






@[TOC]目录
前言
Hadoop定位
Hadoop 是一个开源的 分布式计算框架,专为处理 海量数据 而生。其核心定位是解决传统技术无法应对的大规模数据存储与计算问题,主要应用于以下场景:
- 大数据存储
- 提供分布式文件系统(HDFS),支持 PB/EB 级数据的可靠存储。 - 离线批处理
- 通过 MapReduce 模型实现高吞吐量的批量数据处理(如日志分析、ETL)。 - 生态基石
- 作为大数据生态系统的核心,支持 Hive、HBase、Spark 等工具的底层数据管理。
-
Hadoop核心优势
高容错性(Fault Tolerance)
HDFS 副本机制:默认每个数据块存储 3 个副本,即使部分节点故障,数据仍可恢复。
任务自动重试:MapReduce/YARN 自动重新分配失败的任务,确保作业完成。
适用场景:适用于硬件可靠性较低的廉价服务器集群。
水平扩展能力(Scalability)
存储扩展:通过增加 DataNode 节点,线性扩展存储容量。
计算扩展:添加 NodeManager 节点即可提升集群计算能力。
成本优势:无需购买高端硬件,使用普通 PC 服务器即可构建集群。
低成本(Cost-Effective)
开源免费:无需支付商业软件授权费用。
硬件成本低:依赖普通 x86 服务器而非高端存储设备。
技术普惠:降低企业进入大数据领域的门槛。
灵活的数据处理
支持多类型数据:结构化(Hive)、半结构化(JSON/XML)、非结构化(文本/图片/视频)。
生态工具丰富:通过 Hive 实现 SQL 查询,HBase 支持实时读写,Spark 加速迭代计算。
成熟的生态系统(*)
核心组件:HDFS(存储)、MapReduce/YARN(计算)、ZooKeeper(协调)。
扩展工具:
数据仓库:Hive、Impala
实时处理:Spark、Flink
数据迁移:Sqoop、Flume
机器学习:Mahout、Spark MLlib
- 社区支持:Apache 顶级项目,拥有活跃的开发者社区和持续更新。
配置过程
单机模式
安装jdk
上传压缩包
上传到cd /opt下目录 解压
解压
tar -zxvf jdk-8u181-linux-x64.tar.gz
