







目录
3.3 Embedded method(也叫Hybrid method)
6.1 使用一个无监督/有监督的分类器,在一个具体任务上对UFS方法选择出的特征进行评估。
前言
本博客是我根据自己对“无监督特征选择”这个领域的调研结果。其中主要的框架参考了论文《A review of unsupervised feature selection methods》(Solorio-Fernández,2020) ,结合其他一些资料来源,加上自己对相关概念的思考、理解。若有不妥之处,欢迎交流。
1. 无监督特征选择(UFS)算法概述
特征选择(Feature Selection,FS)可以分为有监督特征选择(Supervised Feature Selection),半监督特征选择(Semi-Supervised Feature Selection)和无监督特征选择(Unsupervised Feature Selection)
无监督特征选择(Unsupervised Feature Selection,UFS)有别于监督特征选择,对于样本,仅有其特征信息,没有其类别信息,在这样的前提条件下进行特征选择。
无监督特征选择是三类特征选择任务中最为困难的一个任务。
在无监督特征选择任务中,我们需要尽可能地去掉不相关特征和冗余特征:
不相关特征(irrelevant features):对问题的解决没有帮助的那些特征(与任务不相关的特征);这些特征的存在对后续模型的学习可能是有害的。
去掉不相关特征可以提高模型的训练速度,可能可以提升模型的效果
冗余特征(redundant features):冗余特征提供的信息与其他特征提供的信息“重复”了,因此去掉这些冗余特征也不会影响模型的学习效果,并且还能加快模型的训练速度。
2. 一些常见的量的定义
其中表示第i个样本,d表示特征数,n表示样本数
表示样本的伪标签矩阵(pseudo label matrix)
-
矩阵中的元素都
,其中
是一个one-hot vector,表示第i个样本属于的簇,
这个样本属于第j个簇
- 伪标签就是我们的无监督算法对样本进行聚类后给每个样本打上的标签,他不是样本真正的标签(ground truth),只是我们算法给样本打的标签
特征子集(feature subset)表示经过我们特征选择算法筛选后得到特征的集合
特征子集矩阵, F的定义如下:
其中m表示要筛选出的特征的数量,表示一个d维的全1向量,s表示是一个d维向量,且s中的元素非0即1. diag(s)的定义如下:
- 对于一个向量u,diag(u)表示一个对角矩阵,且该对角矩阵主对角线上的元素恰为u
- 对于一个方阵U,diag(U)表示一个对角矩阵,且该对角矩阵的主对角线上的元素与U的主对角线上的元素相同
表示s向量中恰有m个值为1,
表示第i个特征要选;
表示第i个特征不选
,通过矩阵运算可以分析得到,矩阵F是由原始数据矩阵仅选取那几行要选的特征得到的矩阵,其余行(不选的特征对应的行)均为0
相似矩阵(similarity matrix)
,其中
表示的是样本
之间的相似性
不同方法中计算相似矩阵的方法也不同。
常用的一种计算相似矩阵的方法是:“高斯核函数方法”(Gaussian kernel)
,其中
是一个超参数,用来确定kernel的敏感性
拉普拉斯矩阵(Laplacian matrix)
给定一个相似矩阵S,则非标准化的图拉普拉斯矩阵(unnormalized graph Laplacian matrix)通过下式定义:
,其中
,是一个对角矩阵,且D的对角线上的元素等于S的每一列的元素之和。
拉普拉斯矩阵的含义:现在常把拉普拉斯矩阵的特征值解释为频率(frequencies),因此那些大的特征值所对应的特征向量往往变动的更加剧烈一些。
假设:
数据中那些最为重要的模式往往变化很小,因此,我们认为拉普拉斯矩阵的那些最小的特征值所对应的特征向量表征了数据的主要结构
上述假设被用于很多流形学习和降维技术的基础
3. 无监督特征选择算法分类
3.1 Filter method
方法:仅使用特征本身的信息,不需要借助任何聚类算法来引导特征的搜索
特点:速度较快,可扩展性强
Filter method是目前世界上科研工作者的主要研究方向
3.2 Wrapper method
方法:使用特定的聚类算法的结果来帮助评估特征子集的优劣,并且指导最优特征子集的搜索
特点:选择出来的特征的应用范围比较局限于“聚类”任务,在聚类任务中,一般来说会取得比较好的结果
由于需要多次使用聚类算法来评估特征,因此模型的计算时间复杂度一般比较大。
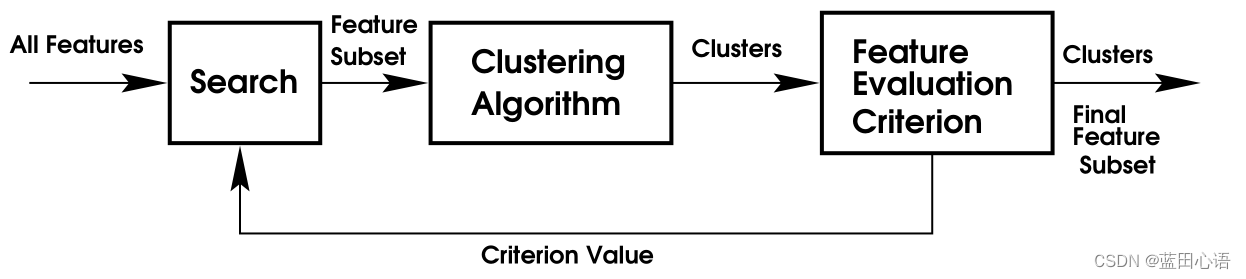
