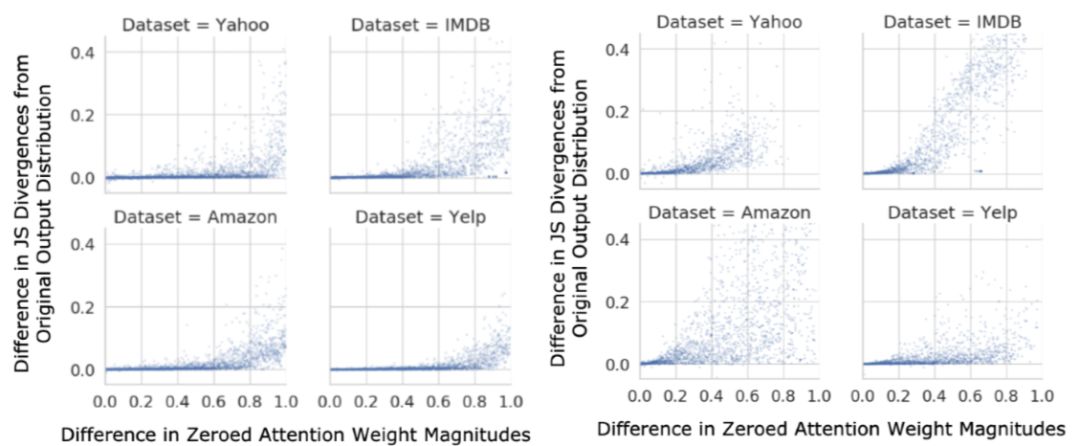

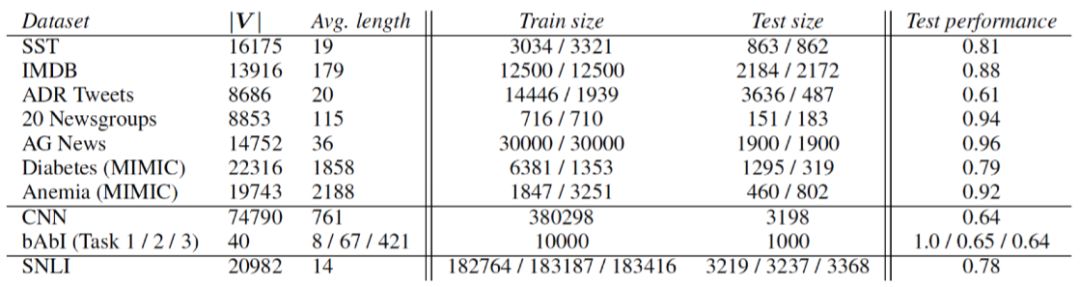

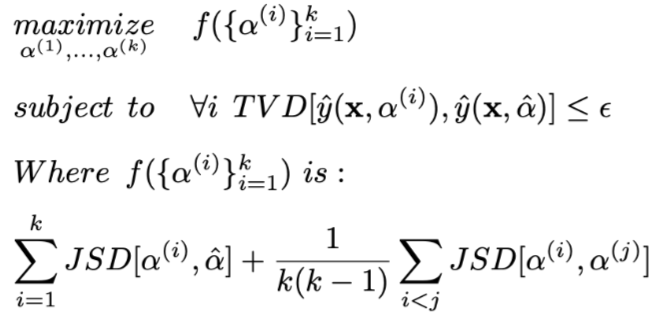
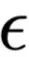 表示一个确切定义的小,即使用构造出来的权重让模型进行的决策和使用原始权重得到结果的TVD距离所能达到的最大值,
表示一个确切定义的小,即使用构造出来的权重让模型进行的决策和使用原始权重得到结果的TVD距离所能达到的最大值,
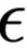 在情感分类任务上是0.01,在问答任务上是0.05(因为问答任务的输出向量空间更大,较小的扰动就会产生较大的TVD距离)。
在情感分类任务上是0.01,在问答任务上是0.05(因为问答任务的输出向量空间更大,较小的扰动就会产生较大的TVD距离)。
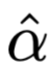 是原始Attention权重,
是原始Attention权重,
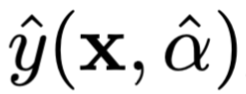 是使用原始权重得到的模型结果。
是使用原始权重得到的模型结果。
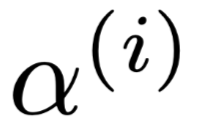 表示的是第i组构造出来的权重分布,
表示的是第i组构造出来的权重分布,