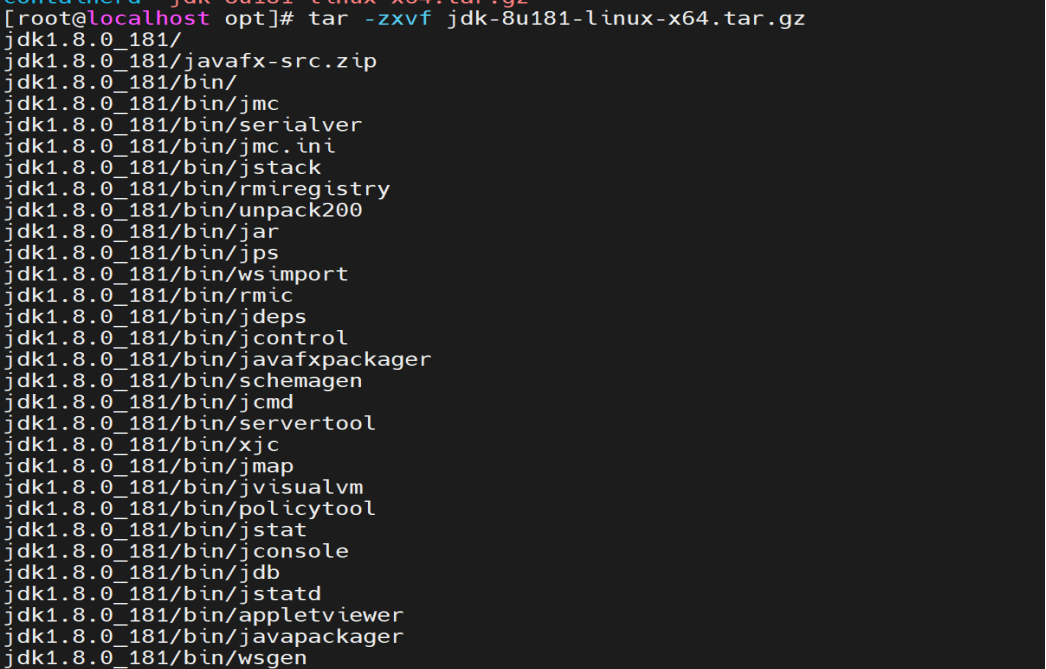
将jdk1.8.0_187改名为jdk1.8
mv jdk1.8.0_181 jdk1.8

进入vi /etc/profile在末尾增加两行
export JAVA_HOME=/opt/jdk1.8 #填写自己的jdk路径
export PATH=$JAVA_HOME/bin:$PATH

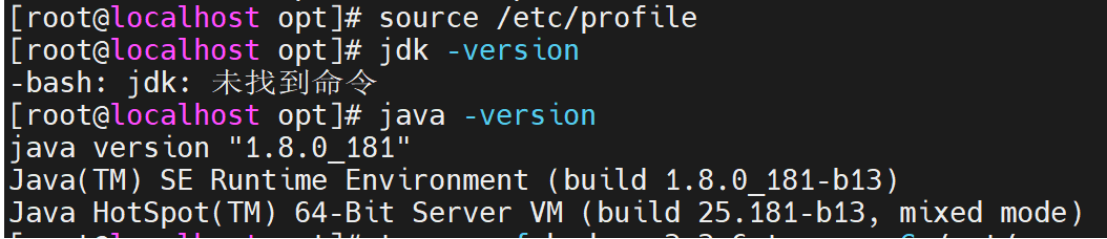
下载完成环境生效 查看版本
source /etc/profile
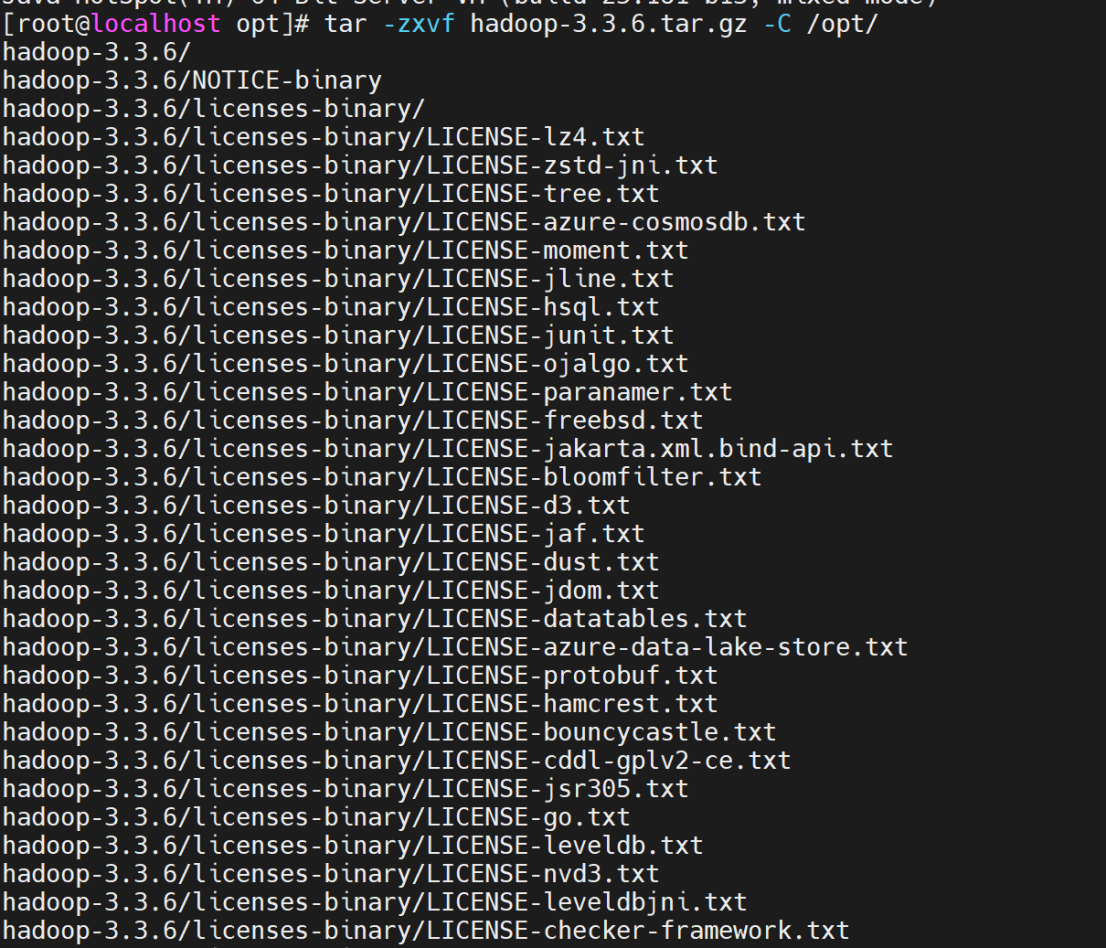
上传hadoop包并解压
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/
改名
mv /opt/hadoop-3.3.6 /opt/hadoop

进入vim ~/.bashrc

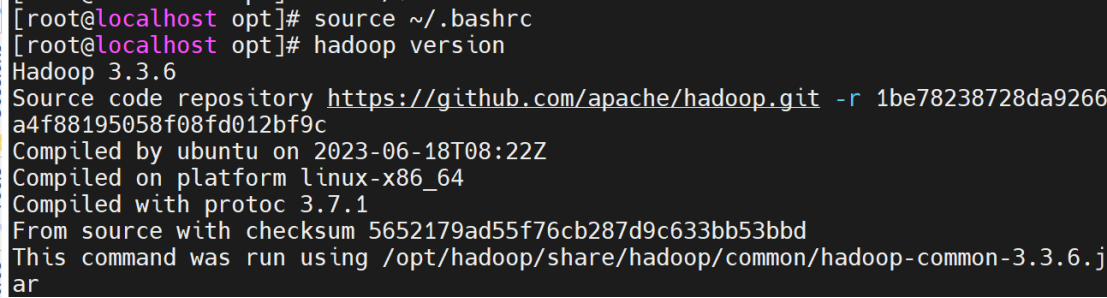
使配置生效并查看hadoop版本
source ~/.bashrc
hadoop version
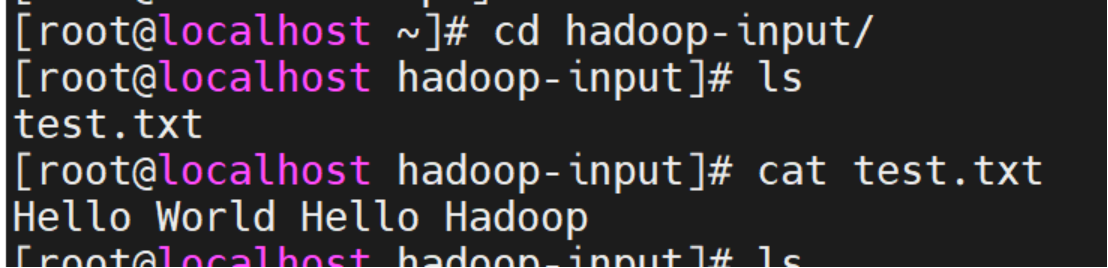
创建目录并写入内容
mkdir -p ~/hadoop-input
写入测试文本
echo "Hello World Hello Hadoop" > ~/hadoop-input/test.txt

执行wordcount
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar \
wordcount ~/hadoop-input ~/hadoop-output
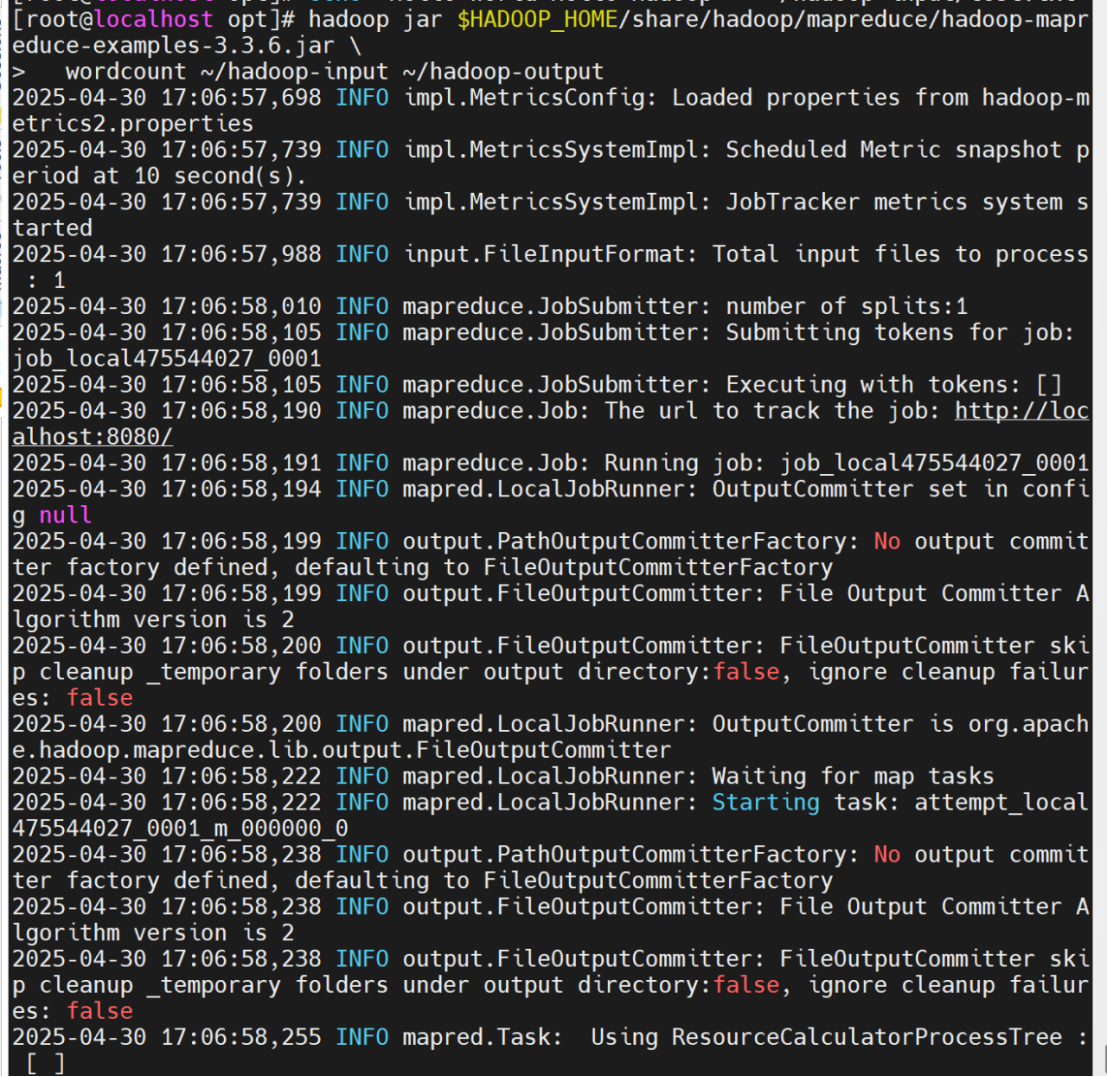
查看结果
cat ~/hadoop-output/part-r-00000

单机模式配置成功。
伪分布模式
环境准备
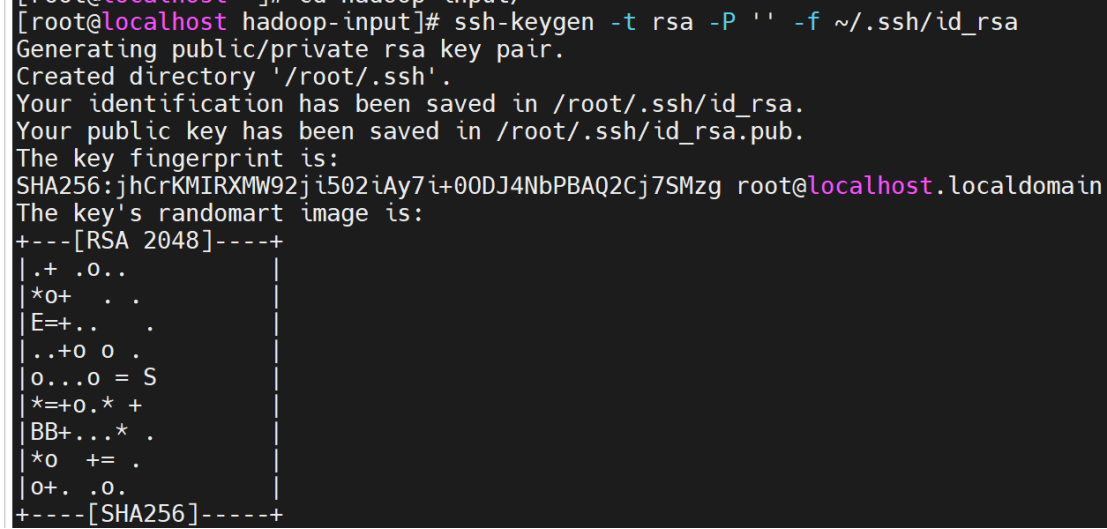
配置ssh免密登录
