









本文精工学习参考
- 目标链接
'aHR0cHM6Ly93d3cuemhpaHUuY29tL3NlYXJjaD90eXBlPWNvbnRlbnQmcT1weXRob24='
-
接口分析
参数x-zse-93:相当于版本号
参数x-zse-96:看起来需要破解
参数x-zst-81:请求发现可以置空
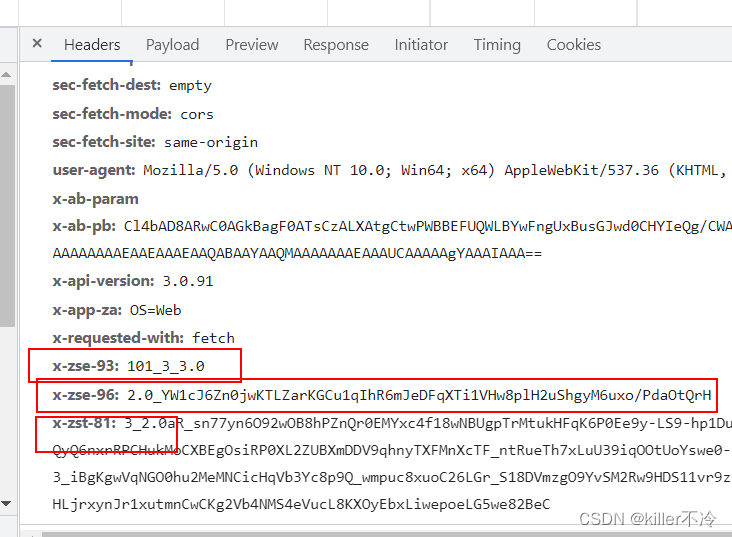
综上所述x-zse-96才需要逆向。 -
参数分析
-
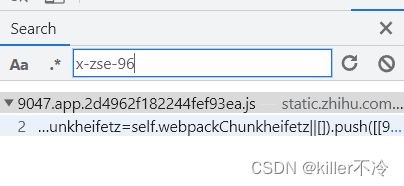
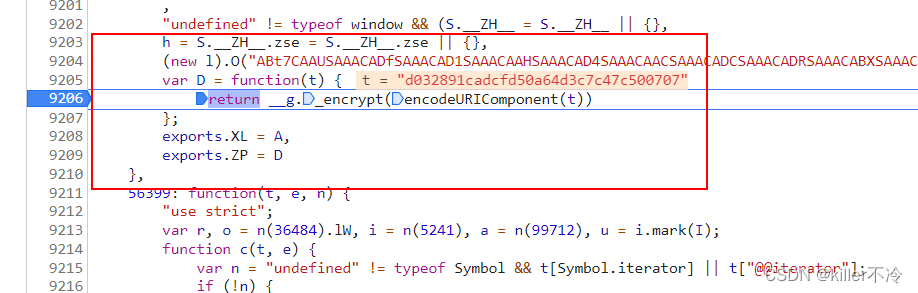
全局搜x-zse-96可以看到就只有一个文件包含。
-
往下滑可以看到E就是需要破解的参数,而E又是通过S.signature。往上看可以看到signature
signature: (0,M(r).encrypt)(f()(s))
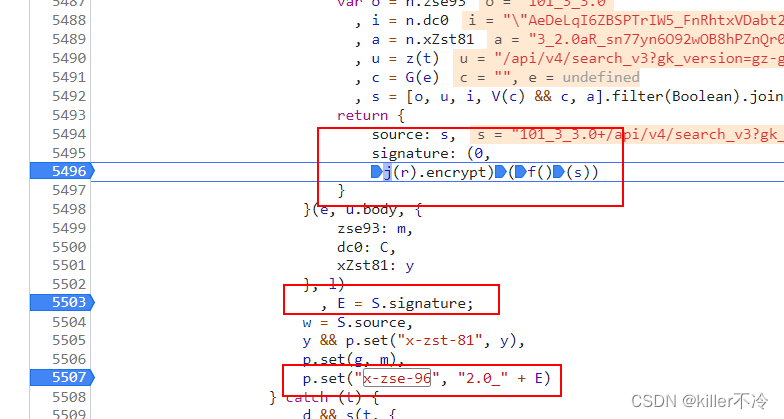
- s参数就是在上述进行拼接而成的。
