




控制反转即IoC (Inversion of Control),它把传统上由程序代码直接操控的对象的调用权交给外部容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”概念就是组件对象的控制权转移了,从程序代码本身转移到了外部容器。
IoC(Inversion of Control)是近年来兴起的一种思想,不仅仅是编程思想。主要是协调各组件间相互的依赖关系,同时大大提高了组件的可移植性,组件的重用机会也变得更多。在传统的实现中,由程序内部代码来控制程序之间的关系。我们经常使用new关键字来实现两对象组件间关系的组合,这种实现的方式会造成组件之间耦合(一个好的设计,不但要实现代码重用,还要将组件间关系解耦)。 IoC很好的解决了该问题,它将实现组件间关系从程序内部提到外部容器来管理。也就是说由容器在运行期将组件间的某种依赖关系动态的注入到组件中。控制程序间关系的实现交给了外部的容器来完成。即常说的好莱坞原则“Don't call us, we'll call you”( 你呆着别动,到时我会找你)。
我们知道,如果Class A中用到了Class B的对象b,一般情况下,需要在A的代码中显式的new一个B的对象。采用依赖注入技术之后,A的代码只需要定义一个私有的B对象,不需要直接new来获得这个对象,而是通过相关的容器控制程序来将B对象在外部new出来并注入到A类里的引用中。而具体获取的方法、对象被获取时的状态由配置文件(如XML)来指定。
IoC(Inversion of Control)是近年来兴起的一种思想,不仅仅是编程思想。主要是协调各组件间相互的依赖关系,同时大大提高了组件的可移植性,组件的重用机会也变得更多。在传统的实现中,由程序内部代码来控制程序之间的关系。我们经常使用new关键字来实现两对象组件间关系的组合,这种实现的方式会造成组件之间耦合(一个好的设计,不但要实现代码重用,还要将组件间关系解耦)。 IoC很好的解决了该问题,它将实现组件间关系从程序内部提到外部容器来管理。也就是说由容器在运行期将组件间的某种依赖关系动态的注入到组件中。控制程序间关系的实现交给了外部的容器来完成。即常说的好莱坞原则“Don't call us, we'll call you”( 你呆着别动,到时我会找你)。
我们知道,如果Class A中用到了Class B的对象b,一般情况下,需要在A的代码中显式的new一个B的对象。采用依赖注入技术之后,A的代码只需要定义一个私有的B对象,不需要直接new来获得这个对象,而是通过相关的容器控制程序来将B对象在外部new出来并注入到A类里的引用中。而具体获取的方法、对象被获取时的状态由配置文件(如XML)来指定。
IoC实现方法
实现控制反转主要有两种方式:依赖注入和依赖查找。两者的区别在于,前者是被动的接收对象,在类A的实例创建过程中即创建了依赖的B对象,通过类型或名称来判断将不同的对象注入到不同的属性中,而后者是主动索取响应名称的对象,获得依赖对象的时间也可以在代码中自由控制。IoC的实现与语言无关。用各种语言,如C++, Java, C#等都可以。这里主要以Java为例。
依赖注入有如下实现方式:
- 基于接口。实现特定接口以供外部容器注入所依赖类型的对象。接口中定义要注入依赖对象的方法。
- 基于setter方法。实现特定属性的public set方法,来让外部容器调用,以传入所依赖类型的对象。如Spring Framework,WebWork/XWork。
- 基于构造函数。实现特定参数的构造函数,在新建对象时传入所依赖类型的对象。如PicoContainer,HiveMind。
- 基于注解。基于Java的注解功能,在私有变量前加“@Autowired”等注解,不需要显式的定义以上三种代码,便可以让外部容器传入对应的对象。该方案相当于定义了public的set方法,但是因为没有真正的set方法,从而不会为了实现依赖注入导致暴露了不该暴露的接口(因为set方法只想让容器访问来注入而并不希望其他依赖此类的对象访问)。
依赖查找更加主动,在需要的时候通过调用框架提供的方法来获取对象,获取时需要提供相关的配置文件路径、key等信息来确定获取对象的状态。这主要是通过JNDI或ServiceManager等获得依赖对象,这类似于Martin Fowler说的ServiceLocator模式。 如EJB,Avalon(Apache的一个复杂使用不多的项目),就是用依赖查找。
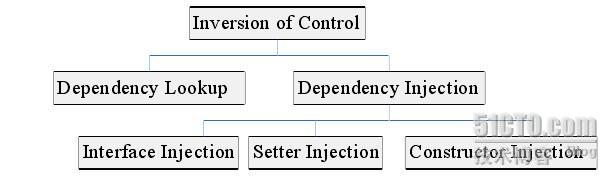
图1 控制反转的实现方式
依赖注入
依赖注入的基本原则是:应用组件不应该负责查找资源或者其他依赖的协作对象。配置对象的工作应该由IoC容器负责,“查找资源”的逻辑应该从应用组件的代码中抽取出来,交给IoC容器负责。
下面分别演示3中主要的注入机制。待注入的业务对象如下。
1、构造子注入
定义 注入接口 InContent ,里面有注入Content对象的方法。
下面代码展示了基于JNDI实现的依赖查找机制。
(1)IoC = Inversion of Control(由容器控制程序之间的关系)
IoC,用白话来讲,就是由容器来控制程序中的各个类之间的关系,而非传统实现中,直接在代码中由程序代码直接操控。比如在一个类(A)中访问另外一个类中(B)的方法时,我们需要先去new 一个B的对象,然后调用所需的方法。他们的关系很显然在程序代码中控制,同时它们之间的耦合度也比较大,不利于代码的重用。而我们现在把这种控制程序之间的关系交给Ioc容器,让它去帮你实例化你所需要的对象,而你直接在程序中调用就可以了。这也就是所谓"控制反转"的概念的由来:控制权由应用程序的代码中转到了外部容器,控制权的转移,是所谓反转的由来。
可能你不知道Ioc容器到底,或确切的指的是什么?其实这里的容器就相当于一个工厂一样。你需要什么,直接来拿,直接用就可以了,而不需要去了解、去关心你所用的东西是如何制成的,在程序中体现为实现的细节,这里就用到了工厂模式,其实Spring容器就是工厂模式和单例模式所实现的。