# 生成 SSH 密钥(如果已有密钥可跳过)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
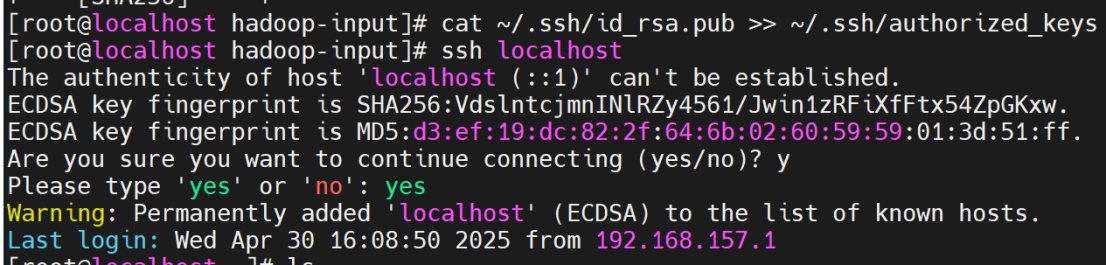
# 将公钥添加到授权列表
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 测试免密登录本机
ssh localhost
# 输入 exit 退出
修改Hadoop配置文件
cd /opt/hadoop/etc/hadoop
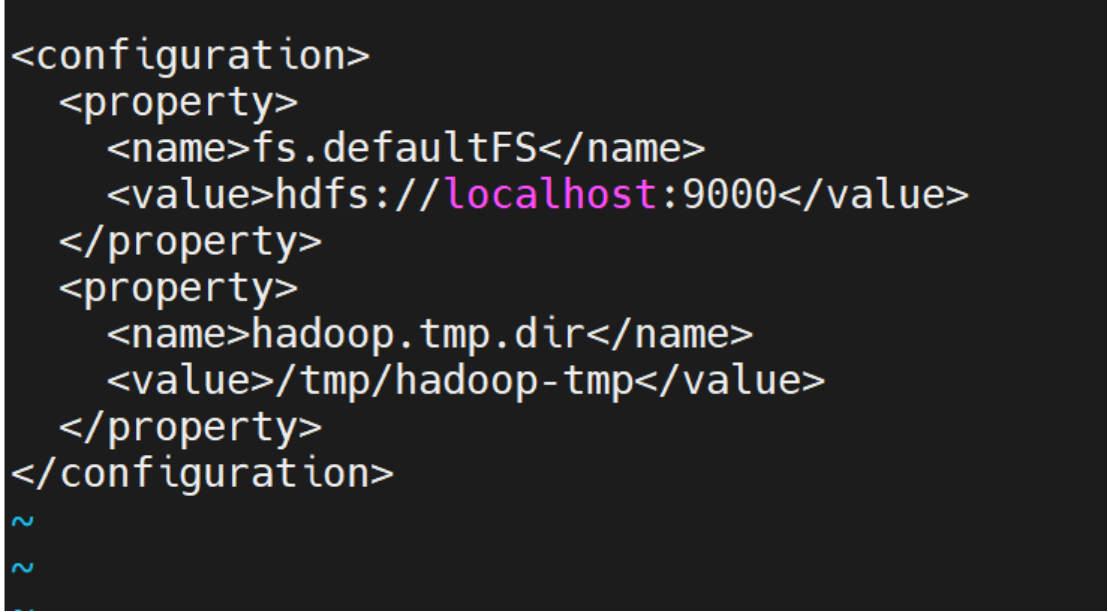
编辑core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop-tmp</value>
</property>
</configuration>
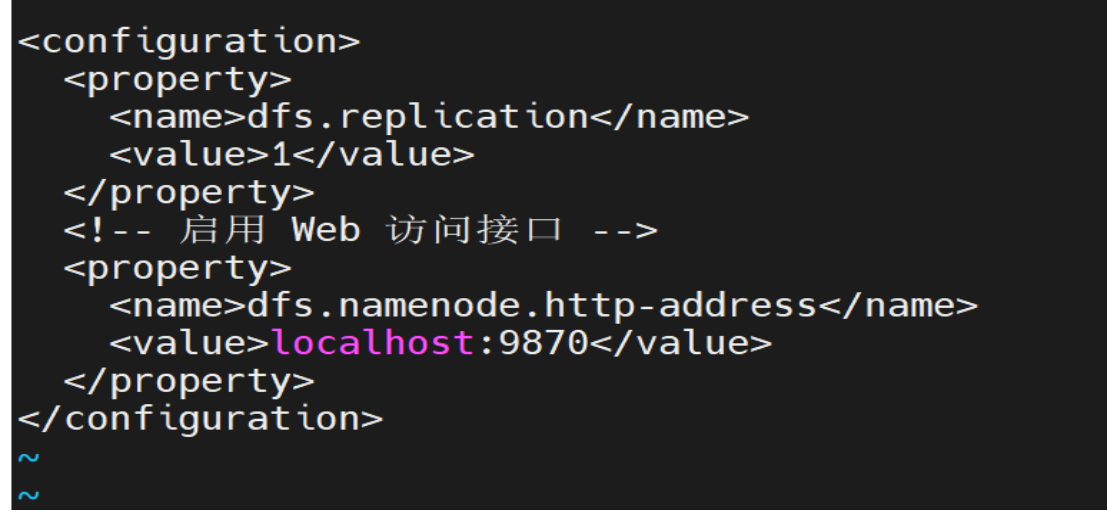
编辑 hdfs-site.xml
配置 HDFS 副本数(伪分布式设为 1):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 启用 Web 访问接口 -->
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:9870</value>
</property>
</configuration>
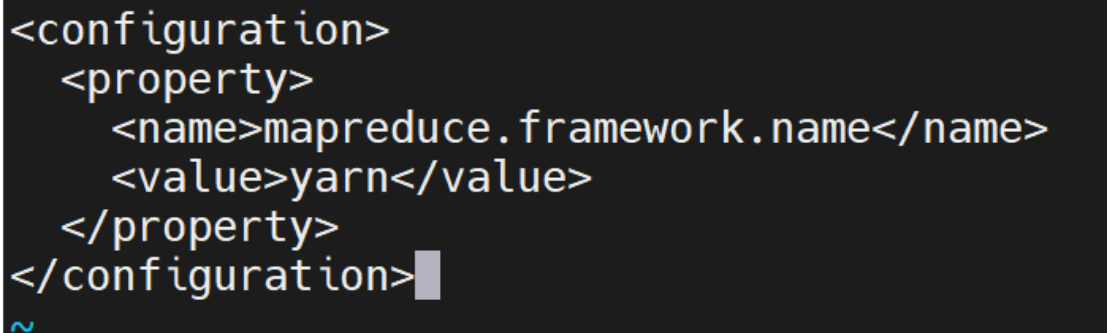
编辑 mapred-site.xml
指定 MapReduce 使用 YARN 框架
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
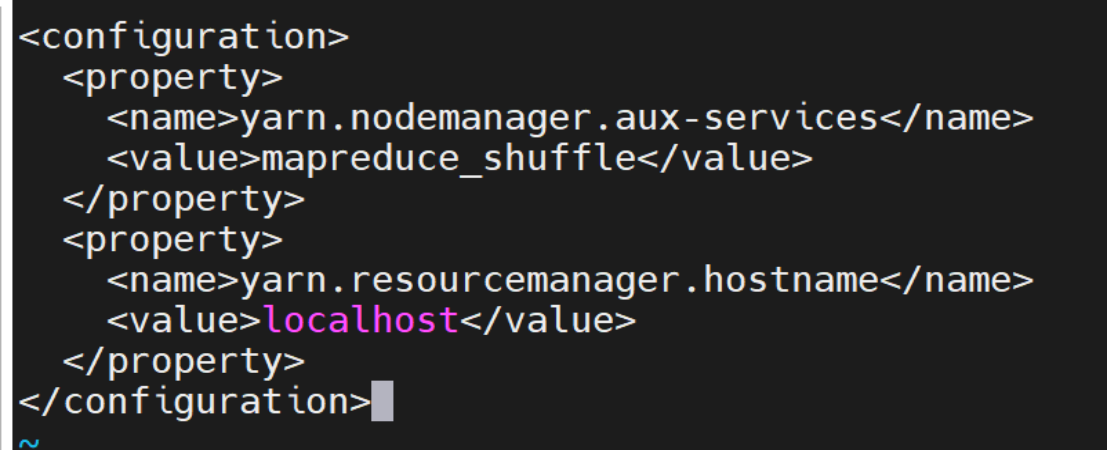
编辑 yarn-site.xml
配置 YARN 资源管理:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>
编辑 Hadoop 环境配置文件
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