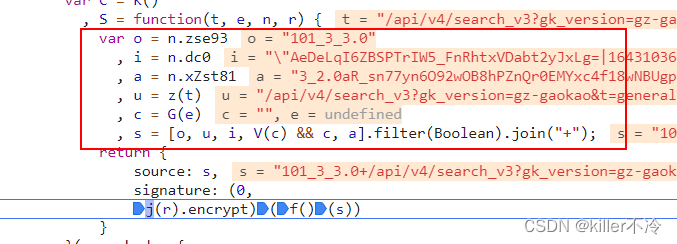
var o = n.z
i = n.dc0
a = n.xZst81
u = z(t)
c = G(e)
s = [o, u, i, V(c) && c, a].filter(Boolean).join("+");
参数o:固定的版本好
参数i:cookie中的dc0参数
参数a:就是参数x-zst-81可以为空
参数u:将请求体通过&拼接 t就是请求体,z函数就是拼接函数
参数c:为"",参数e为未定义
-
拆分加密函数,就是将s执行了f()函数,在执行了加密函数。
根据测试f(s)就是将s值进行了md5操作。 -
再看看先进去encrypt函数,接着在单步调试的时候,发现会在各个函数之间反复横跳。看到这个前面有一个很长的字符串【AxjgB5MAnACoAJwBpAAAABAAIAKcAqgAM*****】,这种很有可能就是jsvmp
-
多次执行发现结果是不同的。而做过2版本的就是到这里应该是一样的才对。
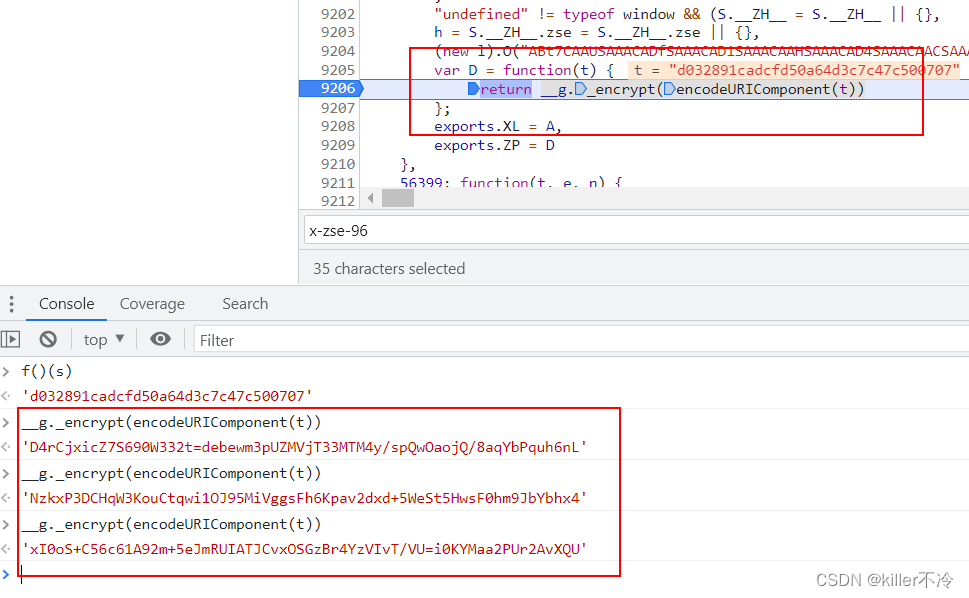 猜想可能存在随机值?
猜想可能存在随机值?
