










12月26日,深度求索公司正式推出了其最新的开源模型——DeepSeek-V3,凭借671B的参数和创新的MoE架构,迅速引起了openAI等大厂公司的关注。今天我们将深入探讨 DeepSeek-V3 的性能表现,并且与市场上最顶尖的闭源模型GPT-4o和Claude-3.5-Sonnet进行全面对比,看看这款新模型是否真的如传闻中那样出色。一站式国产模型:DeepSeek-V3。
一、DeepSeek-V3的亮点
1. 性能对标顶尖模型
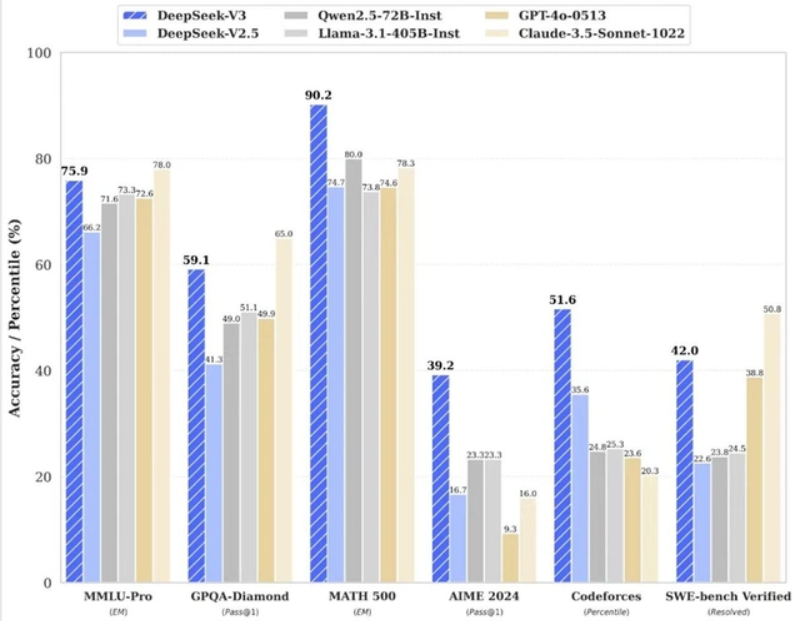
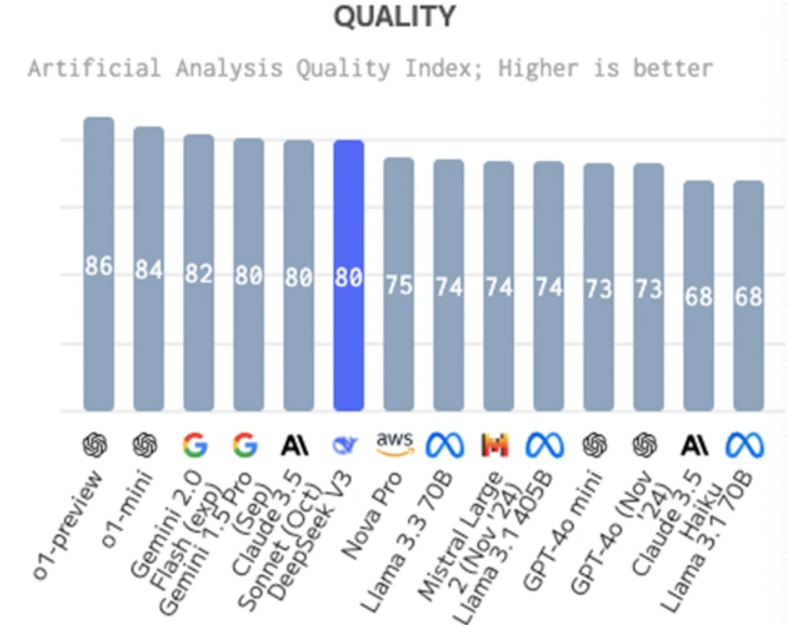
DeepSeek-V3在多项评测中表现出色,尤其是在与GPT-4o和Claude-3.5-Sonnet的对比中,显示出不俗的竞争力。根据独立评测机构Artificial Analysis的评估,DeepSeek-V3在质量指数上达到了80,超越了GPT-4o和Llama 3.3 70B,仅次于谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。
2. 训练成本的优势
DeepSeek-V3的训练成本仅为558万美元,这在当前的AI模型市场中可谓是一个惊人的数字。相比之下,Meta的Llama-3.1训练成本超过5亿美元,DeepSeek-V3的性价比无疑让人刮目相看。这一低成本的背后,得益于深度求索公司在优化策略上的创新,包括高效的负载均衡、FP8混合精度训练和通信优化等。
3. 开源模型的新标杆
DeepSeek-V3不仅在性能上与顶尖闭源模型相媲美,更在某些特定任务中超越了GPT-4o,成为开源模型的新标杆。这一成就的取得,标志着开源AI模型在性能和应用上的巨大进步。
二、DeepSeek-V3与竞争对手的对比
为了更直观地了解DeepSeek-V3的表现,我们将其与GPT-4o和Claude-3.5-Sonnet进行详细对比。
| 指标 | DeepSeek-V3 | GPT-4o | Claude-3.5-Sonnet |
|---|---|---|---|
| 参数量 | 671B | 175B | 175B |
| 训练成本 | 558万美元 | 10亿美元 | 5亿美元 |
| 质量指数 | 80 | 82 | 75 |
| 每100万个Token的价格 | 0.48美元 | 18美元 | 18美元 |
| 每秒生成Token数量 | 87.5 | 100 | 90 |
| 首字响应时间 | 1.14秒 | 0.9秒 | 1.0秒 |
| 上下文窗口 | 13万Token | 200万Token | 200万Token |
1. 质量与性能
从表格中可以看出,DeepSeek-V3在质量指数上略低于GPT-4o,但在训练成本和每100万个Token的价格上具有明显优势。虽然在生成速度和首字响应时间上稍显逊色,但其性价比的优势使得DeepSeek-V3在实际应用中更具吸引力。
2. 价格优势
DeepSeek-V3的每100万个Token价格仅为0.48美元,远低于GPT-4o和Claude-3.5-Sonnet的18美元。这一价格优势使得DeepSeek-V3在商业应用中更具竞争力,尤其对于中小企业和开发者而言,能够大幅降低使用成本。
3. 上下文窗口的局限性
尽管DeepSeek-V3在多个维度表现出色,但其上下文窗口仅支持13万个Token,远低于Claude-3.5-Sonnet的200万Token。这一局限性可能会影响其在某些复杂任务中的表现,尤其是在需要处理大量上下文信息的场景中。

三、DeepSeek-V3的应用前景
随着AI技术的不断发展,DeepSeek-V3凭借其高性价比和开源特性,展现出广阔的应用前景。无论是在自然语言处理、文本生成,还是在智能客服、内容创作等领域,DeepSeek-V3都有潜力成为开发者的首选工具。
四、总结
希望这篇文章能够帮助你更好地理解DeepSeek-V3的优势与潜力。如果你对AI模型有更多的疑问或想法,欢迎在评论区留言讨论!
相关文章
【OpenAI】(一)获取OpenAI API Key的多种方式全攻略:从入门到精通,再到详解教程!!


















 127
127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