export JAVA_HOME=/opt/jdk1.8 # 替换为你的实际路径
初始化HDFS
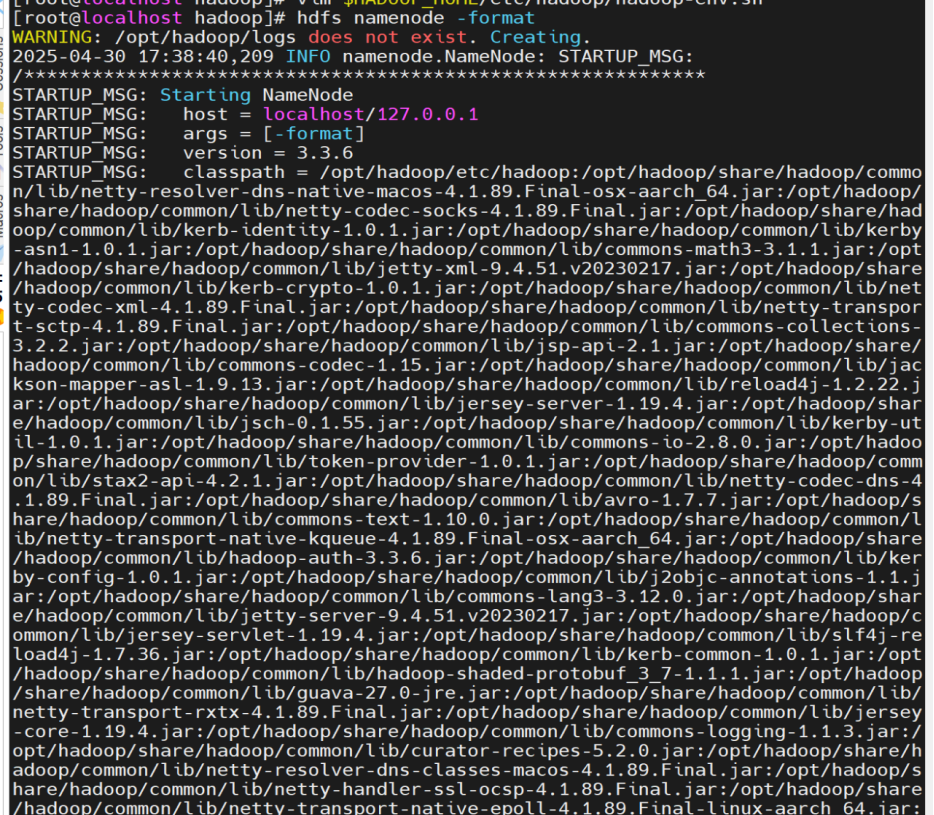
首次启动前需格式化 NameNode:
hdfs namenode -format
启动服务
./start-all.sh

查看
输入jps
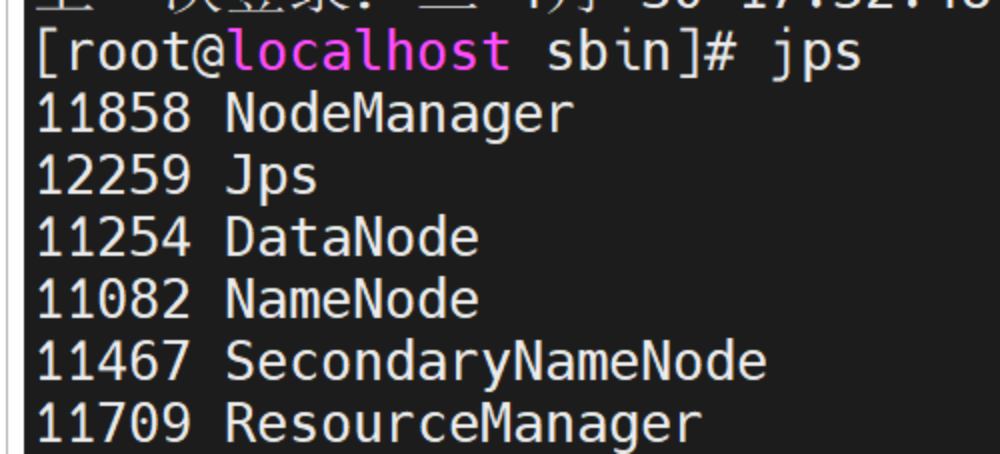
伪分布式配置完成。
完全分布模式
服务器准备
准备三台服务器:
node1:192.168.157.136
node2:192.168.157.137
node3:192.168.157.138
服务器基本配置
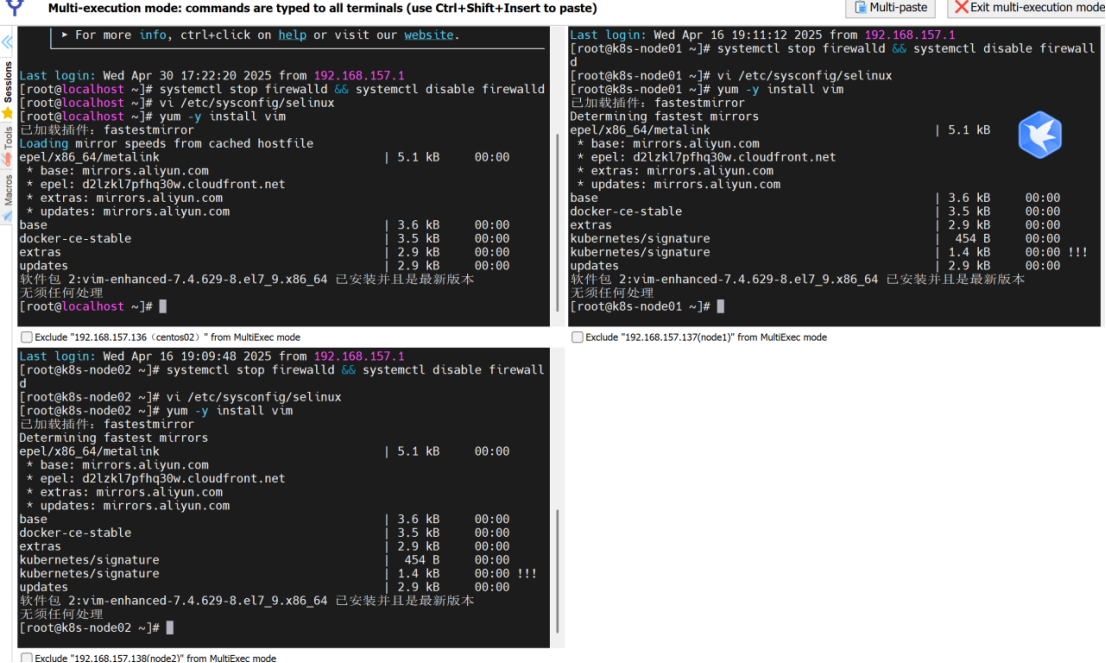
关闭和禁用防火墙
systemctl stop firewalld && systemctl disable firewalld
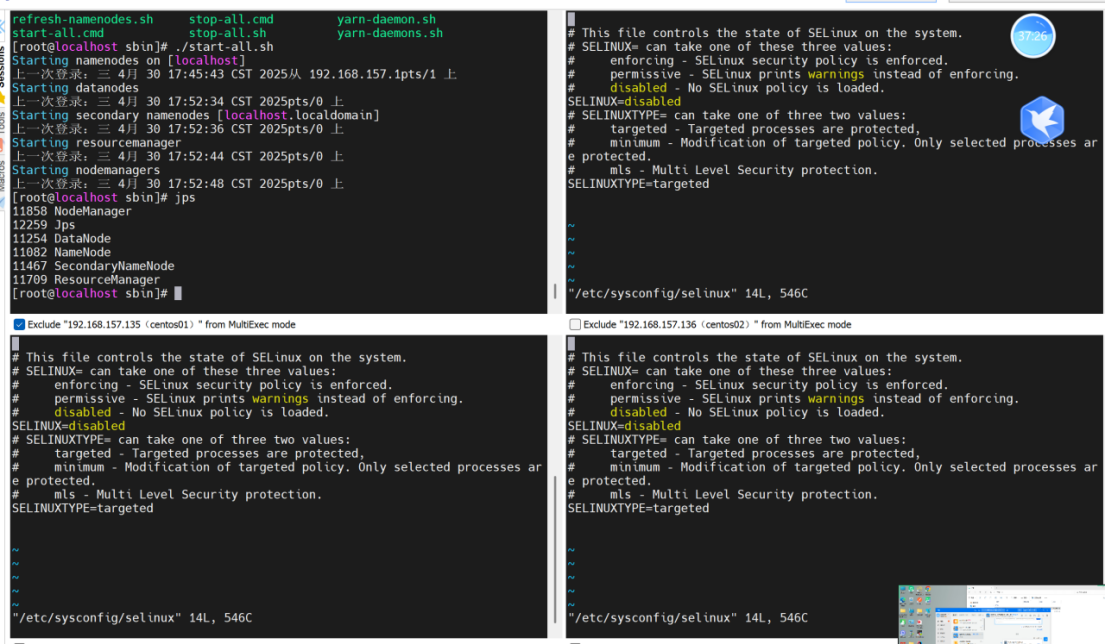
禁用selinux
#编辑selinux
vi /etc/sysconfig/selinux
#修改配置为disabled
SELINUX=disabled
#重启
reboot
三台机子安装vim
yum -y install vim
安装java
安装 JDK 1.8+(Hadoop 3.x 需 Java 8 或 11)
卸载以前的包
# 查询已安装的 JDK 包
rpm -qa | grep 'java\|jdk\|gcj\|jre'
# 卸载指定包(替换为实际查询结果)
yum -y remove java*
安装jdk并解压
tar -zxvf jdk-8u181-linux-x64.tar.gz
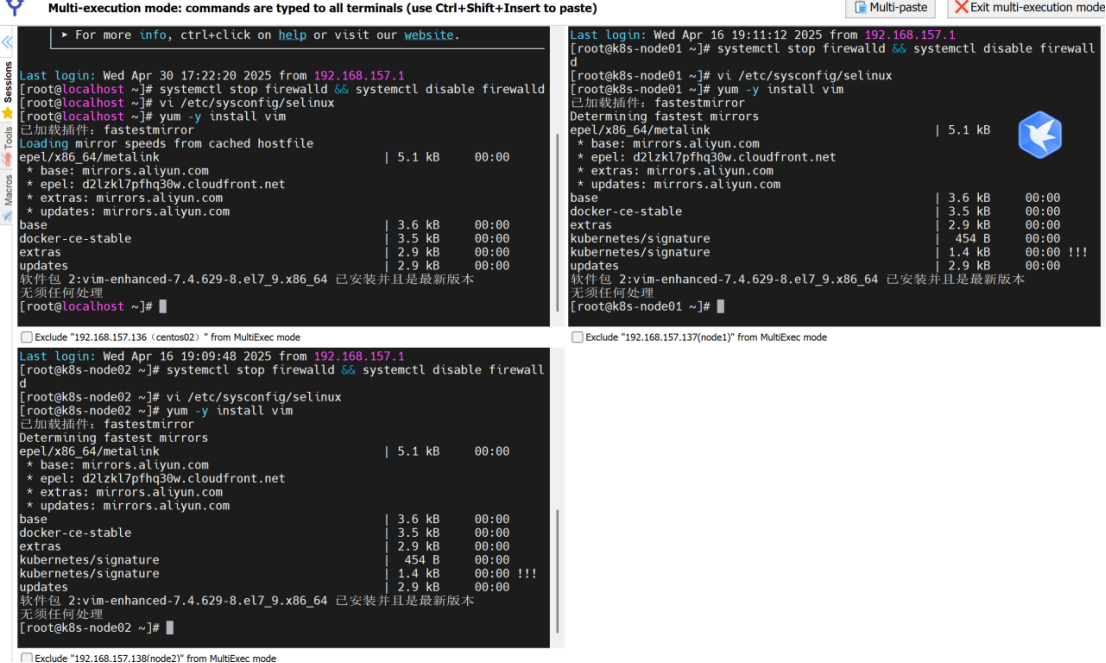
删除jdk包
#删除jdk包
rm -rf jdk-8u181-linux-x64.tar.gz
#重新命名
mv jdk1.8.0_181/ jdk1.8
配置环境变量
sudo vi /etc/profile
export JAVA_HOME=/opt/jdk1.8 #填写自己的jdk路径