-
根据上述采集对随机值函数进行改写,此时就发现结果都是一样的了
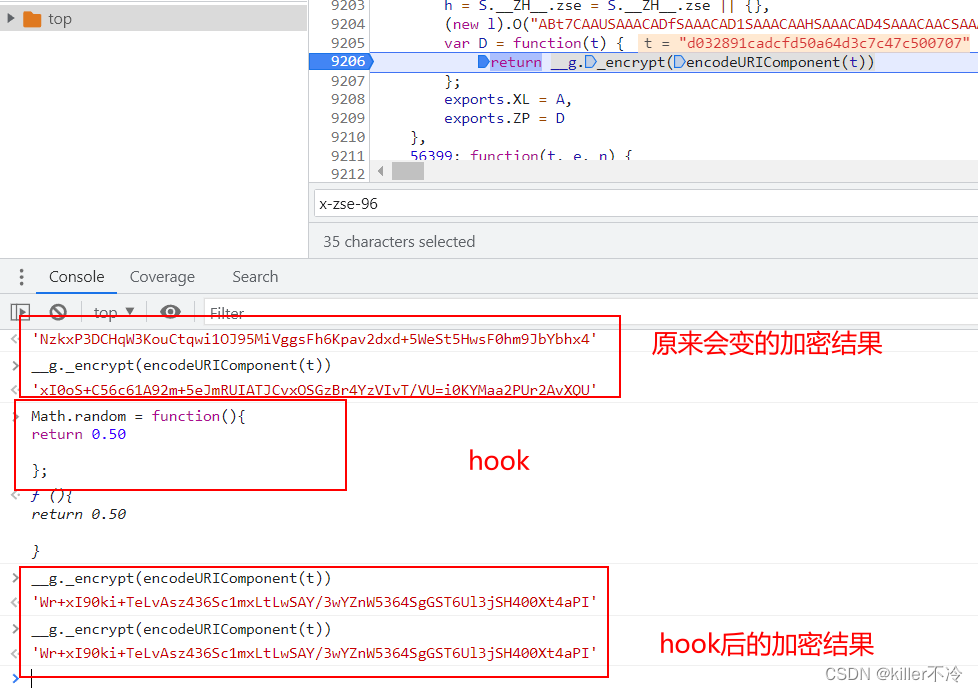
那么此时就得到了一组样本,当随机数恒定返回0.5时。入参【‘d032891cadcfd50a64d3c7c47c500707’】的正确结果为【t=‘Wr+xI90ki+TeLvAsz436Sc1mxLtLwSAY/3wYZnW5364SgGST6Ul3jSH400Xt4aPI’】,那么接下在就真正可以开始补环境了 -
看结构可以发现它是webpack的,将加密的整个扣下来
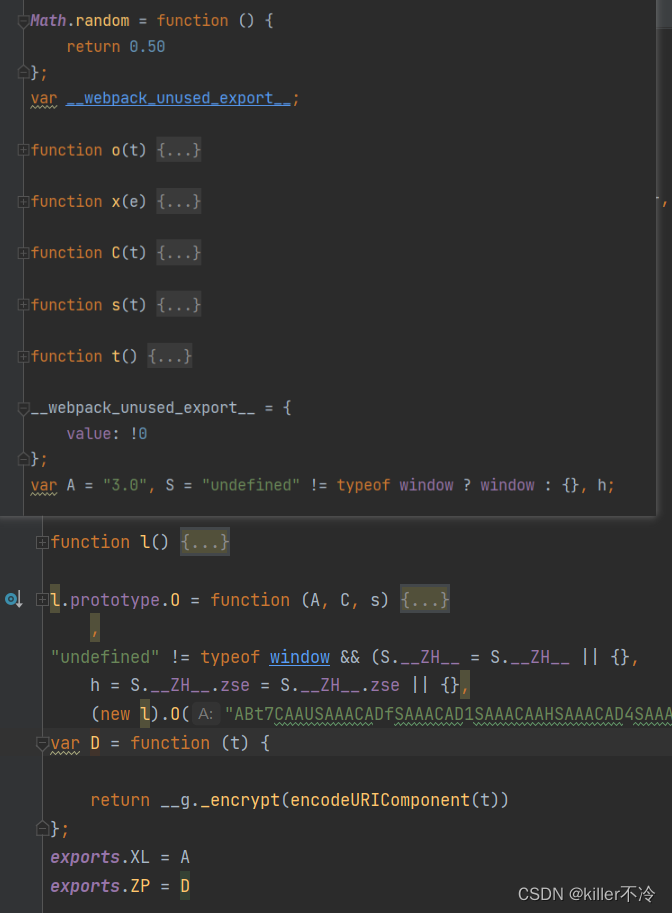
导出时候会发现报错
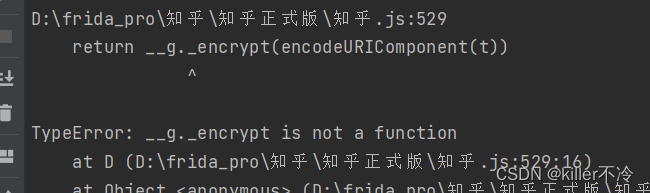
-
通过使用jsdom去补环境,也可以使用vm2
const{JSDOM}=require("jsdom");
const dom=new JSDOM("<!DOCTYPE html><p>Hello world</p>");
window=dom.window;
document=window.document;
navigator=window.navigator;
location=window.location;
history=window.history;
screen=window.screen;
Math.random = function () {
return 0.50
};
会保存atob未定义 ReferenceError: atob is not defined
这个 atob 是将 base64 加密的字符串给解密,在 node 环境下是没有这个方法的,我们需要使用 Buffer.toString()替代即可。
// D = atob(A),
D = Buffer.from(A, 'base64').toString("binary"),
- 补完之后就可以生成值了,但是明显可以发现值既然不对

那就需要通过设置代理进行补环境了。
window = new Proxy(window, {
set(target, property, value, receiver) {
console.log("设置属性set window", property, typeof value);
return Reflect.set(...arguments);
},
get(target, property, receiver) {
console.log("获取属性get window", property, typeof target[property]);