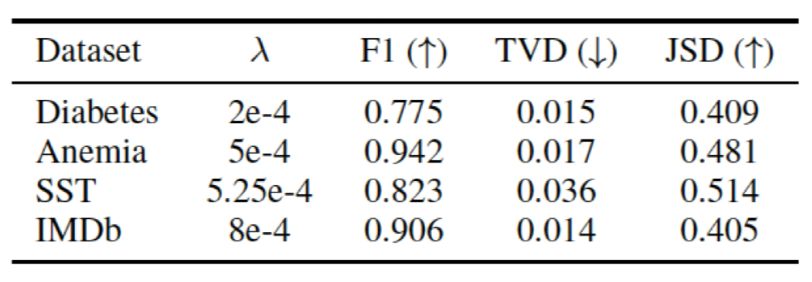
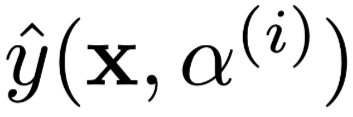 是使用第i组构造权重得到的模型结果。优化目标是得到杫组生成的Attention权重,使得在满足每组权重让模型产生的结果与原始结果的TVD距离不超过
是使用第i组构造权重得到的模型结果。优化目标是得到杫组生成的Attention权重,使得在满足每组权重让模型产生的结果与原始结果的TVD距离不超过
 ,其中λ是超参数,训练时被设置为500。
,其中λ是超参数,训练时被设置为500。

 ,其中
,其中
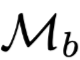 是原始权重的模型,
是原始权重的模型,
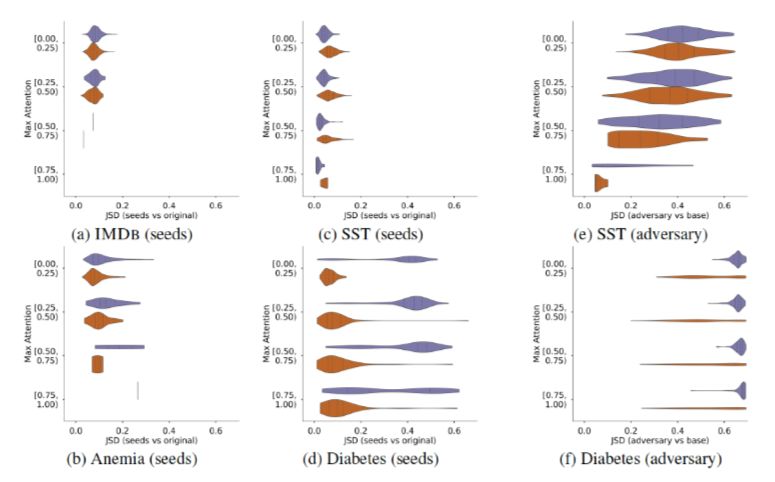
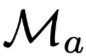 是对抗权重的模型。从图18可以看到,确实能够得到效果不错的对抗权重,但是在上一个实验中也证明了这些权重只是钻了模型的空子而已,并不是发现了更重要的信息。
是对抗权重的模型。从图18可以看到,确实能够得到效果不错的对抗权重,但是在上一个实验中也证明了这些权重只是钻了模型的空子而已,并不是发现了更重要的信息。















 2601
2601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