export PATH=$JAVA_HOME/bin:$PATH

环境生效
source /etc/profile
检查
java -version

Hadoop基本配置
配置主机名和映射主机
修改主机名
vim /etc/hostname
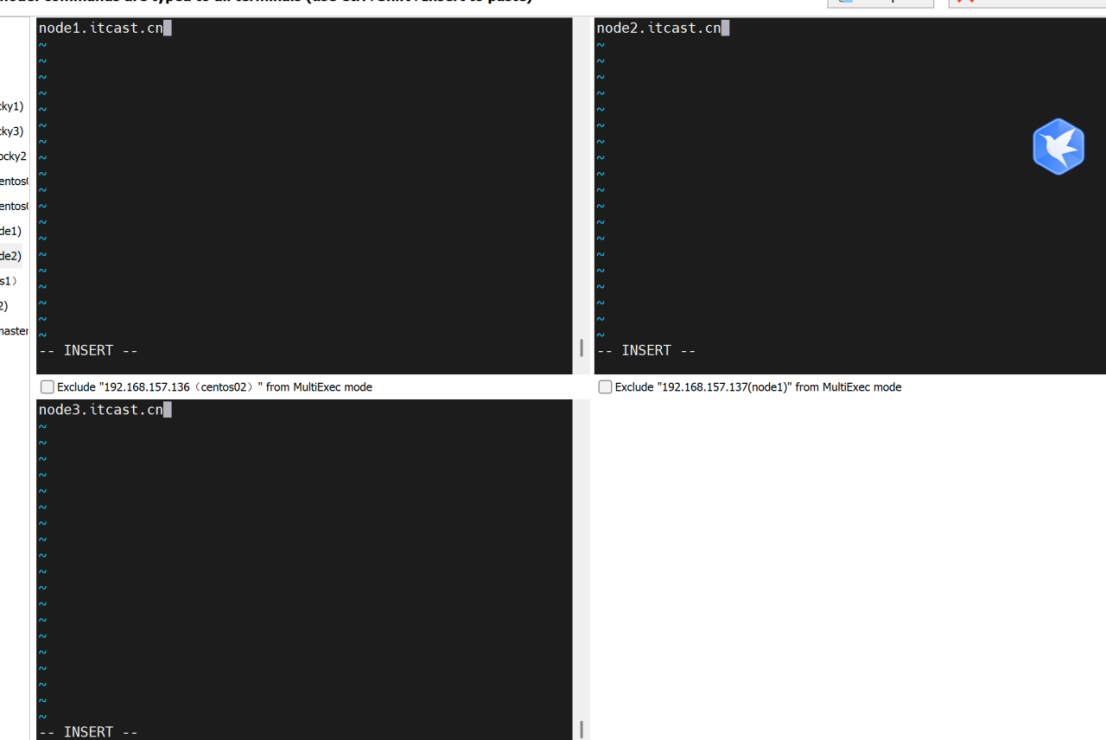
映射主机
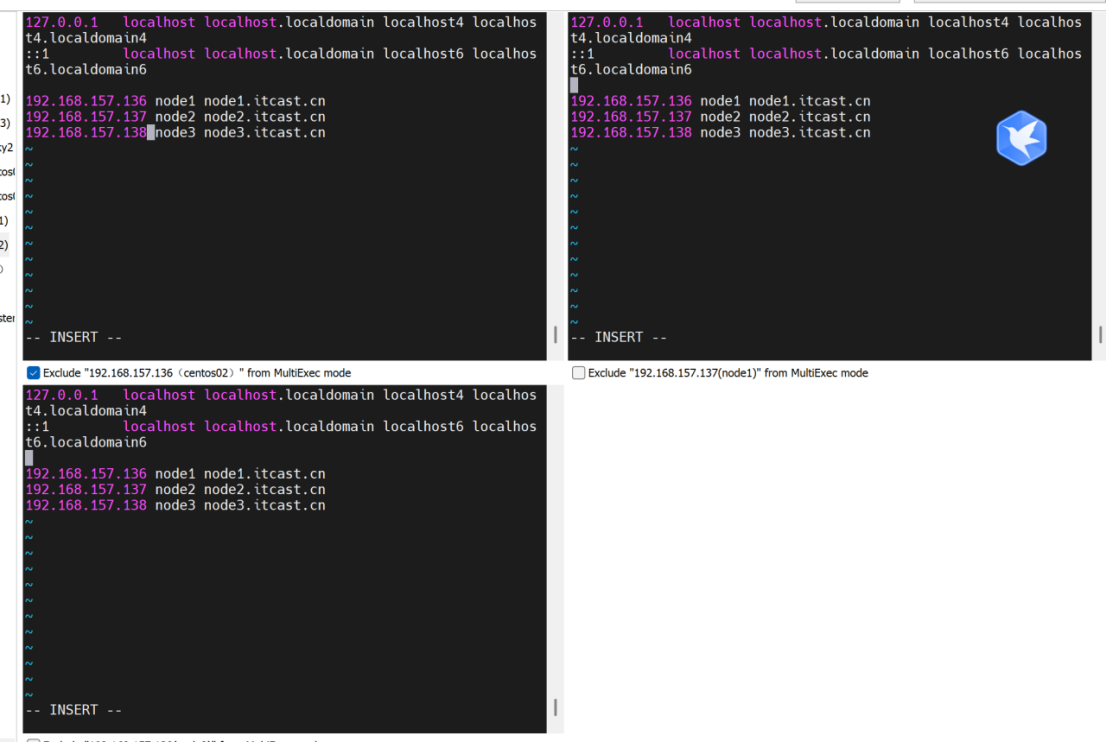
vim /etc/hosts
192.168.157.136 node1 node1.itcast.cn
192.168.157.137 node2 node2.itcast.cn
192.168.157.138 node3 node3.itcast.cn
重启
reboot
免密登录
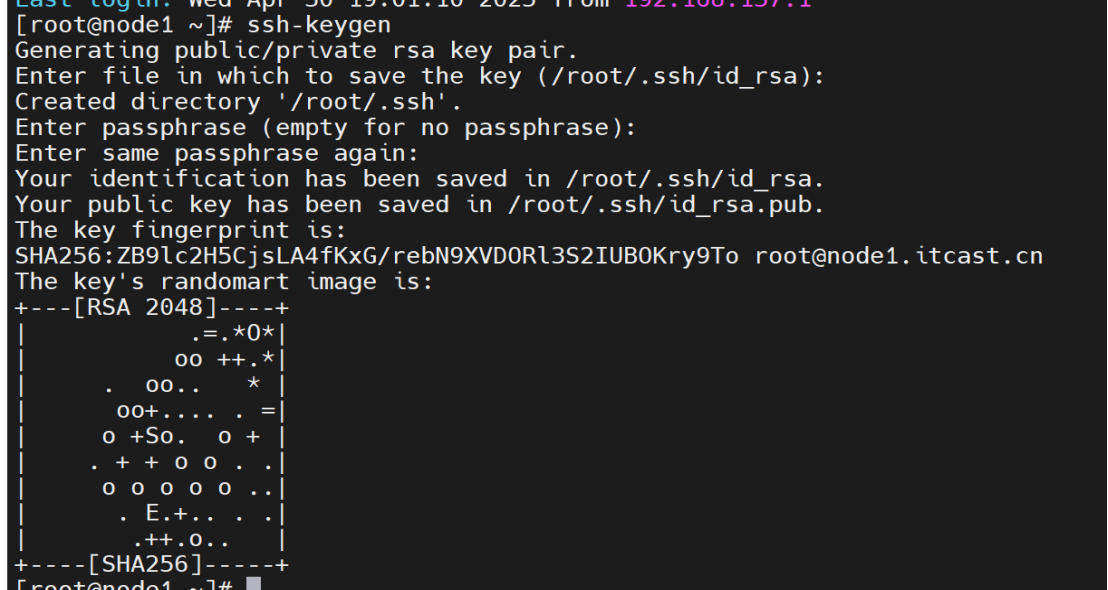
#生成公钥和私钥
ssh-keygen #四个回车
复制公钥
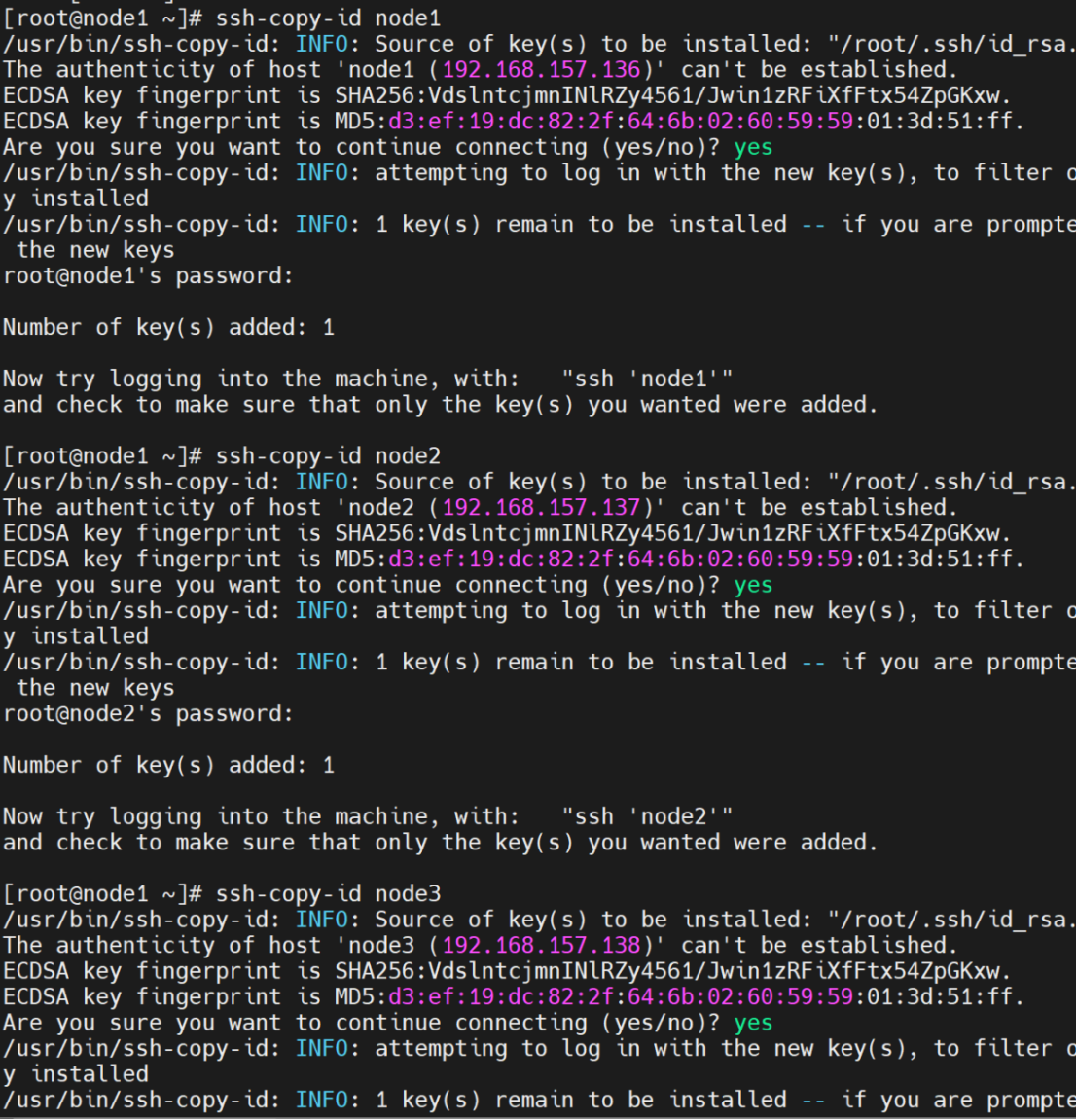
#复制公钥
ssh-copy-id node1 、 ssh-copy-id node2、 ssh-copy-id node3
登录服务器
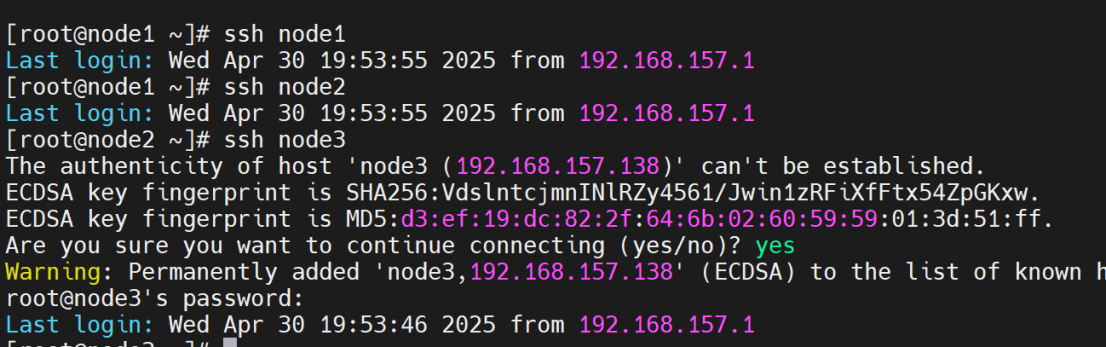
#登录服务器
ssh node1
ssh node2
ssh node3
#退出登录
exit
集群时间同步
安装ntp服务
#安装ntp服务
yum -y install ntpdate

三台机子都配置环境变量,并使其立即生效
#配置环境变量
echo 'export PATH=$PATH:/usr/sbin' >> ~/.bashrc # 写入用户环境变量
source ~/.bashrc # 立即生效
#使用阿里云同步
ntpdate ntp4.aliyun.com
#验证
date
创建工作目录
#软件安装路径
mkdir -p /export/server
#数据存储路径
mkdir -p /export/data
#安装包存放路径
mkdir -p /export/software
Hadoop安装
切换目录
cd /export/server
下载hadoop