return target[property]
}
});
这只是其中一个对象(window)的的代理,正确的可以将它封装成函数,一个个个对象去调用。但是我这里直接使用了(记得将所有对象都代理上)。
- 可以看到读取了不少属性,最后运行到【获取属性get document Symbol(Symbol.toStringTag) string】这一步就退出了,那么看看这一步的结果是不是和网页不一样。
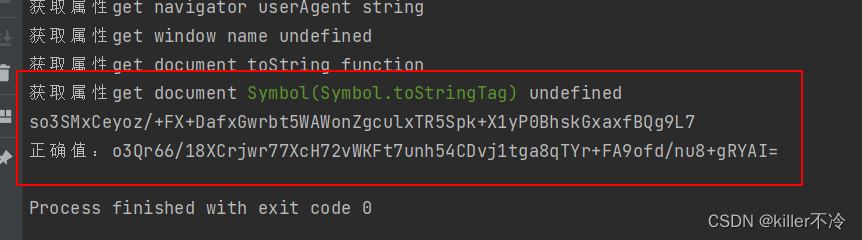
可以发现toString()浏览器结果和node结果不同的,因此需要hook将toString()方法去掉(也就是保护机制)。

var Object_toString = Object.prototype.toString;
Object.prototype.toString = function () {
let _temp = Object_toString.call(this, arguments);
console.log(this);
console.log("Object.prototype.toString: " + _temp);
if(this.constructor.name === 'Document'){
return '[object HTMLDocument]';
}
return _temp;
};
- 再次运行可以发现日志比之前更加长了,说明补的内容是有效的,但是跟结果还是存在不同的
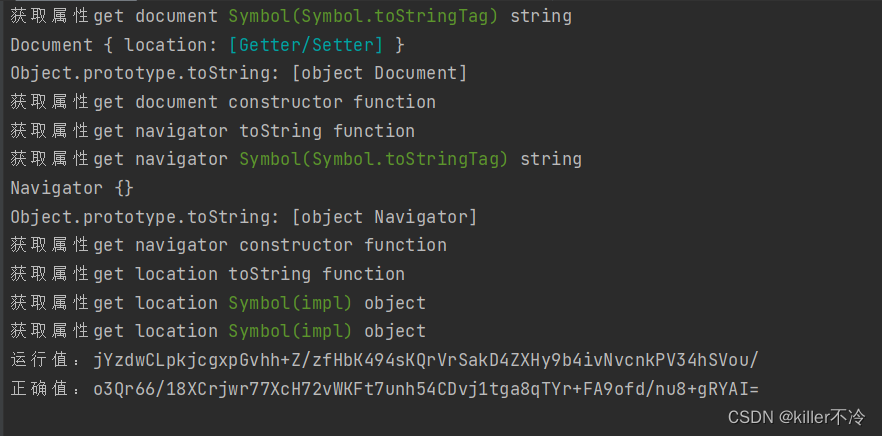
location对象出现问题,那么在jsdom上面,就需要补上url链接,那么就会自动补全location对象,开头部分的代码就修改成。
const{JSDOM}=require("jsdom");
const dom=new JSDOM("<!DOCTYPE html><p>Hello world</p>",{url:'https://www.zhihu.com/search'});
window=dom.window;
document=window.document;
navigator=window.navigator;
location=window.location;
history=window.history;
screen=window.screen;
- anvas和网页返回不一样,需要继续补上。
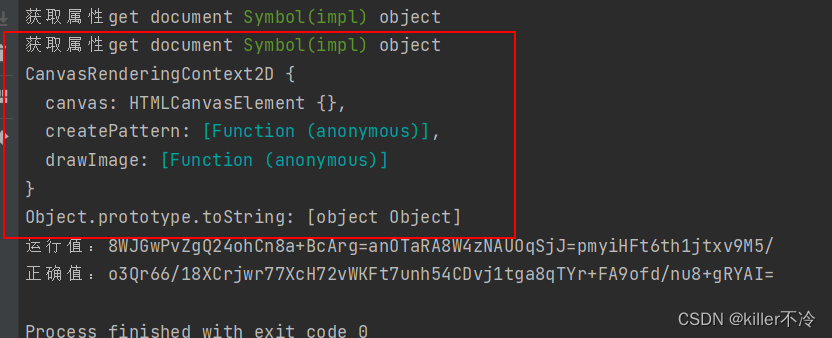

// var Object_toString = Object.prototype.toString;