对于初学者,我想简单的先说明几点,不要把applicationContext.xml或带有bean的配置文件理解为容器,它们只是描述了要用到的类(bean)之间的依赖关系。Spring中的容器很抽象,不像Tomcat, Weblogic, WebSphere等那样的应用服务器容器是可见的。Spring的Ioc容器给人的感觉好像就是那些配置文件(applicationContext.xml),我刚开始学时,也以为就是那些带bean的配置文件,虽然它对你学习Spring没什么影响,但如果想更深沉的了解就会迷茫的,我们在这里要正确理解Spring的Ioc容器,以后对我们学习会有很大的帮助的。其实它的容器是有一些类和接口来充当的,你可能又会很迷茫。这就是它与别的框架的不同之处,这一点也正在体现了它的无侵入性的一点,不像EJB需要专门的容器来运行,侵入性很大的重量级的框架。Spring只是一种轻量级的无侵入性的框架。说白了Spring的Ioc容器就是可以实例化BeanFactory或ApplicationContext(扩展了BeanFactory)的类。
可能你对Ioc容器还是不太理解,慢慢来,刚刚接触的人都会很迷茫。我现在通过讲解一个例子来说明它的工作原理,你可能会恍然大悟,原来如此简单。
首先打开你的IDE编译器,我使用NetBeans 8.0,它很好地集成了Spring的开发。
我举了一个大家比较熟悉的例子,用户登录验证。如果用户名为admin,密码为1234,就会在控制台输出”恭喜你,登录成功!”,反之输出“对不起,登录失败!”,并在日志文件中记录登录信息。这里我用到的是log4j(日志记录器)。我严格按分层思想和Spring中提倡的按接口编程的思想来演练这个简单的例子。可能你会想这么简单的为什么要那么麻烦呢?怎么不用一个类就解决了,我们时刻要记住,我们的代码要易维护,可重用,易扩展,低耦合,高内聚。如果你了解这些原则,你自然会明白这样麻烦的好处了。
为演示Spring的无侵入性特征,我们创建一个普通的Java项目,而不是Java Web项目,然后添加Spring Framework 4.0.1的类库。先整体的讲解一下工程中的组织结构,如下图。除了源码文件,还需要创建一个applicationContext.xml配置文件,用于指定bean之间的依赖关系。
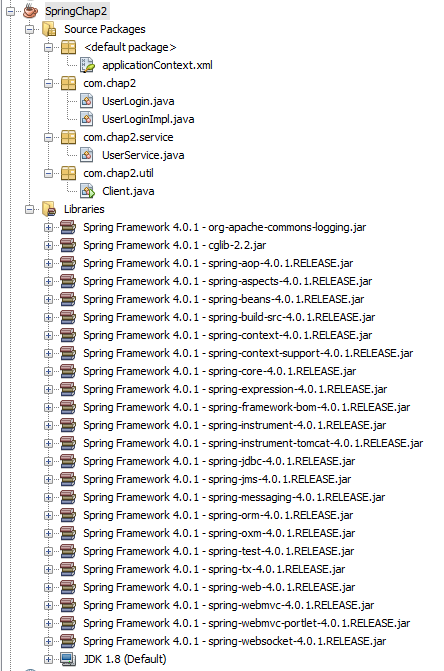
图2 SpringChap2项目结构
首先我们看一下UserLogin接口和它的实现部分UserLoginImpl:
然后在看一下业务逻辑层的UserService这里应该再对该类进行提取接口的,我只是写了一个类,如果你有兴趣的话,你可以在加上接口像上面的UserLogin一样,这样做是为了降低代码的耦合度,提高封装性。
这里的前台客户端的调用,我没用到html, jsp之类的页面,只是用了一个main()方法简单的模拟一下。同样可以起到上面讲的效果的。
生成的JAR包结构如下:
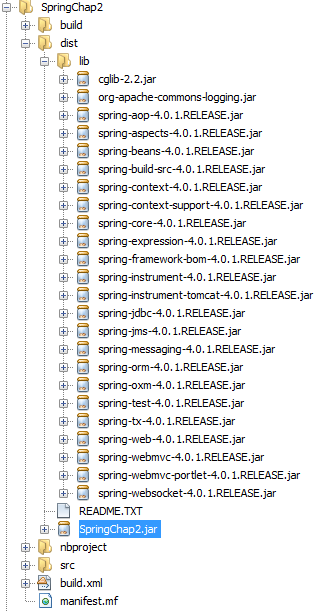
图3 生成的可执行程序
在dist目录下面生成了包SpringChap2.jar,以及它依赖的各个库。可以直接运行这个Java程序。运行结果:
整个程序的工作流程是这样的。在main()方法中通过ApplicationContext来加载配置文件,然后把它转换为BeanFactory。这就是我们要讲的Spring中控制反转容器。它把所有的类都初始化,并放在这个容器中。在我们需要的时候只需像 UserService userService = (UserService) beanFactory.getBean("userService");通过配置文件中bean的id或name调用就可以了。不必在像以前的编程那样UserService userSerivce=new UserService();这样做还有一个好处就是让容器来管理它的生命周期,我们只需用就可以了,用完了在交给容器管理。而不用担心什么时候销毁它。
可以看出,上面这个程序可以直接运行,无需任何容器如Tomcat, Jetty, JBoss。当然这不是Web项目,没有用到JSP。如果是Spring Web项目,用到了JSP,那只要一个支持Servlet的容器即可,但无需EJB容器,这体现出Spring的轻量级、非侵入式的框架设计思想。Spring框架本身是不依赖于应用服务器容器的。
(2)IOC 是一种使应用程序逻辑外在化的设计模式
因为提供服务的组件是被注入而不是被写入到客户机代码中。将 IOC 与接口编程应用结合从而产生出 Spring 框架的架构,这种架构能够减少客户机对特定实现逻辑的依赖。
(3)IoC的设计目标
不创建对象,但是描述创建它们的方式。在代码中不直接与对象和服务连接,但在配置文件中描述哪一个组件需要哪一项服务。容器(在 Spring 框架中是 IOC 容器) 负责将这些联系在一起。
(4)IoC在应用开发中的体现
IoC的抽象概念是“依赖关系的转移”,在实际应用中的下面的各个规则其实都是IoC在应用开发中的体现。
“高层模块组件不应该依赖低层模块组件,而是模块组件都必须依赖于抽象”是 IoC的一种表现
“实现必须依赖抽象,而不是抽象依赖实现”也是IoC的一种表现
“应用程序不应依赖于容器,而是容器服务于应用程序”也是IoC的一种表现。
接下来我们讲在讲述它的另外的一个名字:依赖注入(DI)。
(1)DI = Dependency Injection
正在业界为IoC争吵不休时《Inversion of Control Containers and the Dependency Injection pattern》为IoC正名,至此,IoC又获得了一个新的名字:依赖注入(Dependency Injection)。
Dependency Injection模式是依赖注射的意思,也就是将依赖先剥离,然后在适当时候再注射进入。
(2)何谓依赖注入
相对IoC 而言,“依赖注入”的确更加准确地描述了这种古老而又时兴的设计理念。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,形象的来说,即由容器动态的将某种依赖关系注入到组件之中。
讲的通俗点,就是在运行期,由Spring根据配置文件,将其他对象的引用通过组件的提供的setter方法或者构造方法等进行设定。
在上面的UserService中已经体现了这种方式,当UserService需要的UserLogin的时候,容器会给它注入。这就体现了需要用的时候,有容器给你注入。你不必主动的如创建了。也不用如何管理它了。是不是和以前的编程方式有些改变。可能你会想到,这不就是工厂模式的衍生吗?不错它就是利用工厂模式的原理实现的,但它远比工厂模式简单。通过上面的部分代码我们就可以看出它就是工厂模式的衍生,BeanFactory就充分说明了这一点。