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
解压删除包
tar -zxvf hadoop-3.3.6.tar.gz
rm -rf hadoop-3.3.6.tar.gz
进入hadoop
cd hadoop-3.3.6
配置环境
cd /export/server/hadoop-3.3.6/etc/hadoop
配置 hadoop-env.sh文件
vim hadoop-env.sh
export JAVA_HOME=/opt/jdk1.8
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
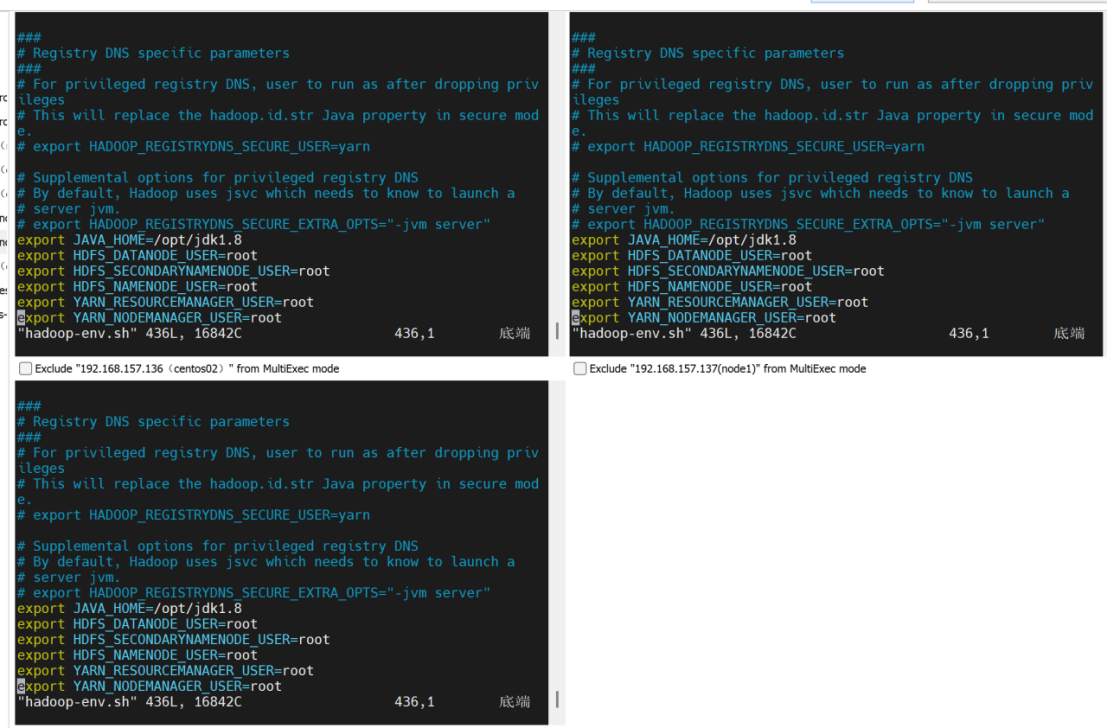
配置core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.6</value>
</property>
<property>
<name>hadoop.https.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
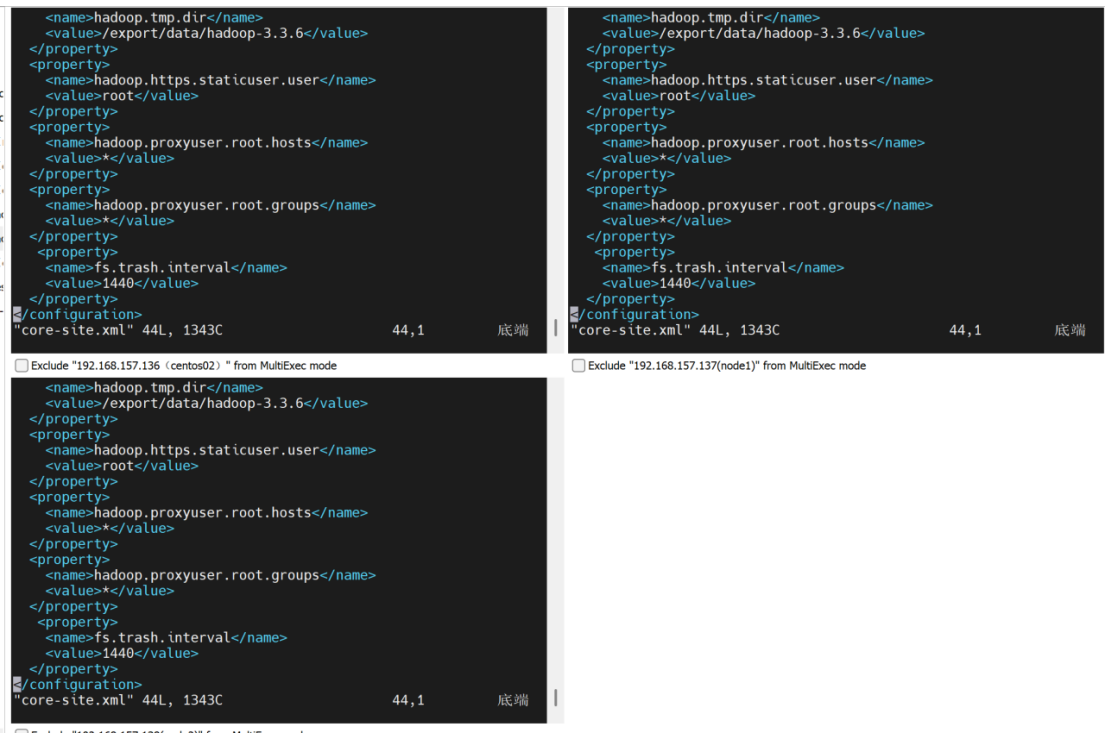
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
</configuration>
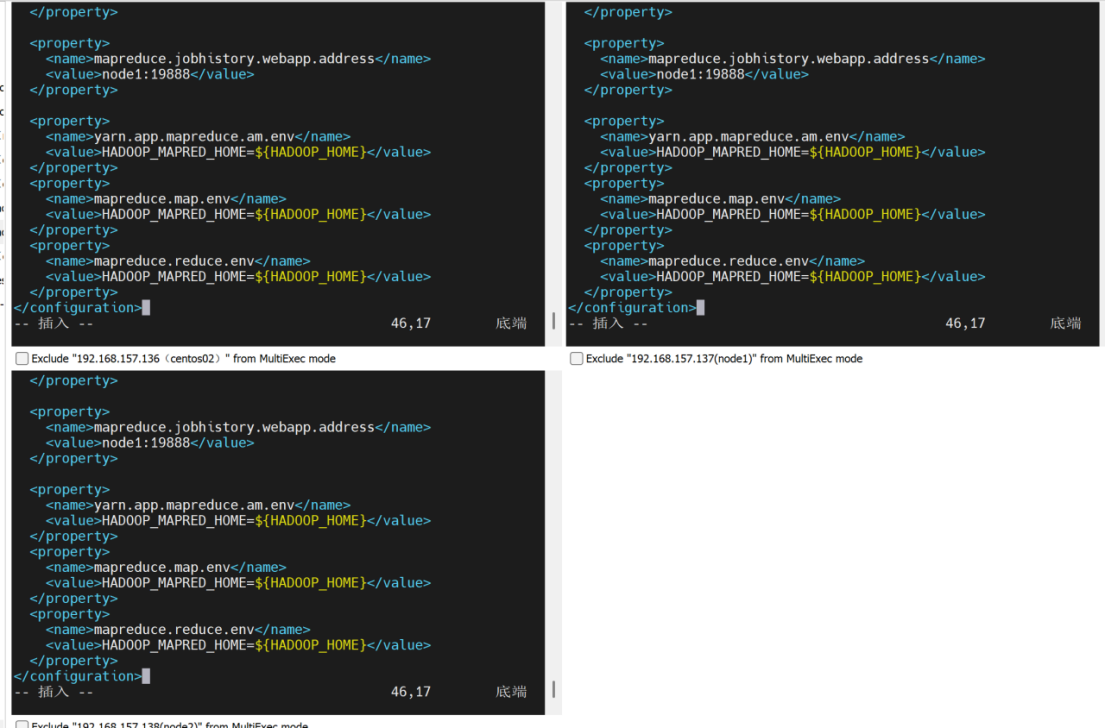
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
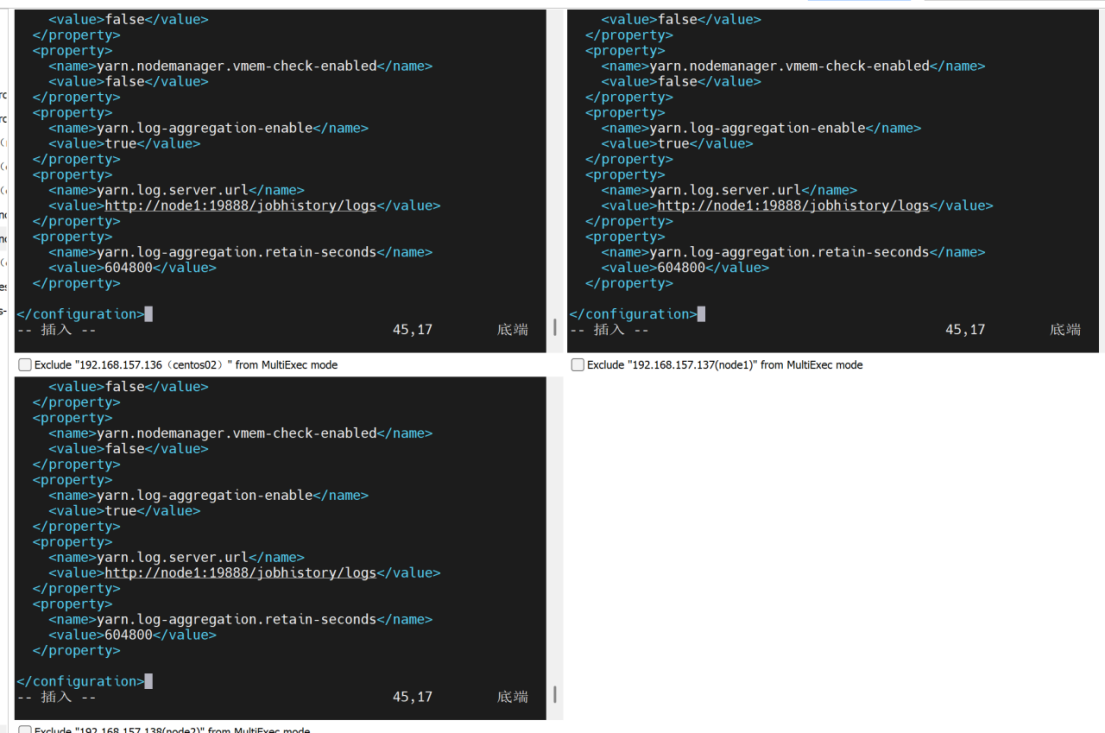
配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
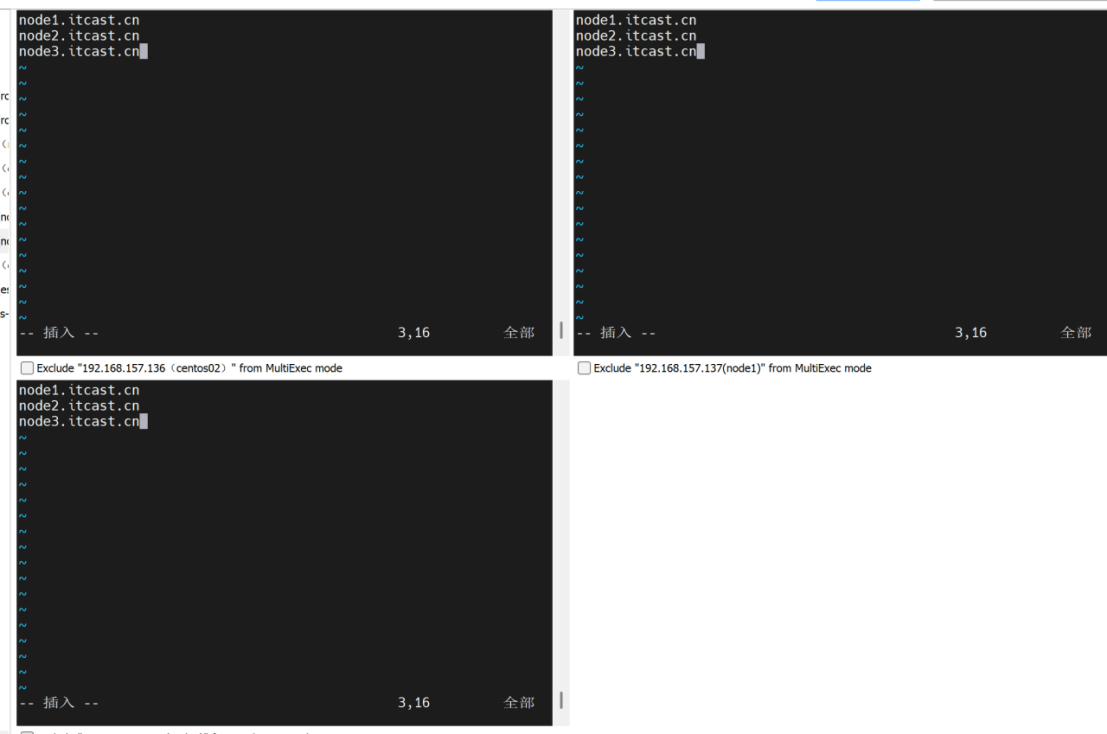
配置workers
vim workers
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
配置path环境