Object.prototype.toString = function () {
let _temp = Object_toString.call(this, arguments);
// console.log(this);
// console.log("Object.prototype.toString: " + _temp);
if(this.constructor.name === 'Document'){
return '[object HTMLDocument]';
}else if(this.constructor.name === 'CanvasRenderingContext2D'){
return '[object CanvasRenderingContext2D]'
}
return _temp;
};
- 继续跑,这次检测了window下的_resourceLoader,浏览器上是undefined,但是node返回时对象。需要赋undefined,运行之后还会确实_sessionHistory同样时赋undefined。
window._resourceLoader = undefined
window._sessionHistory = undefined
- 运行报错 alert未定义
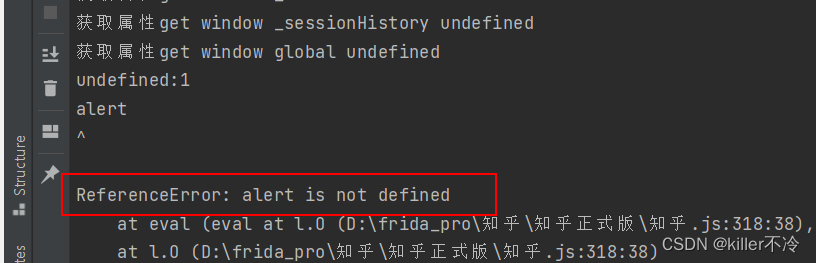
alert = window.alert;
- 结果还是不同,并且获取了window的原型后就没有了,那么这种情况很可能检测了原型链和函数或者toString(),那么需要hook一下。
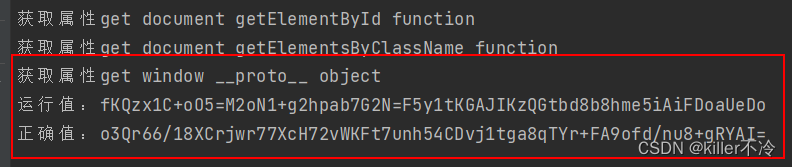
var Function_toString = Function.prototype.toString;
Function.prototype.toString = function () {
let _temp = Function_toString.call(this, arguments);
if(this.name === 'Window'){
return 'function Window() { [native code] }'
}
return _temp;
};
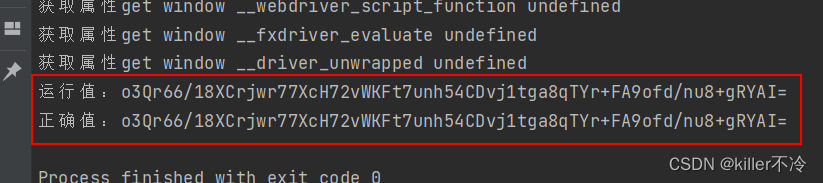
补完之后发现值一样了。
如果有需要可以请教博主。















 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