(1)目的
依赖注入的目标并非为软件系统带来更多的功能,而是为了提升组件重用的概率,并为系统搭建一个灵活、可扩展的平台。
(2)原因---更简洁的编程实现
很多初学者常常陷入"依赖注入,何用之有?"的疑惑。想来前面和下面的例子可以帮助大家简单的理解其中的含义。
回顾上面创建SpringChap2的例子中,UserService类在运行前,其userName, password节点为空。运行后由容器将字符串"admin"和"1234"注入。此时UserService即与内存中的"admin"和"1234"字符串对象建立了依赖关系。也许区区一个字符串我们无法感受出依赖关系的存在。
如果把这里的userName/password属性换成一个数据源(DataSource),可能更有感觉:
对比传统的实现方式(如通过编码初始化DataSource实例),我们可以看到,基于依赖注入的系统实现相当灵活简洁。
(3)产生的效果
通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定DAOBean中所需的DataSource实例。DAOBean只需利用容器注入的DataSource实例,完成自身的业务逻辑,而不用关心具体的资源来自何处、由谁实现。
首先,提高了组件的可移植性和可重用度
假设我们的部署环境发生了变化,系统需要脱离应用服务器独立运行,这样,由于失去了容器的支持,原本通过JNDI获取DataSource的方式不再有效(因为,现在则需要改变为由某个组件直接提供DataSource)。
我们需要如何修改以适应新的系统环境?很简单,我们只需要修改dataSource的配置:
其次,依赖注入机制减轻了组件之间的依赖关系
回想传统编码模式中,如果要进行同样的修改,我们需要付出多大的努力。因此,依赖注入机制减轻了组件之间的依赖关系,同时也大大提高了组件的可移植性,这意味着,组件得到重用的机会将会更多。
Spring所倡导的开发方式---由容器帮助我们管理对象的生命周期和关系。
我们只需要将对象在Spring中进行登记。Spring所倡导的开发方式就是如此,所有的类都会在Spring容器中登记,告诉Spring你是个什么东西,你需要什么东西,然后Spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。
所有的类的创建、销毁都由Spring来控制。所有的类的创建、销毁都由Spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是Spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被Spring控制,所以这叫控制反转。
(1)IoC的实现前提---借助于依赖注入
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。
比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了Spring我们就只需要告诉Spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A并不需要知道。
在系统运行时,Spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系的控制。A需要依赖Connection才能正常运行,而这个Connection是由Spring注入到A中的,依赖注入的名字就这么来的。
(2)如何实现依赖注入----通过reflection来实现DI
那么DI是如何实现的呢?Java 1.3之后一个重要特征是反射(reflection),它允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性,Spring就是通过反射来实现注入的。
利用下面的代码可以从配置文件中获得某个组件对象,并且动态地给该组件的message属性赋值。
在以往的开发中, 通常利用工厂模式(Factory)来解决此类问题----使外部调用类不需关心具体实现类,这样非常适合在同一个事物类型具有多种不同实现的情况下使用。其实不管是工厂模式还是依赖注入,调用类与实现类不可能没有任何依赖,工厂模式中工厂类通常根据参数来判断该实例化哪个实现类,Spring IoC将需要实例的类在配置文件文件中配置。
使用Spring IoC能得到工厂模式同样的效果,而且编码更加简洁。
当我们在应用系统中的组件设计完全是基于接口定义时,一个关键问题便产生了-----我们的程序如何去加载接口的各个实现类。在传统的解决方案种往往基于Factory模式来实现。
但采用工厂模式来实现时,将会有如下三个主要的缺点:
(1)除非重新编译,否则无法对实现类进行替换
必须重新编译工厂类使得原本可以达成的易用性大大降低。在过去,Spring诞生之前,许多项目中,我们通过引入可配置化工厂类的形式,为这种基于接口的设计提供足够的支持。这解决了实例化的问题,但是它为我们的项目开发带来了额外的负担,同时,它也没有真正帮我们解决其余两个问题。
(2)无法透明的为不同组件提供多个实现
这是我们在应用工厂模式时一个比较头疼的问题,因为Factory类要求每个组件都必须遵从Factory类中定义的方法和结构特征。
当然我们可以在代码的实现的形式上为Factory类中的ConstructObjects方法增加一个参数,通过该参数达到对接口实现的不同版本进行索引。这种实现方式的问题在于我们必须担负很大的维护工作量,每个组件都必须使用一个不同的关键字。从而使得它必须以一种与众不同的方式与其他组件的实例相区分。
(3)无法简单的进行切换实例产生的模型----单例或者原形
上面的代码是实现了返回多个实例的方式,如果我们需要保持了一个Singleton的实例,此时我们必须需要重新修改并编译Factory类。
存在这个问题的核心是在于组件必须主动寻找接口的实现类,因此这个问题并不能通过传统的工厂模式加以解决。下面用Spring IoC来实现。
SpringConfig.xml:
Spring对于基于接口设计的应用造成了极大的冲击效应。因为Spring接过了将所有组件进行串联组装的重任,我们无需再纠缠于遍布各处的工厂类设计。
package com.zj.ioc.di;
public class Content {
public void BusniessContent(){
System.out.println("do business");
}
public void AnotherBusniessContent(){
System.out.println("do another business");
}1、构造子注入
package com.zj.ioc.di.ctor;
import com.zj.ioc.di.Content;
public class MyBusiness {
private Content myContent;
public MyBusiness(Content content) {
myContent = content;
}
public void doBusiness(){
myContent.BusniessContent();
}
public void doAnotherBusiness(){
myContent.AnotherBusniessContent();
}
}package com.zj.ioc.di.set;
import com.zj.ioc.di.Content;
public class MyBusiness {
private Content myContent;
public void setContent(Content content) {
myContent = content;
}
public void doBusiness(){
myContent.BusniessContent();
}
public void doAnotherBusiness(){
myContent.AnotherBusniessContent();
}
}定义 注入接口 InContent ,里面有注入Content对象的方法。
package com.zj.ioc.di.iface;
import com.zj.ioc.di.Content;
public interface InContent {
void createContent(Content content);
}package com.zj.ioc.di.iface;
import com.zj.ioc.di.Content;
public class MyBusiness implements InContent{
private Content myContent;
public void createContent(Content content) {
myContent = content;
}
public void doBusniess(){
myContent.BusniessContent();
}
public void doAnotherBusniess(){
myContent.AnotherBusniessContent();
}
}依赖查找
下面代码展示了基于JNDI实现的依赖查找机制。
public class MyBusniessObject{
<span style="font-family:";"> </span>private DataSource ds;
private MyCollaborator myCollaborator;
<span style="font-family:";"> </span>public MyBusnissObject(){
<span style="font-family:";"> </span>Context ctx = null;
<span style="font-family:";"> </span>try{
ctx = new InitialContext();
ds = (DataSource) ctx.lookup(“java:comp/env/dataSourceName”);
myCollaborator =
(MyCollaborator) ctx.lookup(“java:comp/env/myCollaboratorName”);
}
……Spring 中的控制反转(IoC)
(1)IoC = Inversion of Control(由容器控制程序之间的关系)
IoC,用白话来讲,就是由容器来控制程序中的各个类之间的关系,而非传统实现中,直接在代码中由程序代码直接操控。比如在一个类(A)中访问另外一个类中(B)的方法时,我们需要先去new 一个B的对象,然后调用所需的方法。他们的关系很显然在程序代码中控制,同时它们之间的耦合度也比较大,不利于代码的重用。而我们现在把这种控制程序之间的关系交给Ioc容器,让它去帮你实例化你所需要的对象,而你直接在程序中调用就可以了。这也就是所谓"控制反转"的概念的由来:控制权由应用程序的代码中转到了外部容器,控制权的转移,是所谓反转的由来。
可能你不知道Ioc容器到底,或确切的指的是什么?其实这里的容器就相当于一个工厂一样。你需要什么,直接来拿,直接用就可以了,而不需要去了解、去关心你所用的东西是如何制成的,在程序中体现为实现的细节,这里就用到了工厂模式,其实Spring容器就是工厂模式和单例模式所实现的。
对于初学者,我想简单的先说明几点,不要把applicationContext.xml或带有bean的配置文件理解为容器,它们只是描述了要用到的类(bean)之间的依赖关系。Spring中的容器很抽象,不像Tomcat, Weblogic, WebSphere等那样的应用服务器容器是可见的。Spring的Ioc容器给人的感觉好像就是那些配置文件(applicationContext.xml),我刚开始学时,也以为就是那些带bean的配置文件,虽然它对你学习Spring没什么影响,但如果想更深沉的了解就会迷茫的,我们在这里要正确理解Spring的Ioc容器,以后对我们学习会有很大的帮助的。其实它的容器是有一些类和接口来充当的,你可能又会很迷茫。这就是它与别的框架的不同之处,这一点也正在体现了它的无侵入性的一点,不像EJB需要专门的容器来运行,侵入性很大的重量级的框架。Spring只是一种轻量级的无侵入性的框架。说白了Spring的Ioc容器就是可以实例化BeanFactory或ApplicationContext(扩展了BeanFactory)的类。