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
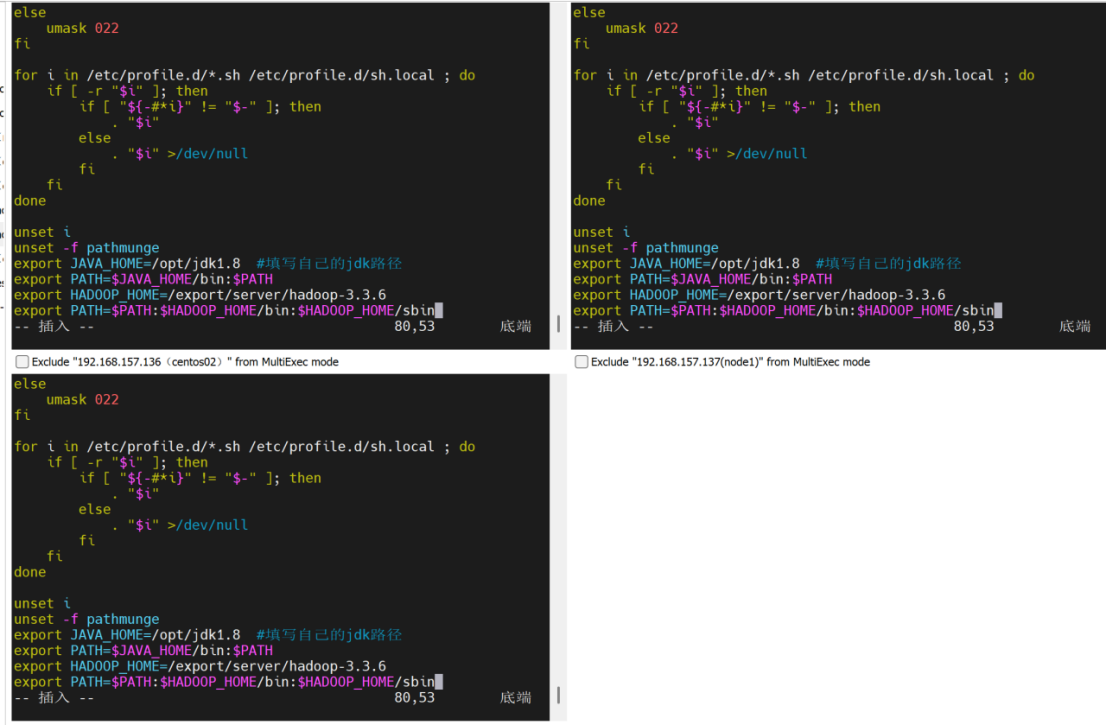
配置生效并验证版本
source /etc/profile
hadoop version
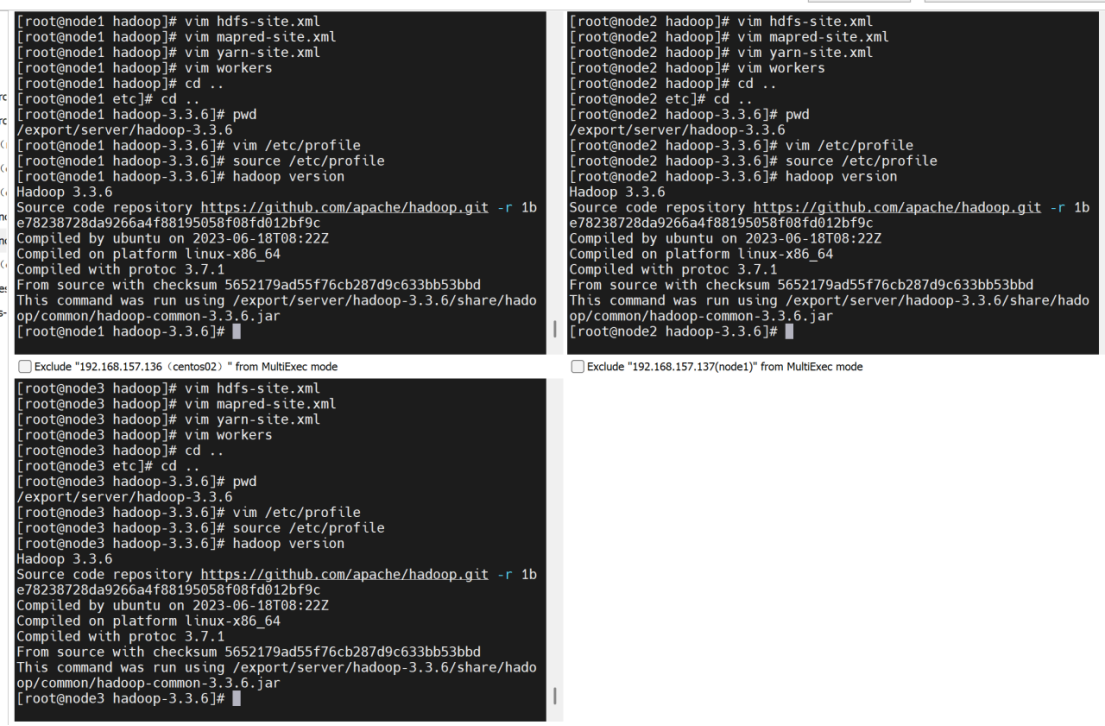
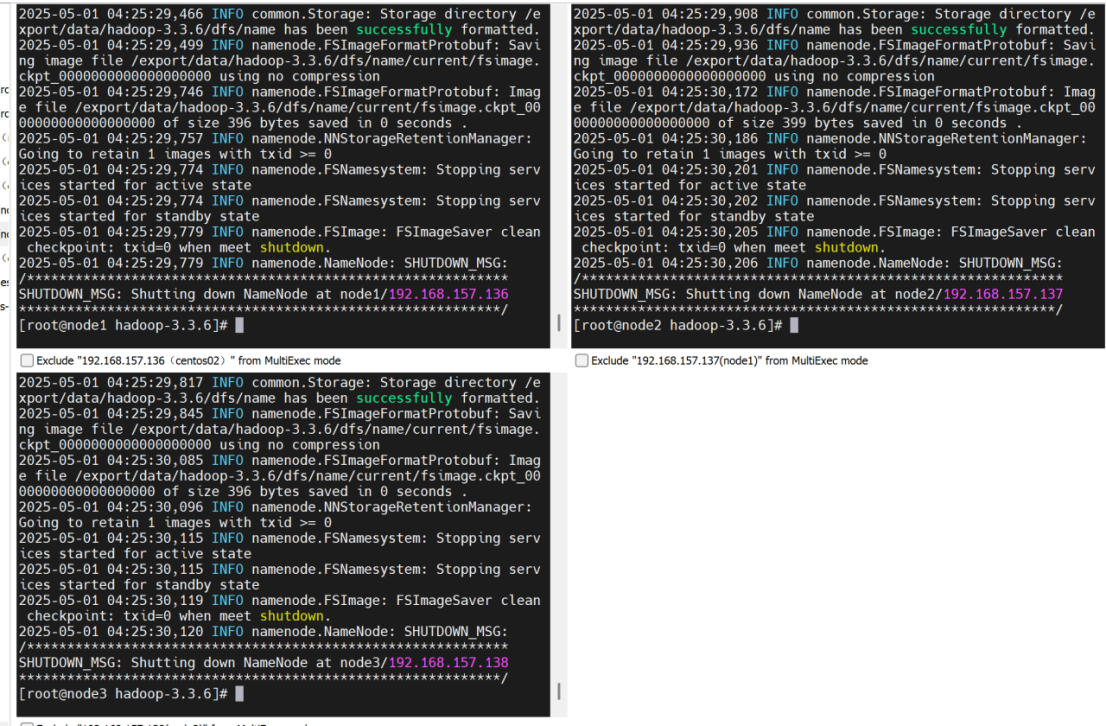
初始化hadoop
hdfs namenode -format
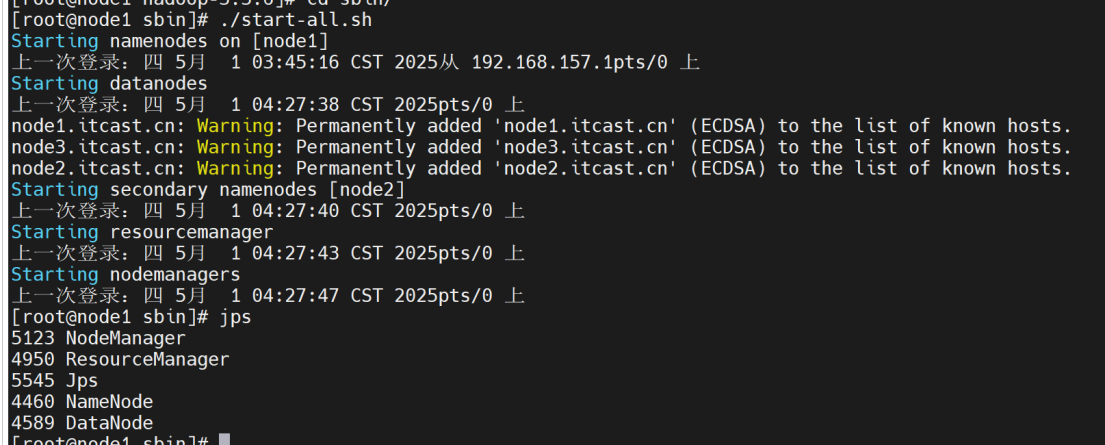
node1:启动所有服务并查看系统中正在运行的进程
./start-all.sh
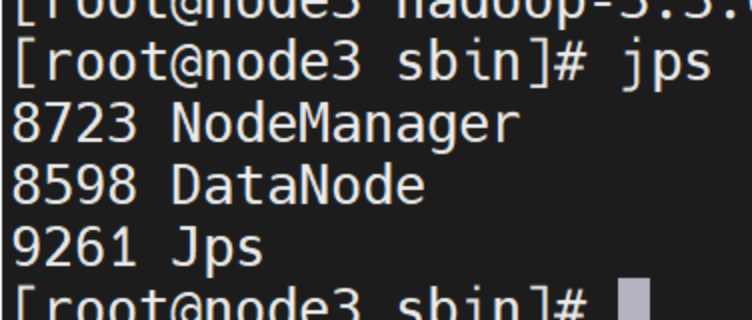
jps
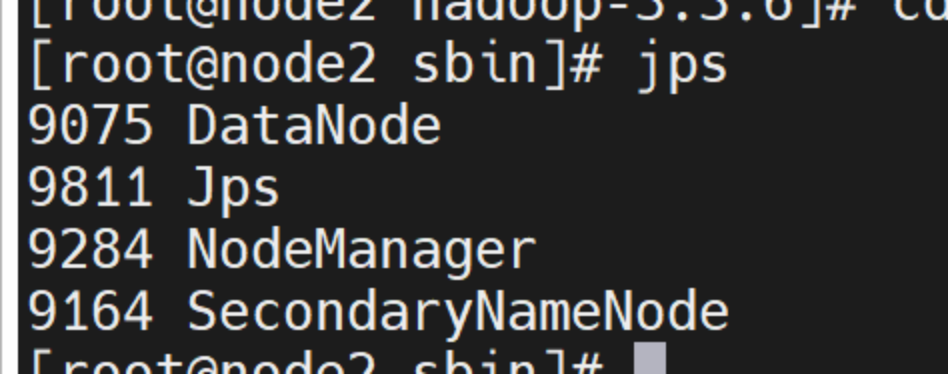
node2:查看系统正在运行的进程
node3:查看系统正在运行的进程
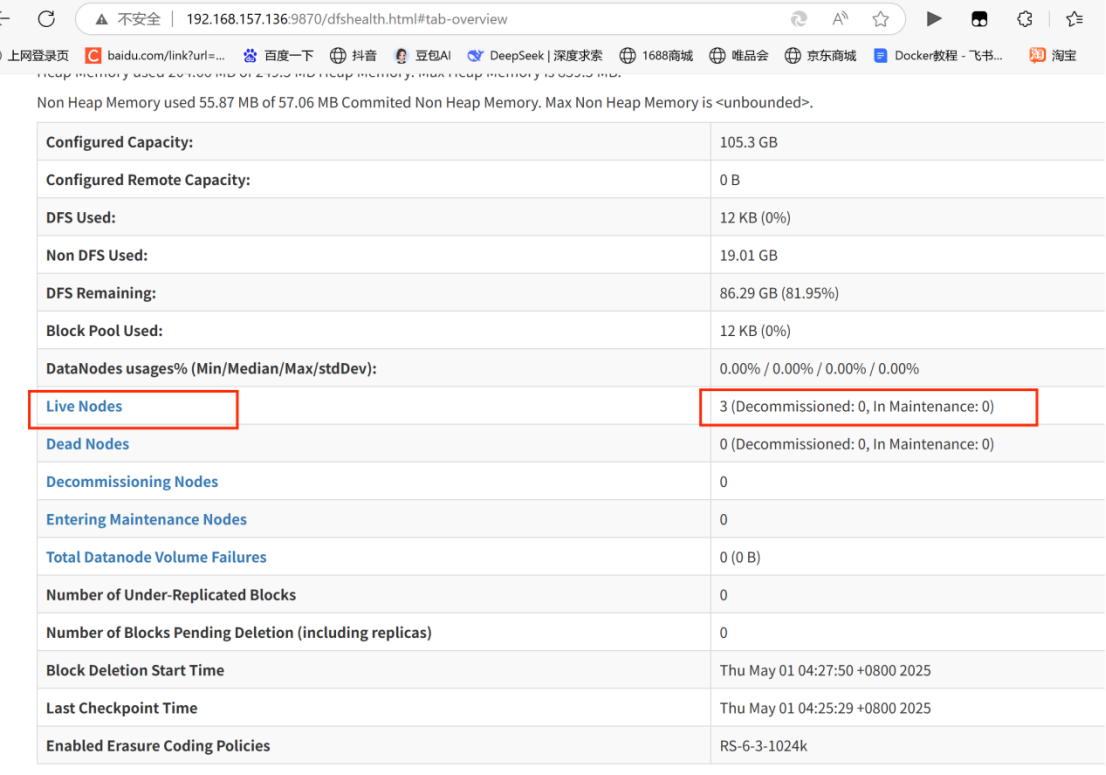
web页面
http://192.168.157.136:9870
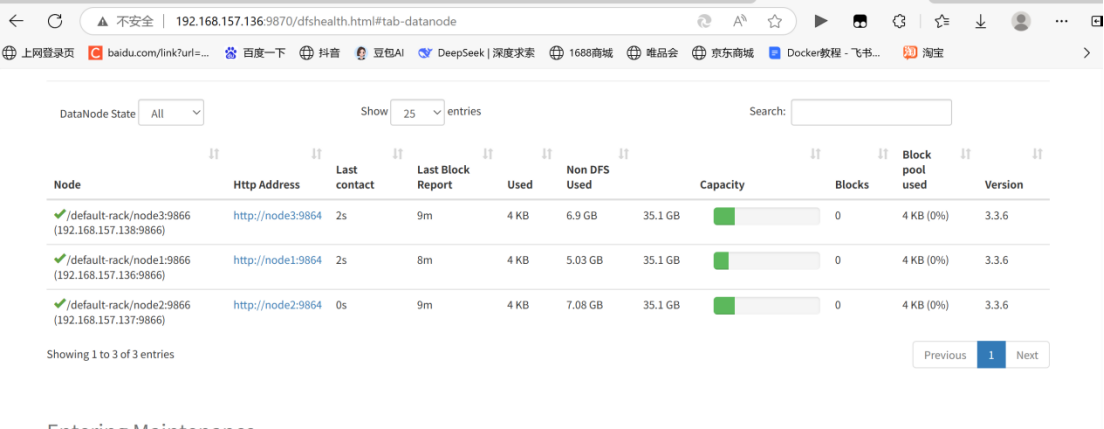
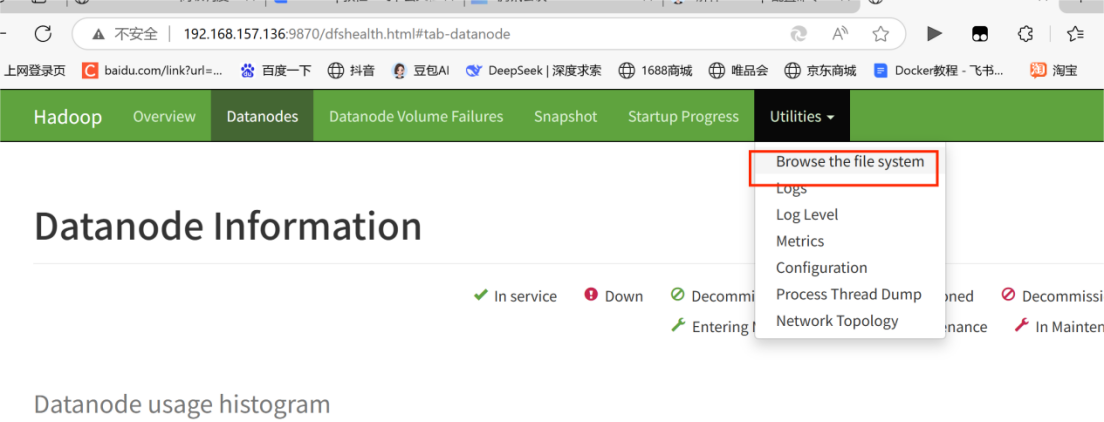
进入常用目录 文件浏览
进入yarn网页
http://192.168.157.136:8088
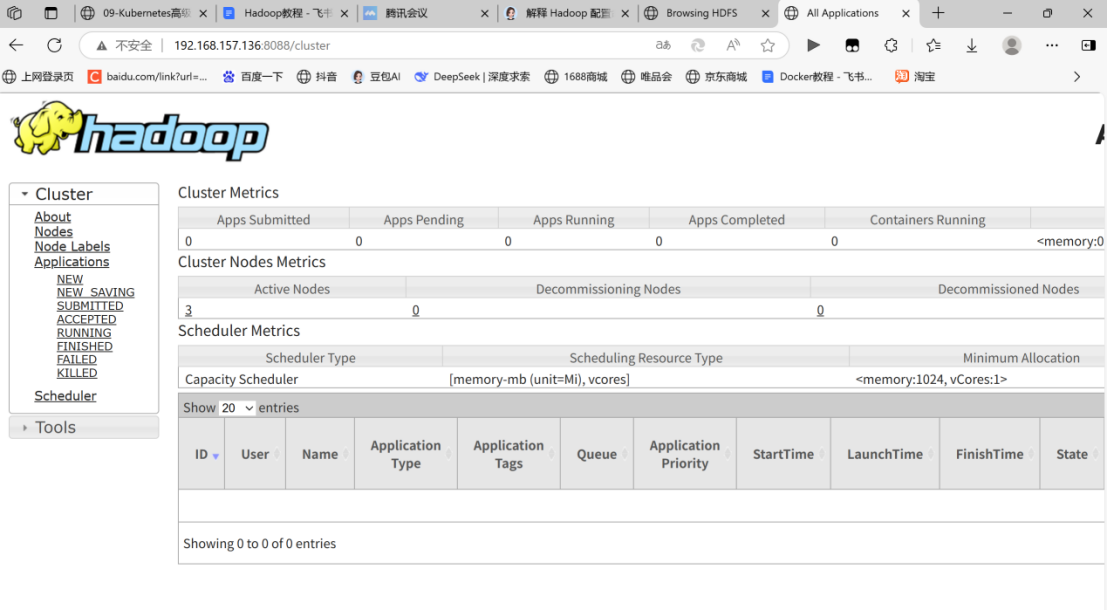
测试
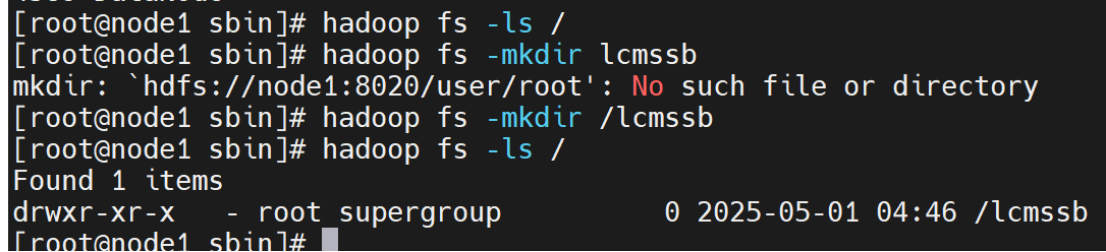
hadoop fs -ls /
hadoop fs -mkdir /zjjxy34 #目录名可自拟
hadoop fs -ls /
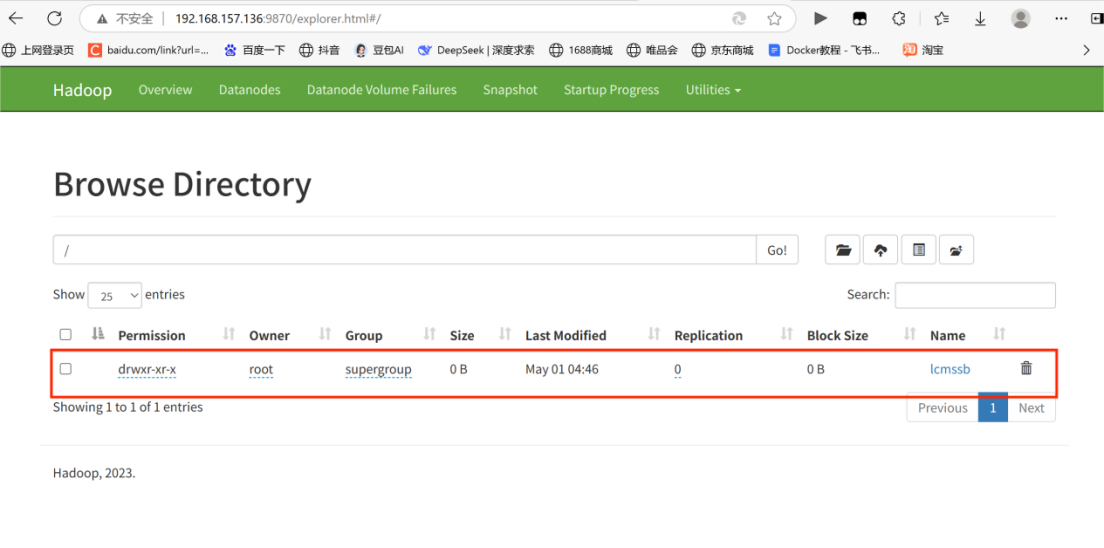
会在该界面出现刚刚创建的目录
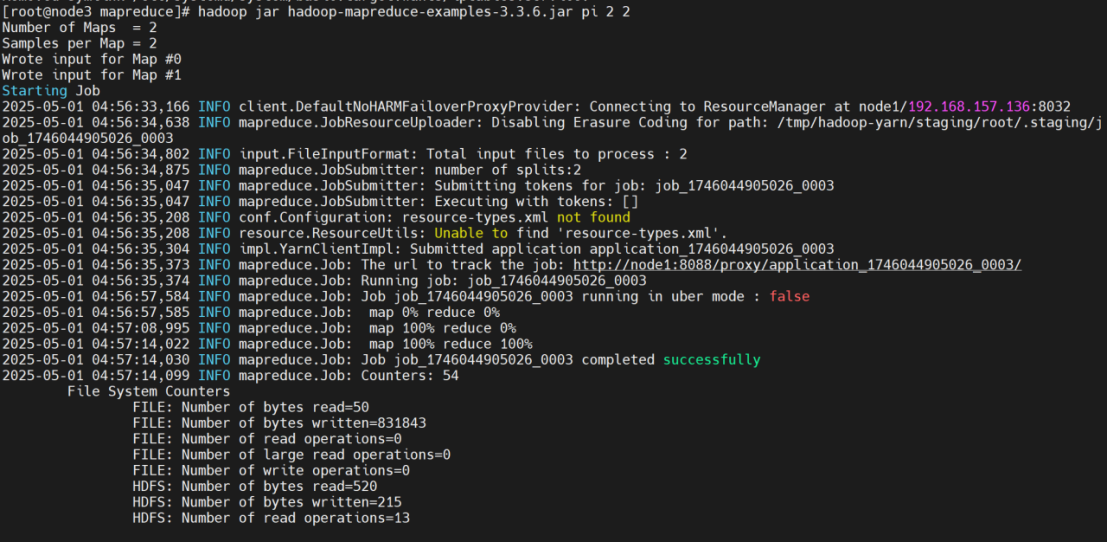
新建圆周率测试
cd /export/server/hadoop-3.3.6/share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-3.3.6.jar pi 2 2
