







出题方将制作过程加密。根据前面帖子的专利文献里推测出来的字段含义,供各位同道参考

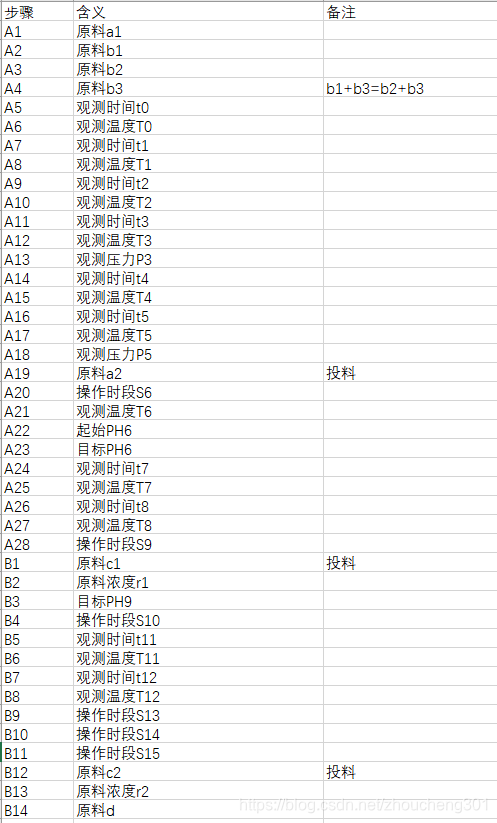
** 11楼,20楼有最新的推测
Stock Technical Analysis – Python Tutorial
http://www.andrewshamlet.net/
Stock Prediction with ML: Feature Engineering
https://alphascientist.com/feature_engineering.html
Alex_Scut(35th in this Competition)
I just train a single LSTM model with attention and mask for every stock.Features that i used are just the original data with shifting.
Trainer Brock
(8th in this Competition)
The LSTM was one of the ideas I had (one model for all the stocks) but I thought it was too uncertain (and I have no experience training LSTMs) so I tried other things instead. Too bad we cannot team up, I use just LightGBM, so the model variety would have been very nice for blending!
markmipt(19th in this Competition)
Hi! It is my first competition at Kaggle. I did not used qianqian’s kernel and any “lag” features, but have managed to get 0.76 score. I want say that 0.7 can be reached just by using market data + a few basic features which can be googled without few minutes + careful validation of catboost/lightgbm training. The rest scores came from some personal ideas, some of them were based on my knowledge (which is not very deep actually) of finance. My advice is you should clearly realize that this competition is mostly not about hyperparameters tuning, stacking or precise prediction of values which are usually in kaggle competitions, but about proper using of predicted values
https://www.kaggle.com/c/two-sigma-financial-news/discussion/75585
I have a score of 0.71515 (currently 69th place) - I’m not using news or any lag features – just these with a single instance of LGBM:
(‘returnsOpenPrevMktres1’, 72)
(‘returnsClosePrevMktres1’, 78)
(‘returnsClosePrevMktres10’, 112)
(‘returnsClosePrevRaw1’, 114)
(‘returnsClosePrevRaw10’, 164)
(‘returnsOpenPrevRaw1’, 200)
(‘returnsOpenPrevMktres10’, 207)
(‘returnsOpenPrevRaw10’, 409)
(‘returnsClosePrevRaw1avg’, 568) (‘returnsOpenPrevMktres10avg’, 617)
(‘returnsClosePrevMktres1avg’, 649) (‘closeopenratioavg’, 650)
(‘returnsClosePrevRaw10avg’, 652) (‘returnsOpenPrevMktres1avg’, 661)
(‘returnsClosePrevMktres10avg’, 673) (‘returnsOpenPrevRaw1avg’, 673)
(‘returnsOpenPrevRaw10_avg’, 721)
For me, the big win came from normalising the submission scores (and applying a slight bias)…
John Wakefield(85th in this Competition)
@jonnydossantos - correct, my averages are calculated by grouping on each training day.
@aditya1702 - yes, I’m simply subtracting the mean for each prediction day.
Don’t use public kernels without refactoring. Most of them contain a lot of issues in data preparation. It doesn’t mean they can not win (due to the core of this competition - market data) and we will see a lot of shakeups.
Code carefully (your code should be fast and memory efficient). It helps with making experiments.
Use sample data to test the code before real training.
Train/Validation sets are really important - try to think how you validate your model.
Try more features and their combinations.
Read more about market data and financial approaches. E.g. in this competition we are predicting ‘sharpe ratio’.
Check kernels for new ideas of features. Sometimes you may find them in comments but not in the code.
Public leaderboard is not a final target. 😃
UPDATES:
Answers about current score 0.9:
we don’t use fine tuning during test phase
we use lag features
there are none news features at the moment
parameters tuning - random search on cross-validation with manual selection
UPDATES 2:
it’s not easy to predict 2007-2008, but it’s possible to train model based on this period (so, there is a signal inside)
Bollinger Band, MACD, and EWMA















 3746
3746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