可能你对Ioc容器还是不太理解,慢慢来,刚刚接触的人都会很迷茫。我现在通过讲解一个例子来说明它的工作原理,你可能会恍然大悟,原来如此简单。
首先打开你的IDE编译器,我使用NetBeans 8.0,它很好地集成了Spring的开发。
我举了一个大家比较熟悉的例子,用户登录验证。如果用户名为admin,密码为1234,就会在控制台输出”恭喜你,登录成功!”,反之输出“对不起,登录失败!”,并在日志文件中记录登录信息。这里我用到的是log4j(日志记录器)。我严格按分层思想和Spring中提倡的按接口编程的思想来演练这个简单的例子。可能你会想这么简单的为什么要那么麻烦呢?怎么不用一个类就解决了,我们时刻要记住,我们的代码要易维护,可重用,易扩展,低耦合,高内聚。如果你了解这些原则,你自然会明白这样麻烦的好处了。
为演示Spring的无侵入性特征,我们创建一个普通的Java项目,而不是Java Web项目,然后添加Spring Framework 4.0.1的类库。先整体的讲解一下工程中的组织结构,如下图。除了源码文件,还需要创建一个applicationContext.xml配置文件,用于指定bean之间的依赖关系。
图2 SpringChap2项目结构
package com.chap2;
public interface UserLogin {
public boolean login(String userName, String password);
}package com.chap2;
public class UserLoginImpl implements UserLogin{
@Override
public boolean login(String userName, String password){
if(userName.equals("admin") && password.equals("1234")){
return true;
}else{
return false;
}
}
}然后在看一下业务逻辑层的UserService这里应该再对该类进行提取接口的,我只是写了一个类,如果你有兴趣的话,你可以在加上接口像上面的UserLogin一样,这样做是为了降低代码的耦合度,提高封装性。
package com.chap2.service;
import com.chap2.UserLogin;
public class UserService {
private String userName;
private String password;
private UserLogin userLogin;
/**
* @param userName the userName to set
*/
public void setUserName(String userName) {
this.userName = userName;
}
/**
* @param password the password to set
*/
public void setPassword(String password) {
this.password = password;
}
/**
* @param userLogin the userLogin to set
*/
public void setUserLogin(UserLogin userLogin) {
this.userLogin = userLogin;
}
public String validateUser(){
if(userLogin.login(userName, password)){
return "恭喜你,登录成功!";
}else{
return "对不起,登录失败!";
}
}
}这里的前台客户端的调用,我没用到html, jsp之类的页面,只是用了一个main()方法简单的模拟一下。同样可以起到上面讲的效果的。
package com.chap2.util;
import com.chap2.service.UserService;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.springframework.beans.factory.BeanFactory;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class Client {
public static void main(String[] args) {
Log log = LogFactory.getLog(Client.class);
//初始化,并加载配置文件
ApplicationContext context = new ClassPathXmlApplicationContext("applicationContext.xml");
BeanFactory beanFactory = (BeanFactory) context;
//得到实例化的UserService
UserService userService = (UserService) beanFactory.getBean("userService");
//输出并记录登录信息
log.info(userService.validateUser());
}
}生成的JAR包结构如下:
图3 生成的可执行程序
六月 20, 2014 2:33:15 下午 org.springframework.context.support.AbstractApplicationContext prepareRefresh
INFO: Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@6433a2: startup date [Fri Jun 20 14:33:15 CST 2014]; root of context hierarchy
六月 20, 2014 2:33:15 下午 org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