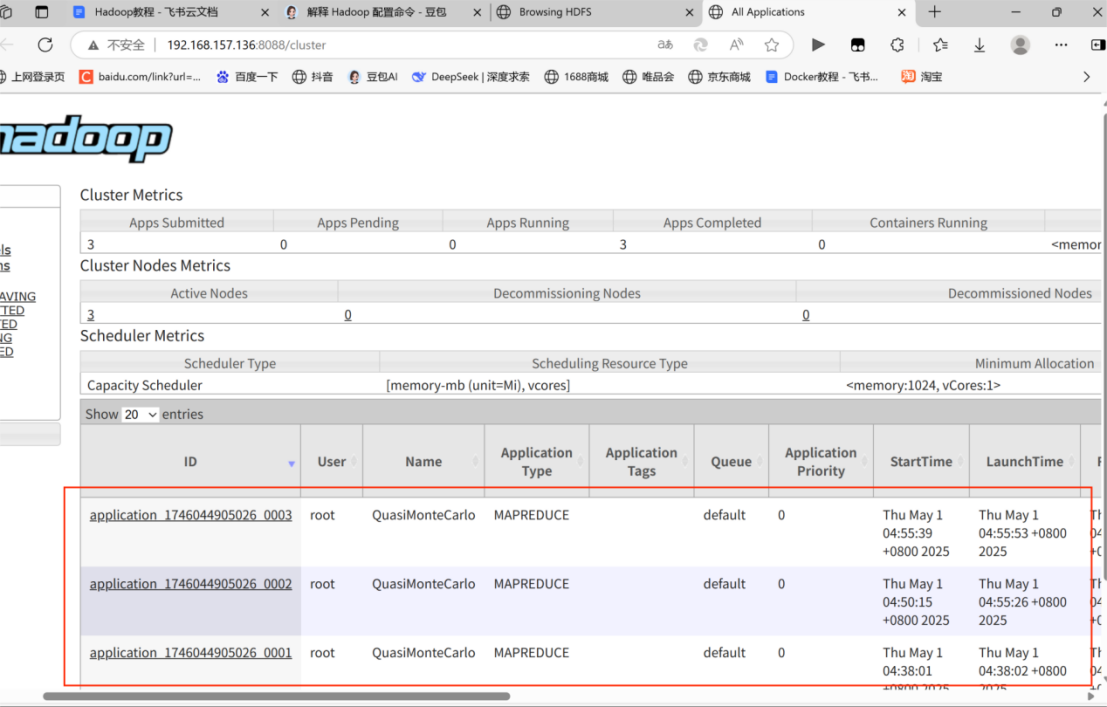
结论
伪分布式模式下,虽所有组件部署于单台机器,但各组件以独立进程运行,成功模拟了分布式环境。这种模式优势显著,在搭建方面,配置流程相对简便,极大降低了搭建成本与时间,仅需在一台机器上完成相关配置即可,对硬件资源要求低,在普通个人电脑上便能顺利搭建并运行。在功能验证与调试上,为开发人员提供了便利,可快速验证 Hadoop 相关功能及程序逻辑,如在测试 MapReduce 程序时,能便捷地观察程序运行过程、检查中间结果,快速定位逻辑错误,成为学习 Hadoop 原理与机制的理想选择,让初学者能在简单环境中逐步理解 Hadoop 的分布式理念。
然而,伪分布式模式局限性也较为明显。受限于单台机器的资源,其处理能力有限,无法应对大规模数据处理任务。在高并发场景下,单台机器的性能瓶颈会迅速显现,无法满足实际生产环境中对海量数据高效处理与高并发访问的需求。
完全分布式模式则截然不同,它构建于多台机器组成的集群之上,各节点各司其职,NameNode 与 ResourceManager 运行于主节点,负责管理元数据与计算资源调度;DataNode 与 NodeManager 分布在从节点,承担数据存储与具体任务执行工作。从配置角度看,该模式配置复杂,需考虑网络配置、节点间通信、资源分配等诸多因素,各节点的配置文件需精准设置且保持一致性,任何细微错误都可能导致集群运行异常。但在处理能力上,完全分布式模式优势突出,数据分布存储于多个节点,MapReduce 作业可在多台机器并行执行,能充分利用集群资源,对大规模数据集展现出强大的处理能力。实验中,在处理 TB 级别的数据时,完全分布式模式凭借并行计算优势,相比伪分布式模式,处理时间大幅缩短,展现出卓越的性能表现,在实际生产中,能为企业提供高可靠性与高可用性的数据处理服务,满足企业对海量数据处理的严苛需求。

















 44万+
44万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









