







 本文介绍了如何使用Python标准库difflib中的SequenceMatcher类实现论文和代码的查重,通过比较文本内容的相似度来评估重复性。
本文介绍了如何使用Python标准库difflib中的SequenceMatcher类实现论文和代码的查重,通过比较文本内容的相似度来评估重复性。
说明:仅供学习使用,请勿用于非法用途,若有侵权,请联系博主删除
作者:zhu6201976
一、需求背景
在学术界和编程领域,查重是一项至关重要的任务,它有助于确保学术诚信和代码质量。为了实现这一目标,Python 提供了强大的系统库 difflib 库,可以用来比较文本之间的相似度,并识别可能存在的重复内容。
特殊要求:要求能识别出因人为原因 将一行代码拆分成多行代码 依然能成功检测。
二、difflib基本介绍
difflib 是 Python 的标准库之一,提供了用于比较序列之间差异的功能。它包含多种算法,可以用来比较字符串、文件和数据结构等。difflib 库中最常用的类是 SequenceMatcher,它能够找出两个序列之间的相似性,并生成一个相似性比较报告。
三、实现论文查重
假设我们有两篇论文 A 和 B,我们想要比较它们之间的相似度。我们可以利用 difflib 库中的 SequenceMatcher 类来实现这个功能。首先,我们需要将论文 A 和 B 的内容读取到内存中,然后使用 SequenceMatcher 对象来进行比较。最后,根据比较结果生成一个相似性报告。
示例代码:
import difflib
# 读取论文 A 和 B 的内容
with open('paper_A.txt', 'r') as file:
paper_a_content = file.read()
with open('paper_B.txt', 'r') as file:
paper_b_content = file.read()
# 创建 SequenceMatcher 对象并进行比较
matcher = difflib.SequenceMatcher(None, paper_a_content, paper_b_content)
similarity_ratio = matcher.ratio()
print(f'论文 A 和 B 的相似度为:{similarity_ratio}')
四、实现代码查重
除了论文之外,我们还可以利用 difflib 库来比较代码之间的相似度。假设我们有两个代码文件 X 和 Y,我们想要确定它们之间的相似性。我们可以使用与上述相似的方法来实现代码查重功能。
import difflib
# 读取代码文件 X 和 Y 的内容
with open('code_X.py', 'r', encoding='utf-8') as file:
code_x_content = file.read()
with open('code_Y.py', 'r', encoding='utf-8') as file:
code_y_content = file.read()
# 创建 SequenceMatcher 对象并进行比较
matcher = difflib.SequenceMatcher(None, code_x_content, code_y_content)
similarity_ratio = matcher.ratio()
print(f'代码文件 X 和 Y 的相似度为:{similarity_ratio}')
五、总结说明
本文介绍了一种简单的方法实现论文或代码查重,在实际工作和生活中,还有很多其他优秀的第三方库或算法可实现更加精准的结果,比如引入大模型和语义理解。
运行结果:
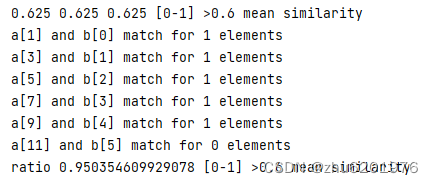
注意:ratio结果大于0.6即标识2篇文章重复率非常高,是相似的。

















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