INFO: Loading XML bean definitions from class path resource [applicationContext.xml]
六月 20, 2014 2:33:17 下午 com.chap2.util.Client main
INFO: 恭喜你,登录成功!<?xml version='1.0' encoding='UTF-8' ?>
<!-- was: <?xml version="1.0" encoding="UTF-8"?> -->
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.0.xsd
http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.0.xsd">
<!-- bean id="propertyConfigurer"
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"
p:location="/WEB-INF/jdbc.properties" />
<bean id="dataSource"
class="org.springframework.jdbc.datasource.DriverManagerDataSource"
p:driverClassName="${jdbc.driverClassName}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}" / -->
<!-- ADD PERSISTENCE SUPPORT HERE (jpa, hibernate, etc) -->
<bean id="userLogin" class="com.chap2.UserLoginImpl" />
<bean id="userService" class="com.chap2.service.UserService">
<property name="userName">
<value>admin</value>
</property>
<property name="password">
<value>1234</value>
</property>
<property name="userLogin">
<ref bean="userLogin"></ref>
</property>
</bean>
</beans>
整个程序的工作流程是这样的。在main()方法中通过ApplicationContext来加载配置文件,然后把它转换为BeanFactory。这就是我们要讲的Spring中控制反转容器。它把所有的类都初始化,并放在这个容器中。在我们需要的时候只需像 UserService userService = (UserService) beanFactory.getBean("userService");通过配置文件中bean的id或name调用就可以了。不必在像以前的编程那样UserService userSerivce=new UserService();这样做还有一个好处就是让容器来管理它的生命周期,我们只需用就可以了,用完了在交给容器管理。而不用担心什么时候销毁它。
可以看出,上面这个程序可以直接运行,无需任何容器如Tomcat, Jetty, JBoss。当然这不是Web项目,没有用到JSP。如果是Spring Web项目,用到了JSP,那只要一个支持Servlet的容器即可,但无需EJB容器,这体现出Spring的轻量级、非侵入式的框架设计思想。Spring框架本身是不依赖于应用服务器容器的。
(2)IOC 是一种使应用程序逻辑外在化的设计模式
因为提供服务的组件是被注入而不是被写入到客户机代码中。将 IOC 与接口编程应用结合从而产生出 Spring 框架的架构,这种架构能够减少客户机对特定实现逻辑的依赖。
(3)IoC的设计目标
不创建对象,但是描述创建它们的方式。在代码中不直接与对象和服务连接,但在配置文件中描述哪一个组件需要哪一项服务。容器(在 Spring 框架中是 IOC 容器) 负责将这些联系在一起。
(4)IoC在应用开发中的体现
IoC的抽象概念是“依赖关系的转移”,在实际应用中的下面的各个规则其实都是IoC在应用开发中的体现。
“高层模块组件不应该依赖低层模块组件,而是模块组件都必须依赖于抽象”是 IoC的一种表现
“实现必须依赖抽象,而不是抽象依赖实现”也是IoC的一种表现
“应用程序不应依赖于容器,而是容器服务于应用程序”也是IoC的一种表现。
接下来我们讲在讲述它的另外的一个名字:依赖注入(DI)。
Spring 中的依赖注入(DI)
(1)DI = Dependency Injection
正在业界为IoC争吵不休时《Inversion of Control Containers and the Dependency Injection pattern》为IoC正名,至此,IoC又获得了一个新的名字:依赖注入(Dependency Injection)。
Dependency Injection模式是依赖注射的意思,也就是将依赖先剥离,然后在适当时候再注射进入。
(2)何谓依赖注入
相对IoC 而言,“依赖注入”的确更加准确地描述了这种古老而又时兴的设计理念。从名字上理解,所谓依赖注入,即组件之间的依赖关系由容器在运行期决定,形象的来说,即由容器动态的将某种依赖关系注入到组件之中。
讲的通俗点,就是在运行期,由Spring根据配置文件,将其他对象的引用通过组件的提供的setter方法或者构造方法等进行设定。
在上面的UserService中已经体现了这种方式,当UserService需要的UserLogin的时候,容器会给它注入。这就体现了需要用的时候,有容器给你注入。你不必主动的如创建了。也不用如何管理它了。是不是和以前的编程方式有些改变。可能你会想到,这不就是工厂模式的衍生吗?不错它就是利用工厂模式的原理实现的,但它远比工厂模式简单。通过上面的部分代码我们就可以看出它就是工厂模式的衍生,BeanFactory就充分说明了这一点。
在Spring中为什么要提供“依赖注入”设计理念
(1)目的
依赖注入的目标并非为软件系统带来更多的功能,而是为了提升组件重用的概率,并为系统搭建一个灵活、可扩展的平台。
(2)原因---更简洁的编程实现
很多初学者常常陷入"依赖注入,何用之有?"的疑惑。想来前面和下面的例子可以帮助大家简单的理解其中的含义。