上图中展示了Wrapper方法的框架。其中的三个步骤:Search , Clustering Algorithm,Feature Evaluation Criterion都是可以根据具体需要来选择相应的算法和评价标准
3.3 Embedded method(也叫Hybrid method)
方法:定义一个目标函数,在优化该目标函数的过程中同时完成“特征选择”和“样本的聚类”;
特点:结合上述的Filter method 和 Wrapper method 的优点,是效率和效果的折中、权衡。
4. 主流的特征评价方式
目前有两种主流的无监督特征评价方式:
4.1 考虑某个特定的特征与数据的潜在结构之间的一致性
常见的方式是使用数据的图拉普拉斯矩阵的主导特征向量来表征数据的潜在结构。 当数据是可聚类的时候,可以在拉普拉斯矩阵的主导特征向量的子空间中识别出数据的聚类结构。因此,一种常见的衡量特征与数据的潜在结构之前的一致性的做法是:
求给定的特征与数据的图拉普拉斯矩阵的主导特征向量的内积,这也被称为:拉普拉斯得分(Laplacian score)。拉普拉斯得分往往更倾向于选用那些在拉普拉斯矩阵的主导特征向量的子空间中具有重要地位的特征。
使用Laplacian score方法往往能够帮助我们丢弃掉那些irrelevant features,保留那些relevant features.
4.2 通过衡量一个特征在数据集中载有的信息量
内在逻辑:选取一个特征子集,且该特征子集基本含有了数据集中的所有特征的信息量,那么使用这个特征子集,是比较好的。
因此,一种常见的方法是:搜索到一个特征子集F,通过F能够大致重建数据集中的所有特征
这种方法更加倾向于选择那些与其他很多特征有较强的相关性的特征f,因为有了f,就可以比较容易地重建其他特征了。
5. 讨论与分析
5.1 特征相关性的度量
与监督特征选择、半监督特征选择相比,无监督特征选择问题较为困难的原因在于:
难以定义特征的相关性(i.e. 一个特征的“有用性”,这里的“相关性”指的是“与任务的相关性”)
目前UFS方法来衡量特征相关性的做法主要可以分为以下三类:
(1)通过选取那些可以最好地保留原始数据的流形结构(manifold structure)的特征
(2)通过一些聚类算法来计算一些“聚类指标“(也常称为”伪标签“(pseudo label)),有了这些”伪标签“信息,我们就可以把无监督问题转化为有监督问题了。
(3)基于堆特征之间的相关性(feature dependency)的考量,目标是选取一个特征子集,该特征子集有着最高/最小的相关性。
5.2 特征冗余性的度量
“特征相关性”,除了能用于帮助我们筛选出relevant features,它也能被用来定义feature redundancy(特征冗余性),目前主要有两种方法来量化一个特征子集的特征冗余性:
5.2.1 不考虑客观概念
在这种情况中,目标在于通过统计学/信息学的一些指标来衡量特征间的依赖性、相似性、联系、相关性等
5.2.2 考虑客观概念
目标是要量化特征间的关系
考虑一个特征的任务或某个客观概念,在这个任务 or 概念中一些特征可以被认为是冗余的
6.UFS 方法的评估与比较
现在主要有3种方式来评估UFS方法的效果:
6.1 使用一个无监督/有监督的分类器,在一个具体任务上对UFS方法选择出的特征进行评估。
这种评价方式是目前最为广为使用和接受的,在这类方法中,主要有以下两种具体的做法:
6.1.1 Supervised Settings
使用ACC(分类准确率) 或是err(误差率)在一个监督学习任务中进行评估
具体地,使用UFS选择出的特征子集F,某个监督学习的分类器CL(如KNN,SVM,NB等),CL用F去做有监督的分类任务,并评估分类结果的ACC/err
6.1.2 Unsupervised Settings
使用某个聚类算法(如K-means,EM,COBWEB等)的结果来评估UFS选择出特征的好坏。
常用的评价指标有Normalized Mutual Information(标准化互信息,NMI)、Clustering Accuracy(聚类准确率,AC)
6.2 评估选出的特征的冗余性
这种评价指标是用在那些专门用来消除冗余特征的方法。
常用指标:Redundancy rate(冗余率),Representation Entropy(代表熵)
6.3 评估选出的特征的正确性
常用指标:precision , recall , F-measure
用这些指标来量化衡量选择出的真正与任务相关的特征的数量
常用一些人工合成的数据集来进行验证(因为一般真实的数据集我们无法预先知道哪些特征是真正与任务相关的、有用的)

















 1977
1977

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