回顾上面创建SpringChap2的例子中,UserService类在运行前,其userName, password节点为空。运行后由容器将字符串"admin"和"1234"注入。此时UserService即与内存中的"admin"和"1234"字符串对象建立了依赖关系。也许区区一个字符串我们无法感受出依赖关系的存在。
如果把这里的userName/password属性换成一个数据源(DataSource),可能更有感觉:
<beans>
<bean id="dataSource" class="org.springframework.indi.JndiObjectFactoryBean">
<property name="jndiName">
<value> java:/comp/env/jdbc/testDB</value>
</property>
</bean>
<bean id="dataBean" class="examples.DAOBean">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
</beans>对比传统的实现方式(如通过编码初始化DataSource实例),我们可以看到,基于依赖注入的系统实现相当灵活简洁。
(3)产生的效果
通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定DAOBean中所需的DataSource实例。DAOBean只需利用容器注入的DataSource实例,完成自身的业务逻辑,而不用关心具体的资源来自何处、由谁实现。
首先,提高了组件的可移植性和可重用度
假设我们的部署环境发生了变化,系统需要脱离应用服务器独立运行,这样,由于失去了容器的支持,原本通过JNDI获取DataSource的方式不再有效(因为,现在则需要改变为由某个组件直接提供DataSource)。
我们需要如何修改以适应新的系统环境?很简单,我们只需要修改dataSource的配置:
<beans>
<bean id="dataSource" class=" org.apache.commons.dbcp.BasicDataSource " destroy-method="close">
<property name="driverClassName">
<value>com.microsoft.jdbc.sqlserver.SQLServerDriver</value>
</property>
<property name="url">
<value>jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=WebStudyDB</value>
</property>
<property name="username">
<value>sa</value>
</property>
<property name="password">
<value>1234</value>
</property>
</bean>
<bean id="dataBean" class="examples.DAOBean">
<property name="dataSource">
<ref bean="dataSource"/>
</property>
</bean>
</beans>其次,依赖注入机制减轻了组件之间的依赖关系
回想传统编码模式中,如果要进行同样的修改,我们需要付出多大的努力。因此,依赖注入机制减轻了组件之间的依赖关系,同时也大大提高了组件的可移植性,这意味着,组件得到重用的机会将会更多。
深入了解依赖注入
Spring所倡导的开发方式---由容器帮助我们管理对象的生命周期和关系。
我们只需要将对象在Spring中进行登记。Spring所倡导的开发方式就是如此,所有的类都会在Spring容器中登记,告诉Spring你是个什么东西,你需要什么东西,然后Spring会在系统运行到适当的时候,把你要的东西主动给你,同时也把你交给其他需要你的东西。
所有的类的创建、销毁都由Spring来控制。所有的类的创建、销毁都由Spring来控制,也就是说控制对象生存周期的不再是引用它的对象,而是Spring。对于某个具体的对象而言,以前是它控制其他对象,现在是所有对象都被Spring控制,所以这叫控制反转。
(1)IoC的实现前提---借助于依赖注入
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。
比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,有了Spring我们就只需要告诉Spring,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A并不需要知道。
在系统运行时,Spring会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系的控制。A需要依赖Connection才能正常运行,而这个Connection是由Spring注入到A中的,依赖注入的名字就这么来的。
(2)如何实现依赖注入----通过reflection来实现DI
那么DI是如何实现的呢?Java 1.3之后一个重要特征是反射(reflection),它允许程序在运行的时候动态的生成对象、执行对象的方法、改变对象的属性,Spring就是通过反射来实现注入的。
利用下面的代码可以从配置文件中获得某个组件对象,并且动态地给该组件的message属性赋值。
Properties pro = new Properties();
pro.load(new FileInputStream("config.properties"));
String actionImplName = (String)pro.get(actionBeanName);
String actionMessageProperty = (String)pro.get(actionMessagePropertyName);
Object obj = Class.forName(actionImplName).newInstance();
//BeanUtils是Apache Commons BeanUtils提供的辅助类
BeanUtils.setProperty(obj,"message", actionMessageProperty);
return (Action)obj;Spring IoC与工厂模式的对比
在以往的开发中, 通常利用工厂模式(Factory)来解决此类问题----使外部调用类不需关心具体实现类,这样非常适合在同一个事物类型具有多种不同实现的情况下使用。其实不管是工厂模式还是依赖注入,调用类与实现类不可能没有任何依赖,工厂模式中工厂类通常根据参数来判断该实例化哪个实现类,Spring IoC将需要实例的类在配置文件文件中配置。
使用Spring IoC能得到工厂模式同样的效果,而且编码更加简洁。
当我们在应用系统中的组件设计完全是基于接口定义时,一个关键问题便产生了-----我们的程序如何去加载接口的各个实现类。在传统的解决方案种往往基于Factory模式来实现。
// 代表某种产品类的接口,也就是我们所要创建的对象所应该具有的功能要求
interface Product {
public void execute();
}
// 不同的产品类(也就是我们所要创建的各个对象)
class ConcreteProductA implements Product {
@Override
public void execute() {
// ...
}
}
class ConcreteProductB implements Product {
@Override
public void execute() {
// ...
}
}
// 工厂类,利用它来创建出不同类型的产品---客户所需要的对象
class Factory {
public static Product CreateProduct(Object param) {
return ConstructObjects(param);
}
private static Product ConstructObjects(Object param) {
//根据不同的产品类型的需求来创建不同的产品对象
}
}
// 调用类,也就是请求者类
public class UserClient {
public UserClient() {
Product product1 = Factory.CreateProduct(paramA); //实例化ConcreteProductA
Product product2 = Factory.CreateProduct(paramB); //实例化ConcreteProductB
// ...
}
}但采用工厂模式来实现时,将会有如下三个主要的缺点:
(1)除非重新编译,否则无法对实现类进行替换
必须重新编译工厂类使得原本可以达成的易用性大大降低。在过去,Spring诞生之前,许多项目中,我们通过引入可配置化工厂类的形式,为这种基于接口的设计提供足够的支持。这解决了实例化的问题,但是它为我们的项目开发带来了额外的负担,同时,它也没有真正帮我们解决其余两个问题。
(2)无法透明的为不同组件提供多个实现
这是我们在应用工厂模式时一个比较头疼的问题,因为Factory类要求每个组件都必须遵从Factory类中定义的方法和结构特征。
当然我们可以在代码的实现的形式上为Factory类中的ConstructObjects方法增加一个参数,通过该参数达到对接口实现的不同版本进行索引。这种实现方式的问题在于我们必须担负很大的维护工作量,每个组件都必须使用一个不同的关键字。从而使得它必须以一种与众不同的方式与其他组件的实例相区分。
(3)无法简单的进行切换实例产生的模型----单例或者原形
上面的代码是实现了返回多个实例的方式,如果我们需要保持了一个Singleton的实例,此时我们必须需要重新修改并编译Factory类。
存在这个问题的核心是在于组件必须主动寻找接口的实现类,因此这个问题并不能通过传统的工厂模式加以解决。下面用Spring IoC来实现。
SpringConfig.xml:
<bean id="productA" class="ConcreteProductA" />
<bean id="productB" class="ConcreteProductB" />public class InitSpring
{
AbstractApplicationContext wac = null;
private static InitSpring instance = new InitSpring();
private InitSpring()
{
}
public static void Init(AbstractApplicationContext wac)
{
instance.wac = wac;
}
public static Object getInstance(String objName)
{
return instance.wac.getBean(objName);
}
public static Object getInstance(Class objClass)
{
return getInstance(objClass.getName());
}
}public class Client
{
public Client()
{
Product product = (Product)InitSpring.getObject("productA"); //实例化ConcreteProductA
Product product = (Product)InitSpring.getObject("productB"); //实例化ConcreteProductB
// ...
}
}Spring对于基于接口设计的应用造成了极大的冲击效应。因为Spring接过了将所有组件进行串联组装的重任,我们无需再纠缠于遍布各处的工厂类设计。
参考文献:
http://martinfowler.com/articles/injection.html
http://zh.wikipedia.org/wiki/%E6%8E%A7%E5%88%B6%E5%8F%8D%E8%BD%AC

















 1476
1476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









